 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnd-to-End Trainable Multi-Instance Pose Estimation with Transformers
Mar 22, 2021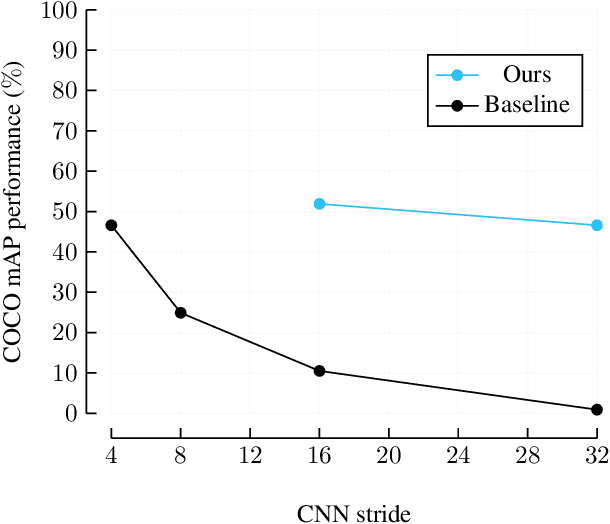
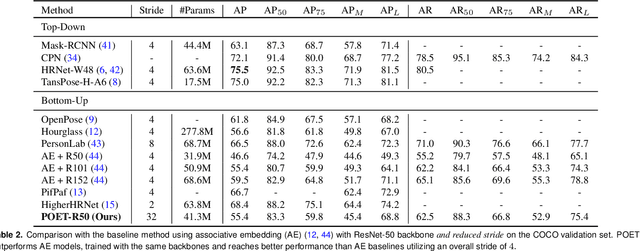
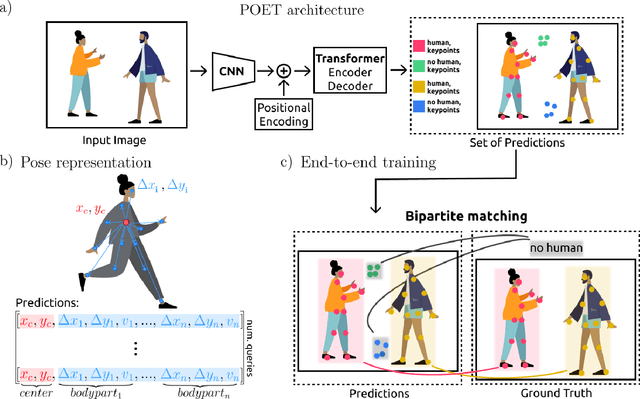

We propose a new end-to-end trainable approach for multi-instance pose estimation by combining a convolutional neural network with a transformer. We cast multi-instance pose estimation from images as a direct set prediction problem. Inspired by recent work on end-to-end trainable object detection with transformers, we use a transformer encoder-decoder architecture together with a bipartite matching scheme to directly regress the pose of all individuals in a given image. Our model, called POse Estimation Transformer (POET), is trained using a novel set-based global loss that consists of a keypoint loss, a keypoint visibility loss, a center loss and a class loss. POET reasons about the relations between detected humans and the full image context to directly predict the poses in parallel. We show that POET can achieve high accuracy on the challenging COCO keypoint detection task. To the best of our knowledge, this model is the first end-to-end trainable multi-instance human pose estimation method.
Perspectives on individual animal identification from biology and computer vision
Feb 28, 2021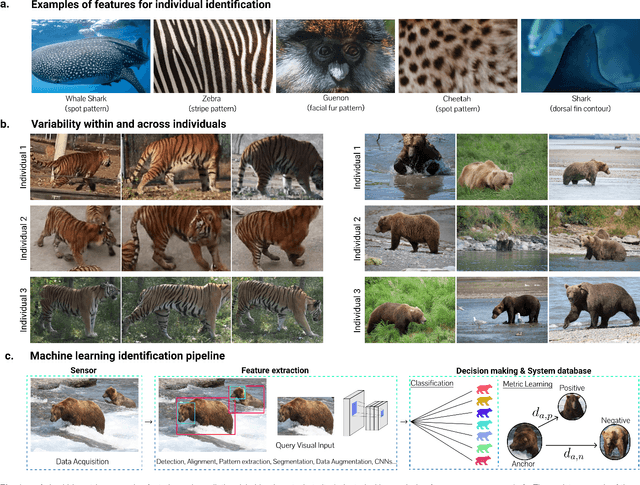
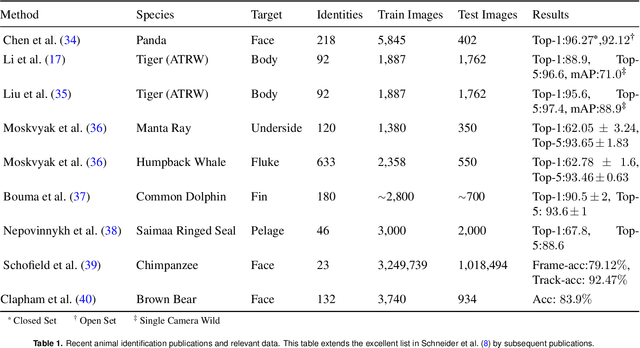
Identifying individual animals is crucial for many biological investigations. In response to some of the limitations of current identification methods, new automated computer vision approaches have emerged with strong performance. Here, we review current advances of computer vision identification techniques to provide both computer scientists and biologists with an overview of the available tools and discuss their applications. We conclude by offering recommendations for starting an animal identification project, illustrate current limitations and propose how they might be addressed in the future.
FQuAD: French Question Answering Dataset
Feb 14, 2020
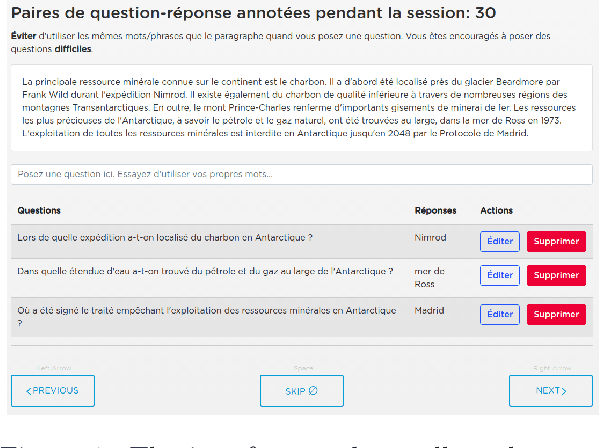
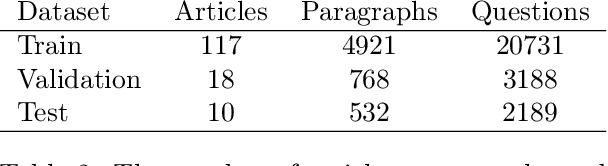

Recent advances in the field of language modeling have improved state-of-the-art results on many Natural Language Processing tasks. Among them, the Machine Reading Comprehension task has made significant progress. However, most of the results are reported in English since labeled resources available in other languages, such as French, remain scarce. In the present work, we introduce the French Question Answering Dataset (FQuAD). FQuAD is French Native Reading Comprehension dataset that consists of 25,000+ questions on a set of Wikipedia articles. A baseline model is trained which achieves an F1 score of 88.0% and an exact match ratio of 77.9% on the test set. The dataset is made freely available at https://fquad.illuin.tech.