 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFQuAD2.0: French Question Answering and knowing that you know nothing
Sep 27, 2021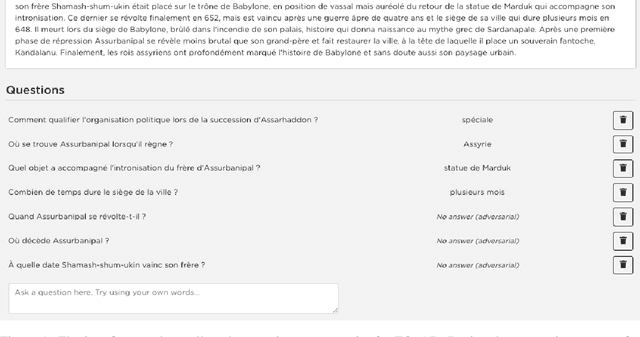
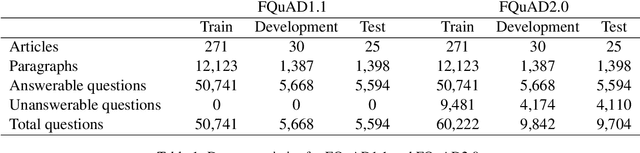

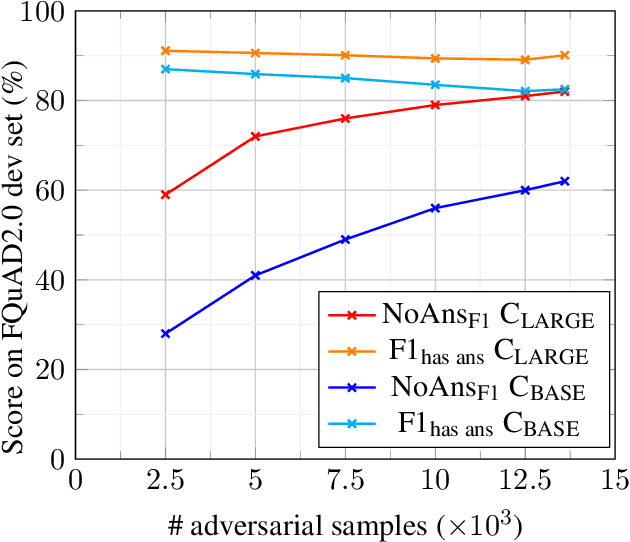
Question Answering, including Reading Comprehension, is one of the NLP research areas that has seen significant scientific breakthroughs over the past few years, thanks to the concomitant advances in Language Modeling. Most of these breakthroughs, however, are centered on the English language. In 2020, as a first strong initiative to bridge the gap to the French language, Illuin Technology introduced FQuAD1.1, a French Native Reading Comprehension dataset composed of 60,000+ questions and answers samples extracted from Wikipedia articles. Nonetheless, Question Answering models trained on this dataset have a major drawback: they are not able to predict when a given question has no answer in the paragraph of interest, therefore making unreliable predictions in various industrial use-cases. In the present work, we introduce FQuAD2.0, which extends FQuAD with 17,000+ unanswerable questions, annotated adversarially, in order to be similar to answerable ones. This new dataset, comprising a total of almost 80,000 questions, makes it possible to train French Question Answering models with the ability of distinguishing unanswerable questions from answerable ones. We benchmark several models with this dataset: our best model, a fine-tuned CamemBERT-large, achieves a F1 score of 82.3% on this classification task, and a F1 score of 83% on the Reading Comprehension task.
Structural analysis of an all-purpose question answering model
Apr 13, 2021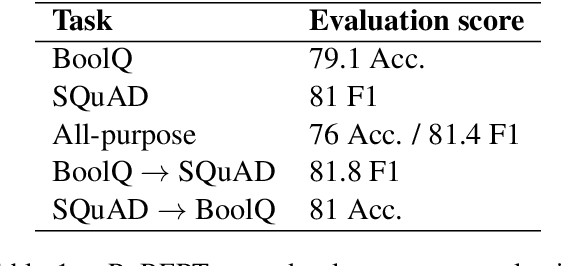
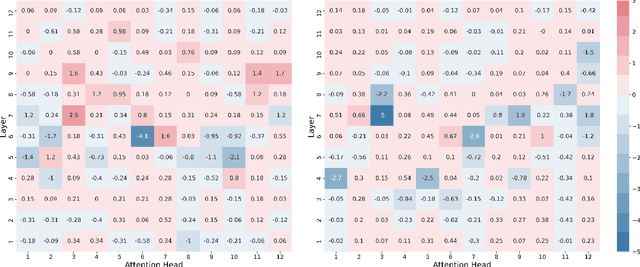
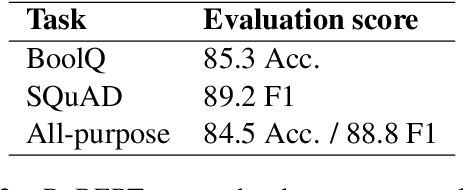
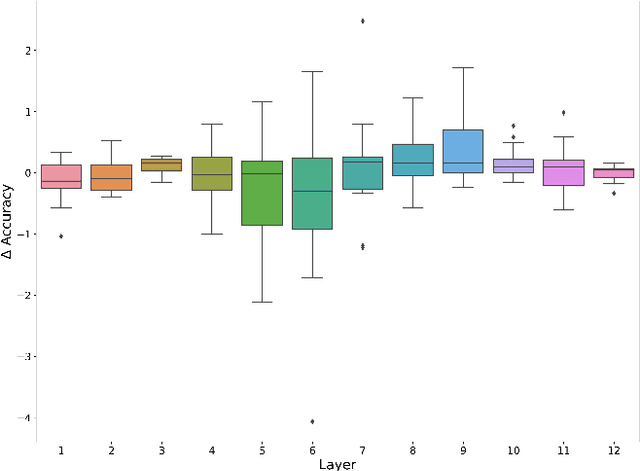
Attention is a key component of the now ubiquitous pre-trained language models. By learning to focus on relevant pieces of information, these Transformer-based architectures have proven capable of tackling several tasks at once and sometimes even surpass their single-task counterparts. To better understand this phenomenon, we conduct a structural analysis of a new all-purpose question answering model that we introduce. Surprisingly, this model retains single-task performance even in the absence of a strong transfer effect between tasks. Through attention head importance scoring, we observe that attention heads specialize in a particular task and that some heads are more conducive to learning than others in both the multi-task and single-task settings.
FQuAD: French Question Answering Dataset
Feb 14, 2020
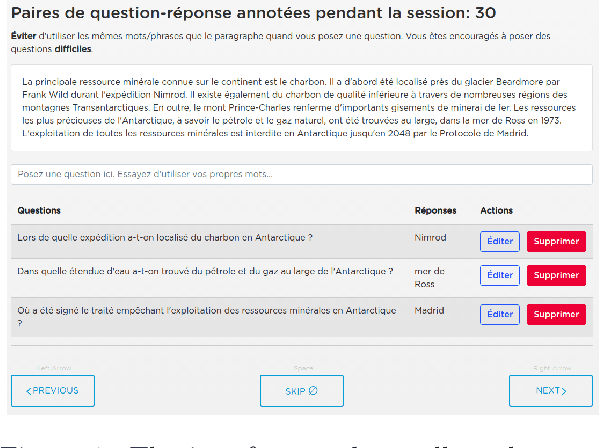
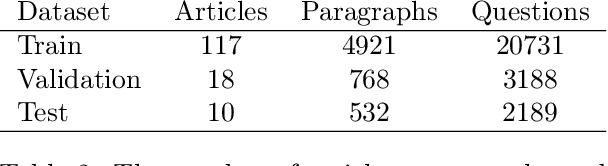

Recent advances in the field of language modeling have improved state-of-the-art results on many Natural Language Processing tasks. Among them, the Machine Reading Comprehension task has made significant progress. However, most of the results are reported in English since labeled resources available in other languages, such as French, remain scarce. In the present work, we introduce the French Question Answering Dataset (FQuAD). FQuAD is French Native Reading Comprehension dataset that consists of 25,000+ questions on a set of Wikipedia articles. A baseline model is trained which achieves an F1 score of 88.0% and an exact match ratio of 77.9% on the test set. The dataset is made freely available at https://fquad.illuin.tech.