 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUsing Large Multimodal Models to Extract Knowledge Components for Knowledge Tracing from Multimedia Question Information
Sep 30, 2024



Knowledge tracing models have enabled a range of intelligent tutoring systems to provide feedback to students. However, existing methods for knowledge tracing in learning sciences are predominantly reliant on statistical data and instructor-defined knowledge components, making it challenging to integrate AI-generated educational content with traditional established methods. We propose a method for automatically extracting knowledge components from educational content using instruction-tuned large multimodal models. We validate this approach by comprehensively evaluating it against knowledge tracing benchmarks in five domains. Our results indicate that the automatically extracted knowledge components can effectively replace human-tagged labels, offering a promising direction for enhancing intelligent tutoring systems in limited-data scenarios, achieving more explainable assessments in educational settings, and laying the groundwork for automated assessment.
Could ChatGPT get an Engineering Degree? Evaluating Higher Education Vulnerability to AI Assistants
Aug 07, 2024



AI assistants are being increasingly used by students enrolled in higher education institutions. While these tools provide opportunities for improved teaching and education, they also pose significant challenges for assessment and learning outcomes. We conceptualize these challenges through the lens of vulnerability, the potential for university assessments and learning outcomes to be impacted by student use of generative AI. We investigate the potential scale of this vulnerability by measuring the degree to which AI assistants can complete assessment questions in standard university-level STEM courses. Specifically, we compile a novel dataset of textual assessment questions from 50 courses at EPFL and evaluate whether two AI assistants, GPT-3.5 and GPT-4 can adequately answer these questions. We use eight prompting strategies to produce responses and find that GPT-4 answers an average of 65.8% of questions correctly, and can even produce the correct answer across at least one prompting strategy for 85.1% of questions. When grouping courses in our dataset by degree program, these systems already pass non-project assessments of large numbers of core courses in various degree programs, posing risks to higher education accreditation that will be amplified as these models improve. Our results call for revising program-level assessment design in higher education in light of advances in generative AI.
A Design Space for Intelligent and Interactive Writing Assistants
Mar 26, 2024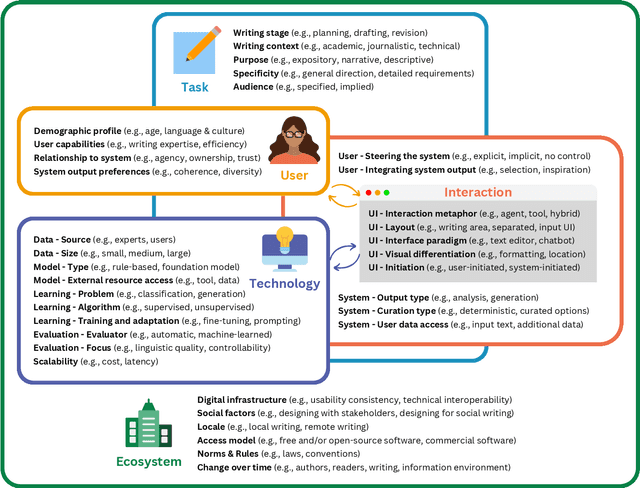
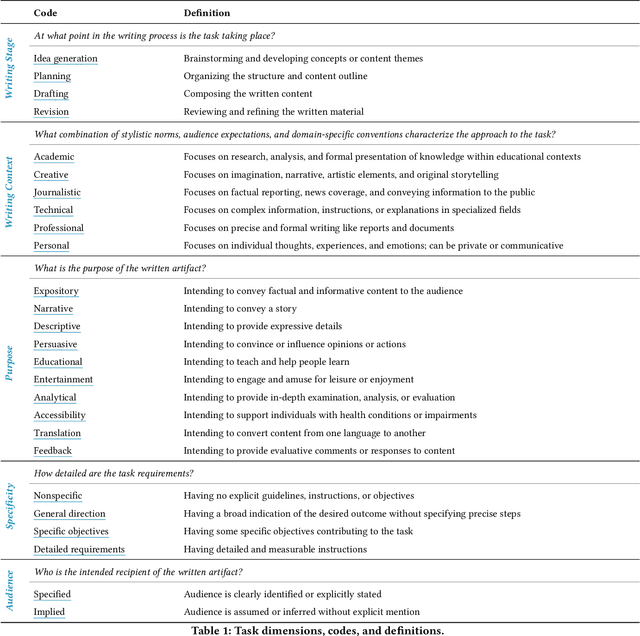
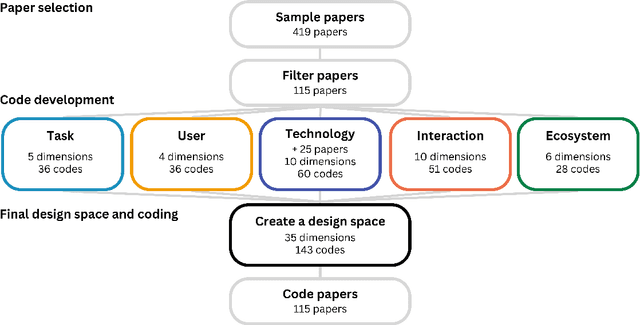
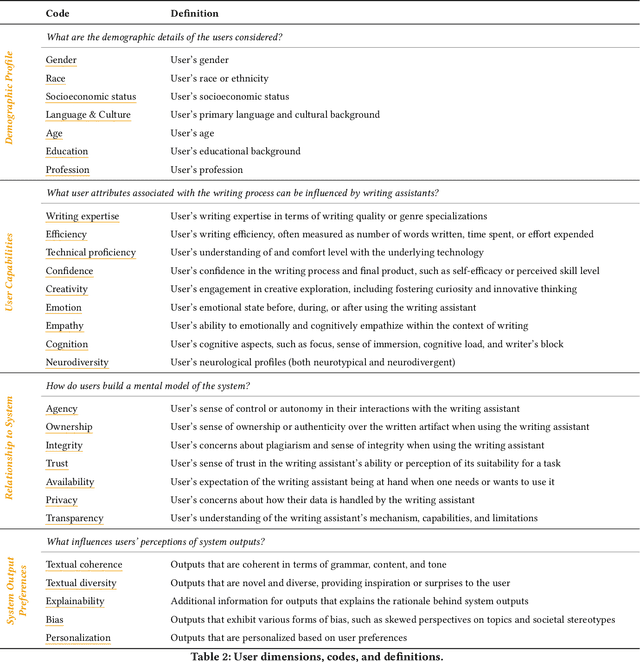
In our era of rapid technological advancement, the research landscape for writing assistants has become increasingly fragmented across various research communities. We seek to address this challenge by proposing a design space as a structured way to examine and explore the multidimensional space of intelligent and interactive writing assistants. Through a large community collaboration, we explore five aspects of writing assistants: task, user, technology, interaction, and ecosystem. Within each aspect, we define dimensions (i.e., fundamental components of an aspect) and codes (i.e., potential options for each dimension) by systematically reviewing 115 papers. Our design space aims to offer researchers and designers a practical tool to navigate, comprehend, and compare the various possibilities of writing assistants, and aid in the envisioning and design of new writing assistants.
The Impact of Quantization on the Robustness of Transformer-based Text Classifiers
Mar 08, 2024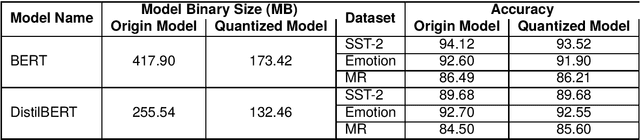

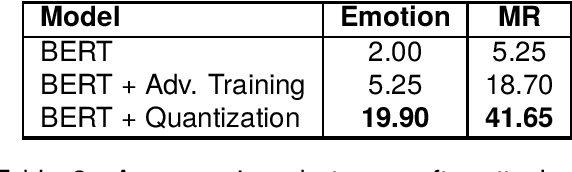
Transformer-based models have made remarkable advancements in various NLP areas. Nevertheless, these models often exhibit vulnerabilities when confronted with adversarial attacks. In this paper, we explore the effect of quantization on the robustness of Transformer-based models. Quantization usually involves mapping a high-precision real number to a lower-precision value, aiming at reducing the size of the model at hand. To the best of our knowledge, this work is the first application of quantization on the robustness of NLP models. In our experiments, we evaluate the impact of quantization on BERT and DistilBERT models in text classification using SST-2, Emotion, and MR datasets. We also evaluate the performance of these models against TextFooler, PWWS, and PSO adversarial attacks. Our findings show that quantization significantly improves (by an average of 18.68%) the adversarial accuracy of the models. Furthermore, we compare the effect of quantization versus that of the adversarial training approach on robustness. Our experiments indicate that quantization increases the robustness of the model by 18.80% on average compared to adversarial training without imposing any extra computational overhead during training. Therefore, our results highlight the effectiveness of quantization in improving the robustness of NLP models.
Unraveling Downstream Gender Bias from Large Language Models: A Study on AI Educational Writing Assistance
Nov 06, 2023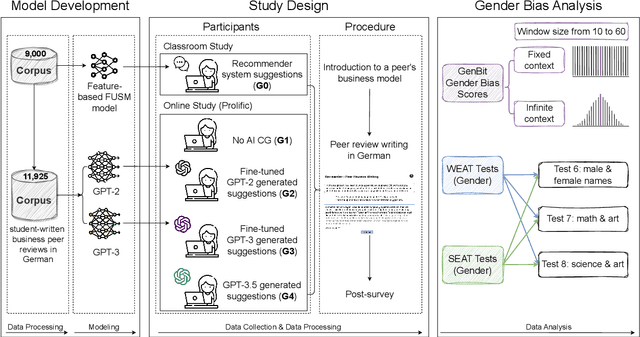
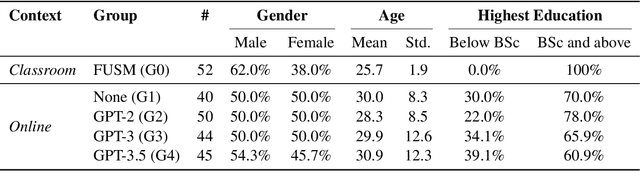
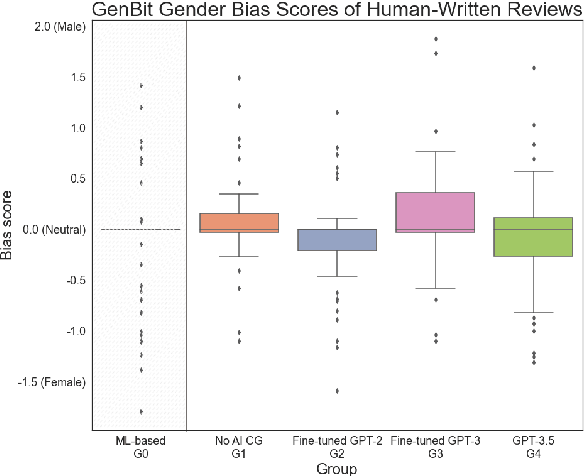
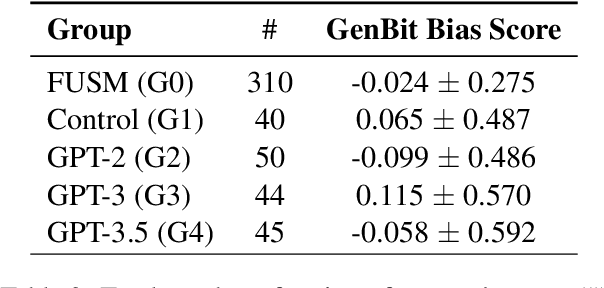
Large Language Models (LLMs) are increasingly utilized in educational tasks such as providing writing suggestions to students. Despite their potential, LLMs are known to harbor inherent biases which may negatively impact learners. Previous studies have investigated bias in models and data representations separately, neglecting the potential impact of LLM bias on human writing. In this paper, we investigate how bias transfers through an AI writing support pipeline. We conduct a large-scale user study with 231 students writing business case peer reviews in German. Students are divided into five groups with different levels of writing support: one classroom group with feature-based suggestions and four groups recruited from Prolific -- a control group with no assistance, two groups with suggestions from fine-tuned GPT-2 and GPT-3 models, and one group with suggestions from pre-trained GPT-3.5. Using GenBit gender bias analysis, Word Embedding Association Tests (WEAT), and Sentence Embedding Association Test (SEAT) we evaluate the gender bias at various stages of the pipeline: in model embeddings, in suggestions generated by the models, and in reviews written by students. Our results demonstrate that there is no significant difference in gender bias between the resulting peer reviews of groups with and without LLM suggestions. Our research is therefore optimistic about the use of AI writing support in the classroom, showcasing a context where bias in LLMs does not transfer to students' responses.