 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Debugging Skills with AI-Powered Assistance: A Real-Time Tool for Debugging Support
Jan 05, 2026Debugging is a crucial skill in programming education and software development, yet it is often overlooked in CS curricula. To address this, we introduce an AI-powered debugging assistant integrated into an IDE. It offers real-time support by analyzing code, suggesting breakpoints, and providing contextual hints. Using RAG with LLMs, program slicing, and custom heuristics, it enhances efficiency by minimizing LLM calls and improving accuracy. A three-level evaluation - technical analysis, UX study, and classroom tests - highlights its potential for teaching debugging.
Do It For Me vs. Do It With Me: Investigating User Perceptions of Different Paradigms of Automation in Copilots for Feature-Rich Software
Apr 22, 2025



Large Language Model (LLM)-based in-application assistants, or copilots, can automate software tasks, but users often prefer learning by doing, raising questions about the optimal level of automation for an effective user experience. We investigated two automation paradigms by designing and implementing a fully automated copilot (AutoCopilot) and a semi-automated copilot (GuidedCopilot) that automates trivial steps while offering step-by-step visual guidance. In a user study (N=20) across data analysis and visual design tasks, GuidedCopilot outperformed AutoCopilot in user control, software utility, and learnability, especially for exploratory and creative tasks, while AutoCopilot saved time for simpler visual tasks. A follow-up design exploration (N=10) enhanced GuidedCopilot with task-and state-aware features, including in-context preview clips and adaptive instructions. Our findings highlight the critical role of user control and tailored guidance in designing the next generation of copilots that enhance productivity, support diverse skill levels, and foster deeper software engagement.
Closing the Loop: Learning to Generate Writing Feedback via Language Model Simulated Student Revisions
Oct 10, 2024Providing feedback is widely recognized as crucial for refining students' writing skills. Recent advances in language models (LMs) have made it possible to automatically generate feedback that is actionable and well-aligned with human-specified attributes. However, it remains unclear whether the feedback generated by these models is truly effective in enhancing the quality of student revisions. Moreover, prompting LMs with a precise set of instructions to generate feedback is nontrivial due to the lack of consensus regarding the specific attributes that can lead to improved revising performance. To address these challenges, we propose PROF that PROduces Feedback via learning from LM simulated student revisions. PROF aims to iteratively optimize the feedback generator by directly maximizing the effectiveness of students' overall revising performance as simulated by LMs. Focusing on an economic essay assignment, we empirically test the efficacy of PROF and observe that our approach not only surpasses a variety of baseline methods in effectiveness of improving students' writing but also demonstrates enhanced pedagogical values, even though it was not explicitly trained for this aspect.
Unraveling Downstream Gender Bias from Large Language Models: A Study on AI Educational Writing Assistance
Nov 06, 2023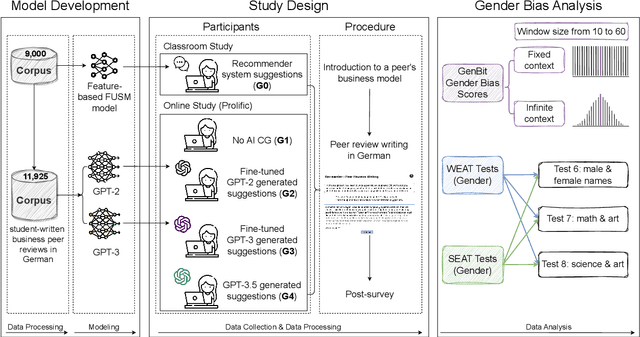
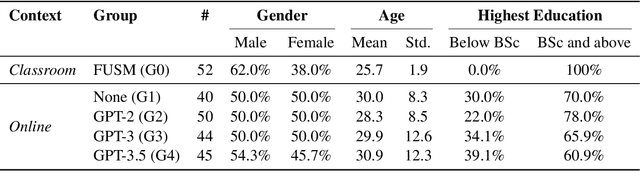
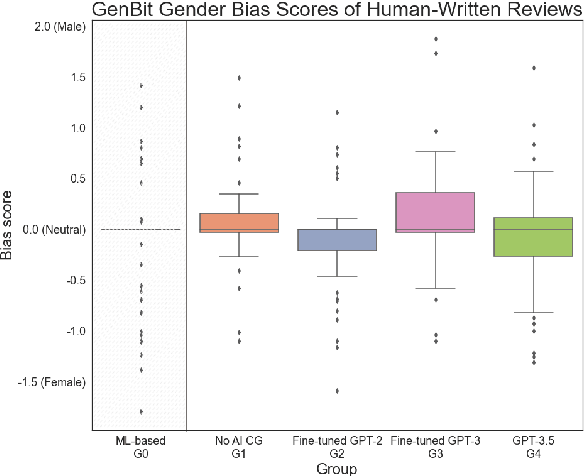
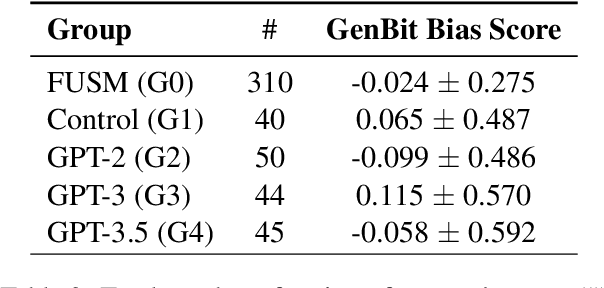
Large Language Models (LLMs) are increasingly utilized in educational tasks such as providing writing suggestions to students. Despite their potential, LLMs are known to harbor inherent biases which may negatively impact learners. Previous studies have investigated bias in models and data representations separately, neglecting the potential impact of LLM bias on human writing. In this paper, we investigate how bias transfers through an AI writing support pipeline. We conduct a large-scale user study with 231 students writing business case peer reviews in German. Students are divided into five groups with different levels of writing support: one classroom group with feature-based suggestions and four groups recruited from Prolific -- a control group with no assistance, two groups with suggestions from fine-tuned GPT-2 and GPT-3 models, and one group with suggestions from pre-trained GPT-3.5. Using GenBit gender bias analysis, Word Embedding Association Tests (WEAT), and Sentence Embedding Association Test (SEAT) we evaluate the gender bias at various stages of the pipeline: in model embeddings, in suggestions generated by the models, and in reviews written by students. Our results demonstrate that there is no significant difference in gender bias between the resulting peer reviews of groups with and without LLM suggestions. Our research is therefore optimistic about the use of AI writing support in the classroom, showcasing a context where bias in LLMs does not transfer to students' responses.