 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVinaBench: Benchmark for Faithful and Consistent Visual Narratives
Mar 26, 2025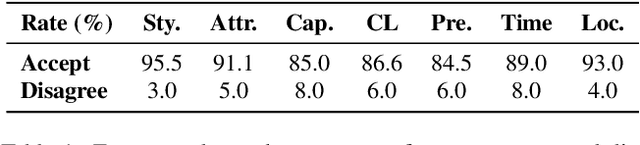
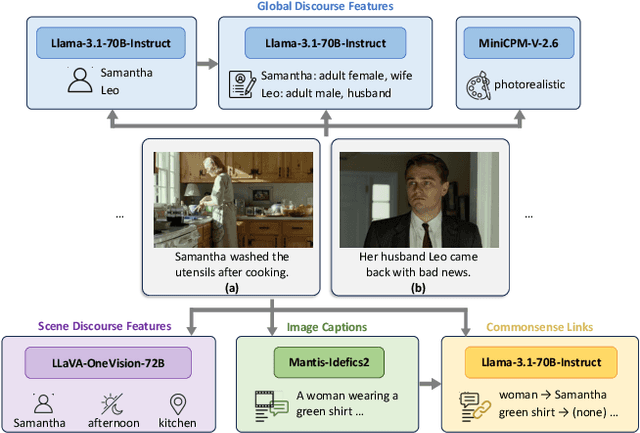
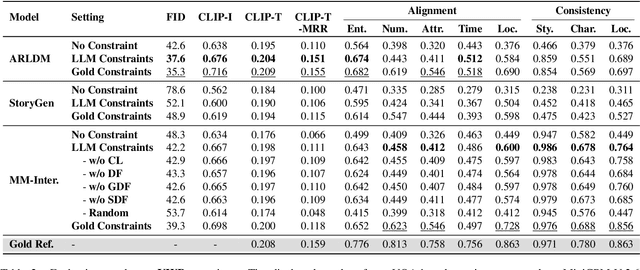
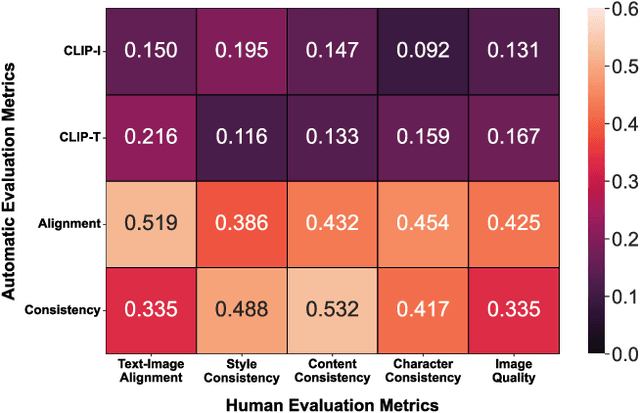
Visual narrative generation transforms textual narratives into sequences of images illustrating the content of the text. However, generating visual narratives that are faithful to the input text and self-consistent across generated images remains an open challenge, due to the lack of knowledge constraints used for planning the stories. In this work, we propose a new benchmark, VinaBench, to address this challenge. Our benchmark annotates the underlying commonsense and discourse constraints in visual narrative samples, offering systematic scaffolds for learning the implicit strategies of visual storytelling. Based on the incorporated narrative constraints, we further propose novel metrics to closely evaluate the consistency of generated narrative images and the alignment of generations with the input textual narrative. Our results across three generative vision models demonstrate that learning with VinaBench's knowledge constraints effectively improves the faithfulness and cohesion of generated visual narratives.
PICLe: Pseudo-Annotations for In-Context Learning in Low-Resource Named Entity Detection
Dec 16, 2024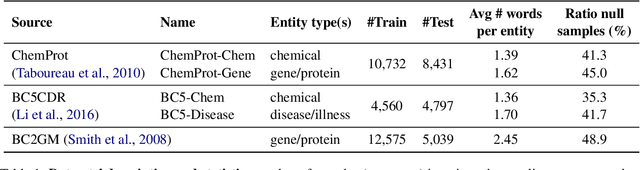
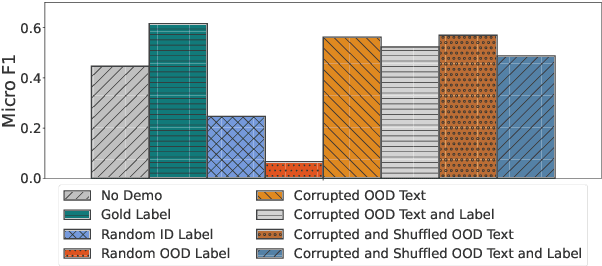

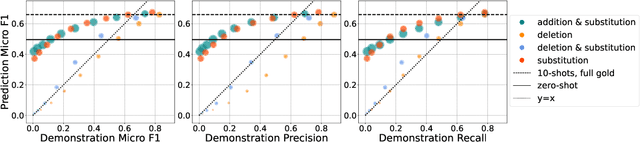
In-context learning (ICL) enables Large Language Models (LLMs) to perform tasks using few demonstrations, facilitating task adaptation when labeled examples are hard to obtain. However, ICL is sensitive to the choice of demonstrations, and it remains unclear which demonstration attributes enable in-context generalization. In this work, we conduct a perturbation study of in-context demonstrations for low-resource Named Entity Detection (NED). Our surprising finding is that in-context demonstrations with partially correct annotated entity mentions can be as effective for task transfer as fully correct demonstrations. Based off our findings, we propose Pseudo-annotated In-Context Learning (PICLe), a framework for in-context learning with noisy, pseudo-annotated demonstrations. PICLe leverages LLMs to annotate many demonstrations in a zero-shot first pass. We then cluster these synthetic demonstrations, sample specific sets of in-context demonstrations from each cluster, and predict entity mentions using each set independently. Finally, we use self-verification to select the final set of entity mentions. We evaluate PICLe on five biomedical NED datasets and show that, with zero human annotation, PICLe outperforms ICL in low-resource settings where limited gold examples can be used as in-context demonstrations.
Could ChatGPT get an Engineering Degree? Evaluating Higher Education Vulnerability to AI Assistants
Aug 07, 2024



AI assistants are being increasingly used by students enrolled in higher education institutions. While these tools provide opportunities for improved teaching and education, they also pose significant challenges for assessment and learning outcomes. We conceptualize these challenges through the lens of vulnerability, the potential for university assessments and learning outcomes to be impacted by student use of generative AI. We investigate the potential scale of this vulnerability by measuring the degree to which AI assistants can complete assessment questions in standard university-level STEM courses. Specifically, we compile a novel dataset of textual assessment questions from 50 courses at EPFL and evaluate whether two AI assistants, GPT-3.5 and GPT-4 can adequately answer these questions. We use eight prompting strategies to produce responses and find that GPT-4 answers an average of 65.8% of questions correctly, and can even produce the correct answer across at least one prompting strategy for 85.1% of questions. When grouping courses in our dataset by degree program, these systems already pass non-project assessments of large numbers of core courses in various degree programs, posing risks to higher education accreditation that will be amplified as these models improve. Our results call for revising program-level assessment design in higher education in light of advances in generative AI.
An Efficient Active Learning Pipeline for Legal Text Classification
Nov 15, 2022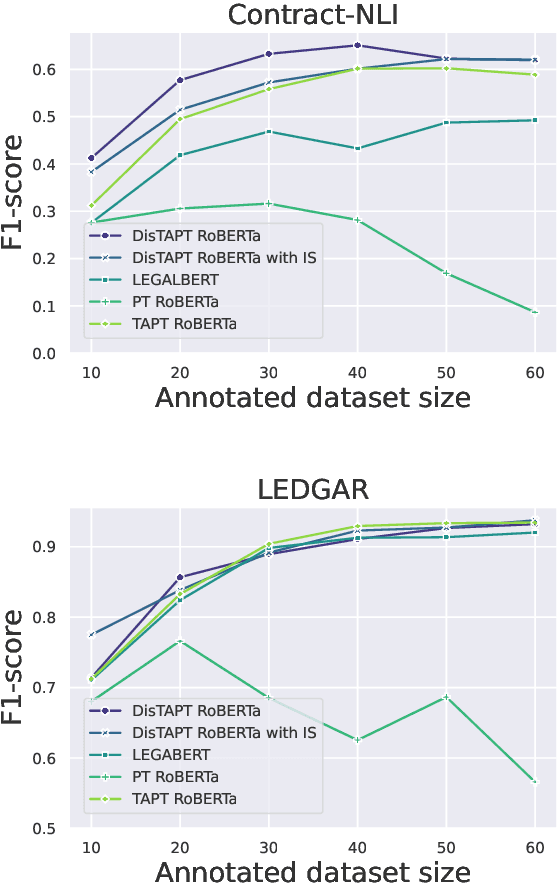
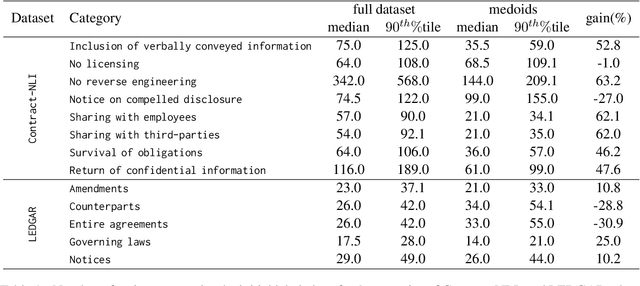
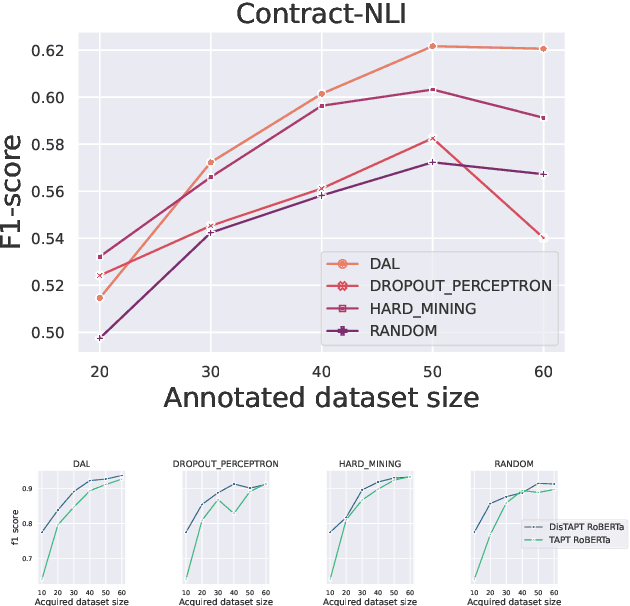
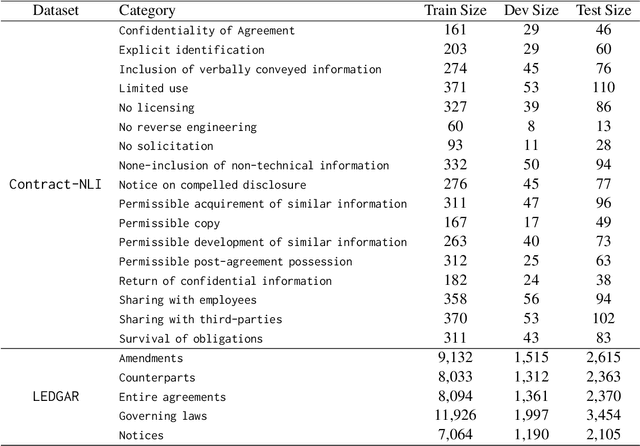
Active Learning (AL) is a powerful tool for learning with less labeled data, in particular, for specialized domains, like legal documents, where unlabeled data is abundant, but the annotation requires domain expertise and is thus expensive. Recent works have shown the effectiveness of AL strategies for pre-trained language models. However, most AL strategies require a set of labeled samples to start with, which is expensive to acquire. In addition, pre-trained language models have been shown unstable during fine-tuning with small datasets, and their embeddings are not semantically meaningful. In this work, we propose a pipeline for effectively using active learning with pre-trained language models in the legal domain. To this end, we leverage the available unlabeled data in three phases. First, we continue pre-training the model to adapt it to the downstream task. Second, we use knowledge distillation to guide the model's embeddings to a semantically meaningful space. Finally, we propose a simple, yet effective, strategy to find the initial set of labeled samples with fewer actions compared to existing methods. Our experiments on Contract-NLI, adapted to the classification task, and LEDGAR benchmarks show that our approach outperforms standard AL strategies, and is more efficient. Furthermore, our pipeline reaches comparable results to the fully-supervised approach with a small performance gap, and dramatically reduced annotation cost. Code and the adapted data will be made available.