 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeViDoRe V3: A Comprehensive Evaluation of Retrieval Augmented Generation in Complex Real-World Scenarios
Jan 13, 2026Retrieval-Augmented Generation (RAG) pipelines must address challenges beyond simple single-document retrieval, such as interpreting visual elements (tables, charts, images), synthesizing information across documents, and providing accurate source grounding. Existing benchmarks fail to capture this complexity, often focusing on textual data, single-document comprehension, or evaluating retrieval and generation in isolation. We introduce ViDoRe v3, a comprehensive multimodal RAG benchmark featuring multi-type queries over visually rich document corpora. It covers 10 datasets across diverse professional domains, comprising ~26,000 document pages paired with 3,099 human-verified queries, each available in 6 languages. Through 12,000 hours of human annotation effort, we provide high-quality annotations for retrieval relevance, bounding box localization, and verified reference answers. Our evaluation of state-of-the-art RAG pipelines reveals that visual retrievers outperform textual ones, late-interaction models and textual reranking substantially improve performance, and hybrid or purely visual contexts enhance answer generation quality. However, current models still struggle with non-textual elements, open-ended queries, and fine-grained visual grounding. To encourage progress in addressing these challenges, the benchmark is released under a commercially permissive license at https://hf.co/vidore.
Context is Gold to find the Gold Passage: Evaluating and Training Contextual Document Embeddings
May 30, 2025A limitation of modern document retrieval embedding methods is that they typically encode passages (chunks) from the same documents independently, often overlooking crucial contextual information from the rest of the document that could greatly improve individual chunk representations. In this work, we introduce ConTEB (Context-aware Text Embedding Benchmark), a benchmark designed to evaluate retrieval models on their ability to leverage document-wide context. Our results show that state-of-the-art embedding models struggle in retrieval scenarios where context is required. To address this limitation, we propose InSeNT (In-sequence Negative Training), a novel contrastive post-training approach which combined with late chunking pooling enhances contextual representation learning while preserving computational efficiency. Our method significantly improves retrieval quality on ConTEB without sacrificing base model performance. We further find chunks embedded with our method are more robust to suboptimal chunking strategies and larger retrieval corpus sizes. We open-source all artifacts at https://github.com/illuin-tech/contextual-embeddings.
GroUSE: A Benchmark to Evaluate Evaluators in Grounded Question Answering
Sep 10, 2024



Retrieval-Augmented Generation (RAG) has emerged as a common paradigm to use Large Language Models (LLMs) alongside private and up-to-date knowledge bases. In this work, we address the challenges of using LLM-as-a-Judge when evaluating grounded answers generated by RAG systems. To assess the calibration and discrimination capabilities of judge models, we identify 7 generator failure modes and introduce GroUSE (Grounded QA Unitary Scoring of Evaluators), a meta-evaluation benchmark of 144 unit tests. This benchmark reveals that existing automated RAG evaluation frameworks often overlook important failure modes, even when using GPT-4 as a judge. To improve on the current design of automated RAG evaluation frameworks, we propose a novel pipeline and find that while closed models perform well on GroUSE, state-of-the-art open-source judges do not generalize to our proposed criteria, despite strong correlation with GPT-4's judgement. Our findings suggest that correlation with GPT-4 is an incomplete proxy for the practical performance of judge models and should be supplemented with evaluations on unit tests for precise failure mode detection. We further show that finetuning Llama-3 on GPT-4's reasoning traces significantly boosts its evaluation capabilities, improving upon both correlation with GPT-4's evaluations and calibration on reference situations.
ColPali: Efficient Document Retrieval with Vision Language Models
Jul 02, 2024Documents are visually rich structures that convey information through text, as well as tables, figures, page layouts, or fonts. While modern document retrieval systems exhibit strong performance on query-to-text matching, they struggle to exploit visual cues efficiently, hindering their performance on practical document retrieval applications such as Retrieval Augmented Generation. To benchmark current systems on visually rich document retrieval, we introduce the Visual Document Retrieval Benchmark ViDoRe, composed of various page-level retrieving tasks spanning multiple domains, languages, and settings. The inherent shortcomings of modern systems motivate the introduction of a new retrieval model architecture, ColPali, which leverages the document understanding capabilities of recent Vision Language Models to produce high-quality contextualized embeddings solely from images of document pages. Combined with a late interaction matching mechanism, ColPali largely outperforms modern document retrieval pipelines while being drastically faster and end-to-end trainable.
CroissantLLM: A Truly Bilingual French-English Language Model
Feb 02, 2024



We introduce CroissantLLM, a 1.3B language model pretrained on a set of 3T English and French tokens, to bring to the research and industrial community a high-performance, fully open-sourced bilingual model that runs swiftly on consumer-grade local hardware. To that end, we pioneer the approach of training an intrinsically bilingual model with a 1:1 English-to-French pretraining data ratio, a custom tokenizer, and bilingual finetuning datasets. We release the training dataset, notably containing a French split with manually curated, high-quality, and varied data sources. To assess performance outside of English, we craft a novel benchmark, FrenchBench, consisting of an array of classification and generation tasks, covering various orthogonal aspects of model performance in the French Language. Additionally, rooted in transparency and to foster further Large Language Model research, we release codebases, and dozens of checkpoints across various model sizes, training data distributions, and training steps, as well as fine-tuned Chat models, and strong translation models. We evaluate our model through the FMTI framework, and validate 81 % of the transparency criteria, far beyond the scores of even most open initiatives. This work enriches the NLP landscape, breaking away from previous English-centric work in order to strengthen our understanding of multilinguality in language models.
Revisiting Instruction Fine-tuned Model Evaluation to Guide Industrial Applications
Oct 21, 2023Instruction Fine-Tuning (IFT) is a powerful paradigm that strengthens the zero-shot capabilities of Large Language Models (LLMs), but in doing so induces new evaluation metric requirements. We show LLM-based metrics to be well adapted to these requirements, and leverage them to conduct an investigation of task-specialization strategies, quantifying the trade-offs that emerge in practical industrial settings. Our findings offer practitioners actionable insights for real-world IFT model deployment.
Improving Next-Application Prediction with Deep Personalized-Attention Neural Network
Nov 09, 2021


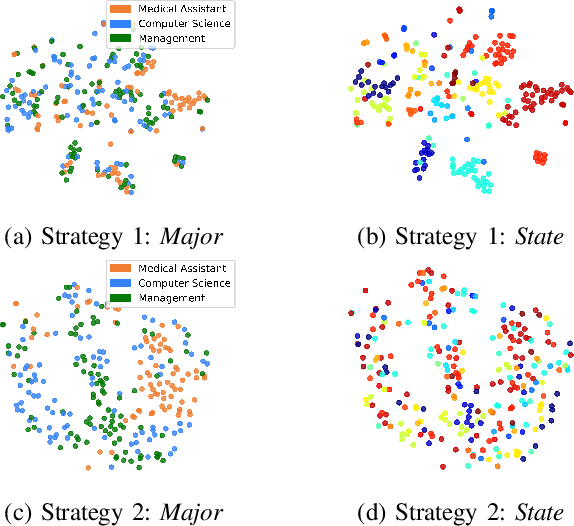
Recently, due to the ubiquity and supremacy of E-recruitment platforms, job recommender systems have been largely studied. In this paper, we tackle the next job application problem, which has many practical applications. In particular, we propose to leverage next-item recommendation approaches to consider better the job seeker's career preference to discover the next relevant job postings (referred to jobs for short) they might apply for. Our proposed model, named Personalized-Attention Next-Application Prediction (PANAP), is composed of three modules. The first module learns job representations from textual content and metadata attributes in an unsupervised way. The second module learns job seeker representations. It includes a personalized-attention mechanism that can adapt the importance of each job in the learned career preference representation to the specific job seeker's profile. The attention mechanism also brings some interpretability to learned representations. Then, the third module models the Next-Application Prediction task as a top-K search process based on the similarity of representations. In addition, the geographic location is an essential factor that affects the preferences of job seekers in the recruitment domain. Therefore, we explore the influence of geographic location on the model performance from the perspective of negative sampling strategies. Experiments on the public CareerBuilder12 dataset show the interest in our approach.
FQuAD2.0: French Question Answering and knowing that you know nothing
Sep 27, 2021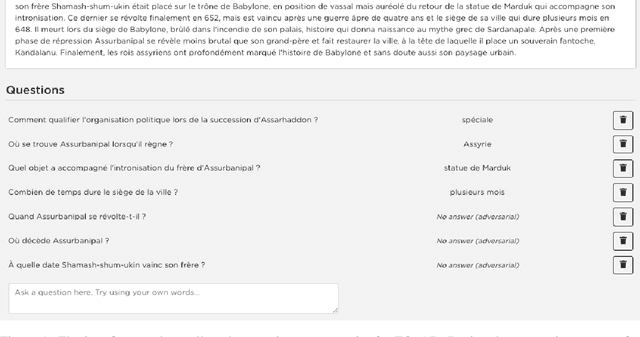
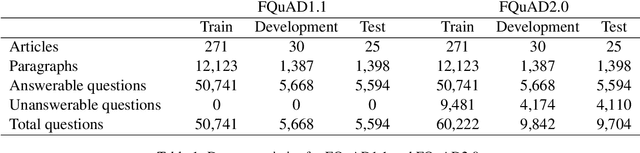

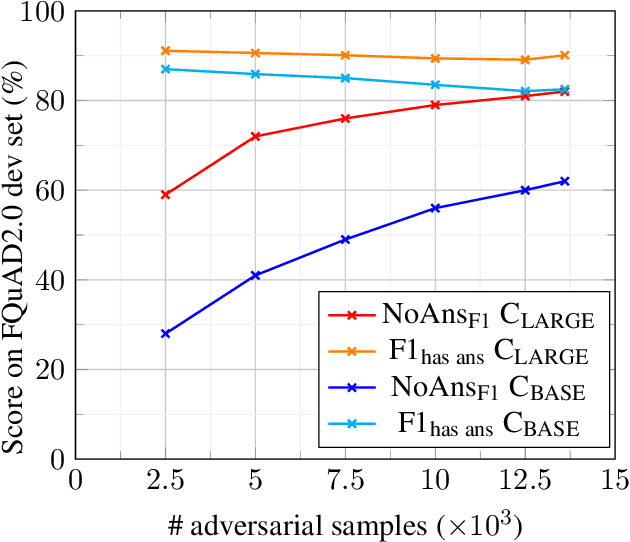
Question Answering, including Reading Comprehension, is one of the NLP research areas that has seen significant scientific breakthroughs over the past few years, thanks to the concomitant advances in Language Modeling. Most of these breakthroughs, however, are centered on the English language. In 2020, as a first strong initiative to bridge the gap to the French language, Illuin Technology introduced FQuAD1.1, a French Native Reading Comprehension dataset composed of 60,000+ questions and answers samples extracted from Wikipedia articles. Nonetheless, Question Answering models trained on this dataset have a major drawback: they are not able to predict when a given question has no answer in the paragraph of interest, therefore making unreliable predictions in various industrial use-cases. In the present work, we introduce FQuAD2.0, which extends FQuAD with 17,000+ unanswerable questions, annotated adversarially, in order to be similar to answerable ones. This new dataset, comprising a total of almost 80,000 questions, makes it possible to train French Question Answering models with the ability of distinguishing unanswerable questions from answerable ones. We benchmark several models with this dataset: our best model, a fine-tuned CamemBERT-large, achieves a F1 score of 82.3% on this classification task, and a F1 score of 83% on the Reading Comprehension task.