 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaptToken: Entropy-based Adaptive Token Selection for MLLM Long Video Understanding
Mar 30, 2026Long video understanding remains challenging for Multi-modal Large Language Models (MLLMs) due to high memory costs and context-length limits. Prior approaches mitigate this by scoring and selecting frames/tokens within short clips, but they lack a principled mechanism to (i) compare relevance across distant video clips and (ii) stop processing once sufficient evidence has been gathered. We propose AdaptToken, a training-free framework that turns an MLLM's self-uncertainty into a global control signal for long-video token selection. AdaptToken splits a video into groups, extracts cross-modal attention to rank tokens within each group, and uses the model's response entropy to estimate each group's prompt relevance. This entropy signal enables a global token budget allocation across groups and further supports early stopping (AdaptToken-Lite), skipping the remaining groups when the model becomes sufficiently certain. Across four long-video benchmarks (VideoMME, LongVideoBench, LVBench, and MLVU) and multiple base MLLMs (7B-72B), AdaptToken consistently improves accuracy (e.g., +6.7 on average over Qwen2.5-VL 7B) and continues to benefit from extremely long inputs (up to 10K frames), while AdaptToken-Lite reduces inference time by about half with comparable performance. Project page: https://haozheqi.github.io/adapt-token
Towards Embodied AI with MuscleMimic: Unlocking full-body musculoskeletal motor learning at scale
Mar 26, 2026Learning motor control for muscle-driven musculoskeletal models is hindered by the computational cost of biomechanically accurate simulation and the scarcity of validated, open full-body models. Here we present MuscleMimic, an open-source framework for scalable motion imitation learning with physiologically realistic, muscle-actuated humanoids. MuscleMimic provides two validated musculoskeletal embodiments - a fixed-root upper-body model (126 muscles) for bimanual manipulation and a full-body model (416 muscles) for locomotion - together with a retargeting pipeline that maps SMPL-format motion capture data onto musculoskeletal structures while preserving kinematic and dynamic consistency. Leveraging massively parallel GPU simulation, the framework achieves order-of-magnitude training speedups over prior CPU-based approaches while maintaining comprehensive collision handling, enabling a single generalist policy to be trained on hundreds of diverse motions within days. The resulting policy faithfully reproduces a broad repertoire of human movements under full muscular control and can be fine-tuned to novel motions within hours. Biomechanical validation against experimental walking and running data demonstrates strong agreement in joint kinematics (mean correlation r = 0.90), while muscle activation analysis reveals both the promise and fundamental challenges of achieving physiological fidelity through kinematic imitation alone. By lowering the computational and data barriers to musculoskeletal simulation, MuscleMimic enables systematic model validation across diverse dynamic movements and broader participation in neuromuscular control research. Code, models, checkpoints, and retargeted datasets are available at: https://github.com/amathislab/musclemimic
Arnold: a generalist muscle transformer policy
Aug 25, 2025

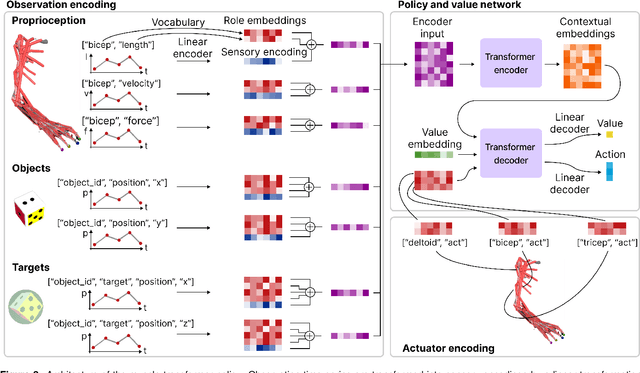

Controlling high-dimensional and nonlinear musculoskeletal models of the human body is a foundational scientific challenge. Recent machine learning breakthroughs have heralded policies that master individual skills like reaching, object manipulation and locomotion in musculoskeletal systems with many degrees of freedom. However, these agents are merely "specialists", achieving high performance for a single skill. In this work, we develop Arnold, a generalist policy that masters multiple tasks and embodiments. Arnold combines behavior cloning and fine-tuning with PPO to achieve expert or super-expert performance in 14 challenging control tasks from dexterous object manipulation to locomotion. A key innovation is Arnold's sensorimotor vocabulary, a compositional representation of the semantics of heterogeneous sensory modalities, objectives, and actuators. Arnold leverages this vocabulary via a transformer architecture to deal with the variable observation and action spaces of each task. This framework supports efficient multi-task, multi-embodiment learning and facilitates rapid adaptation to novel tasks. Finally, we analyze Arnold to provide insights into biological motor control, corroborating recent findings on the limited transferability of muscle synergies across tasks.
LLaVAction: evaluating and training multi-modal large language models for action recognition
Mar 24, 2025Understanding human behavior requires measuring behavioral actions. Due to its complexity, behavior is best mapped onto a rich, semantic structure such as language. The recent development of multi-modal large language models (MLLMs) is a promising candidate for a wide range of action understanding tasks. In this work, we focus on evaluating and then improving MLLMs to perform action recognition. We reformulate EPIC-KITCHENS-100, one of the largest and most challenging egocentric action datasets, to the form of video multiple question answering (EPIC-KITCHENS-100-MQA). We show that when we sample difficult incorrect answers as distractors, leading MLLMs struggle to recognize the correct actions. We propose a series of methods that greatly improve the MLLMs' ability to perform action recognition, achieving state-of-the-art on both the EPIC-KITCHENS-100 validation set, as well as outperforming GPT-4o by 21 points in accuracy on EPIC-KITCHENS-100-MQA. Lastly, we show improvements on other action-related video benchmarks such as EgoSchema, PerceptionTest, LongVideoBench, VideoMME and MVBench, suggesting that MLLMs are a promising path forward for complex action tasks. Code and models are available at: https://github.com/AdaptiveMotorControlLab/LLaVAction.
Reinforcement learning-based motion imitation for physiologically plausible musculoskeletal motor control
Mar 18, 2025How do humans move? The quest to understand human motion has broad applications in numerous fields, ranging from computer animation and motion synthesis to neuroscience, human prosthetics and rehabilitation. Although advances in reinforcement learning (RL) have produced impressive results in capturing human motion using simplified humanoids, controlling physiologically accurate models of the body remains an open challenge. In this work, we present a model-free motion imitation framework (KINESIS) to advance the understanding of muscle-based motor control. Using a musculoskeletal model of the lower body with 80 muscle actuators and 20 DoF, we demonstrate that KINESIS achieves strong imitation performance on 1.9 hours of motion capture data, is controllable by natural language through pre-trained text-to-motion generative models, and can be fine-tuned to carry out high-level tasks such as target goal reaching. Importantly, KINESIS generates muscle activity patterns that correlate well with human EMG activity. The physiological plausibility makes KINESIS a promising model for tackling challenging problems in human motor control theory, which we highlight by investigating Bernstein's redundancy problem in the context of locomotion. Code, videos and benchmarks will be available at https://github.com/amathislab/Kinesis.
PICLe: Pseudo-Annotations for In-Context Learning in Low-Resource Named Entity Detection
Dec 16, 2024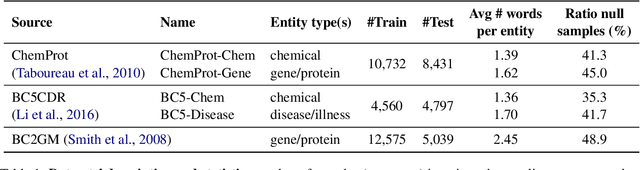
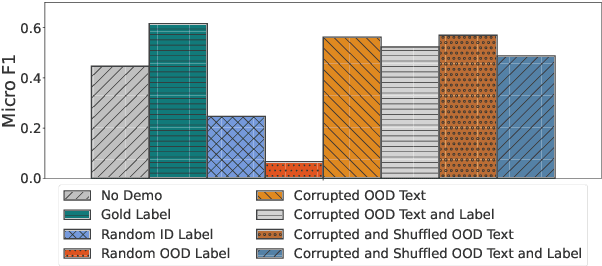

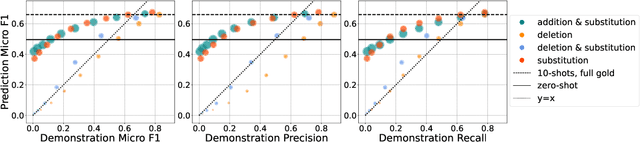
In-context learning (ICL) enables Large Language Models (LLMs) to perform tasks using few demonstrations, facilitating task adaptation when labeled examples are hard to obtain. However, ICL is sensitive to the choice of demonstrations, and it remains unclear which demonstration attributes enable in-context generalization. In this work, we conduct a perturbation study of in-context demonstrations for low-resource Named Entity Detection (NED). Our surprising finding is that in-context demonstrations with partially correct annotated entity mentions can be as effective for task transfer as fully correct demonstrations. Based off our findings, we propose Pseudo-annotated In-Context Learning (PICLe), a framework for in-context learning with noisy, pseudo-annotated demonstrations. PICLe leverages LLMs to annotate many demonstrations in a zero-shot first pass. We then cluster these synthetic demonstrations, sample specific sets of in-context demonstrations from each cluster, and predict entity mentions using each set independently. Finally, we use self-verification to select the final set of entity mentions. We evaluate PICLe on five biomedical NED datasets and show that, with zero human annotation, PICLe outperforms ICL in low-resource settings where limited gold examples can be used as in-context demonstrations.
Could ChatGPT get an Engineering Degree? Evaluating Higher Education Vulnerability to AI Assistants
Aug 07, 2024



AI assistants are being increasingly used by students enrolled in higher education institutions. While these tools provide opportunities for improved teaching and education, they also pose significant challenges for assessment and learning outcomes. We conceptualize these challenges through the lens of vulnerability, the potential for university assessments and learning outcomes to be impacted by student use of generative AI. We investigate the potential scale of this vulnerability by measuring the degree to which AI assistants can complete assessment questions in standard university-level STEM courses. Specifically, we compile a novel dataset of textual assessment questions from 50 courses at EPFL and evaluate whether two AI assistants, GPT-3.5 and GPT-4 can adequately answer these questions. We use eight prompting strategies to produce responses and find that GPT-4 answers an average of 65.8% of questions correctly, and can even produce the correct answer across at least one prompting strategy for 85.1% of questions. When grouping courses in our dataset by degree program, these systems already pass non-project assessments of large numbers of core courses in various degree programs, posing risks to higher education accreditation that will be amplified as these models improve. Our results call for revising program-level assessment design in higher education in light of advances in generative AI.
HOISDF: Constraining 3D Hand-Object Pose Estimation with Global Signed Distance Fields
Feb 26, 2024



Human hands are highly articulated and versatile at handling objects. Jointly estimating the 3D poses of a hand and the object it manipulates from a monocular camera is challenging due to frequent occlusions. Thus, existing methods often rely on intermediate 3D shape representations to increase performance. These representations are typically explicit, such as 3D point clouds or meshes, and thus provide information in the direct surroundings of the intermediate hand pose estimate. To address this, we introduce HOISDF, a Signed Distance Field (SDF) guided hand-object pose estimation network, which jointly exploits hand and object SDFs to provide a global, implicit representation over the complete reconstruction volume. Specifically, the role of the SDFs is threefold: equip the visual encoder with implicit shape information, help to encode hand-object interactions, and guide the hand and object pose regression via SDF-based sampling and by augmenting the feature representations. We show that HOISDF achieves state-of-the-art results on hand-object pose estimation benchmarks (DexYCB and HO3Dv2). Code is available at https://github.com/amathislab/HOISDF
ODEFormer: Symbolic Regression of Dynamical Systems with Transformers
Oct 09, 2023We introduce ODEFormer, the first transformer able to infer multidimensional ordinary differential equation (ODE) systems in symbolic form from the observation of a single solution trajectory. We perform extensive evaluations on two datasets: (i) the existing "Strogatz" dataset featuring two-dimensional systems; (ii) ODEBench, a collection of one- to four-dimensional systems that we carefully curated from the literature to provide a more holistic benchmark. ODEFormer consistently outperforms existing methods while displaying substantially improved robustness to noisy and irregularly sampled observations, as well as faster inference. We release our code, model and benchmark dataset publicly.
AmadeusGPT: a natural language interface for interactive animal behavioral analysis
Jul 10, 2023The process of quantifying and analyzing animal behavior involves translating the naturally occurring descriptive language of their actions into machine-readable code. Yet, codifying behavior analysis is often challenging without deep understanding of animal behavior and technical machine learning knowledge. To limit this gap, we introduce AmadeusGPT: a natural language interface that turns natural language descriptions of behaviors into machine-executable code. Large-language models (LLMs) such as GPT3.5 and GPT4 allow for interactive language-based queries that are potentially well suited for making interactive behavior analysis. However, the comprehension capability of these LLMs is limited by the context window size, which prevents it from remembering distant conversations. To overcome the context window limitation, we implement a novel dual-memory mechanism to allow communication between short-term and long-term memory using symbols as context pointers for retrieval and saving. Concretely, users directly use language-based definitions of behavior and our augmented GPT develops code based on the core AmadeusGPT API, which contains machine learning, computer vision, spatio-temporal reasoning, and visualization modules. Users then can interactively refine results, and seamlessly add new behavioral modules as needed. We benchmark AmadeusGPT and show we can produce state-of-the-art performance on the MABE 2022 behavior challenge tasks. Note, an end-user would not need to write any code to achieve this. Thus, collectively AmadeusGPT presents a novel way to merge deep biological knowledge, large-language models, and core computer vision modules into a more naturally intelligent system. Code and demos can be found at: https://github.com/AdaptiveMotorControlLab/AmadeusGPT.