 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSCRIBE: Structured Chain Reasoning for Interactive Behaviour Explanations using Tool Calling
Oct 30, 2025Language models can be used to provide interactive, personalized student feedback in educational settings. However, real-world deployment faces three key challenges: privacy concerns, limited computational resources, and the need for pedagogically valid responses. These constraints require small, open-source models that can run locally and reliably ground their outputs in correct information. We introduce SCRIBE, a framework for multi-hop, tool-augmented reasoning designed to generate valid responses to student questions about feedback reports. SCRIBE combines domain-specific tools with a self-reflective inference pipeline that supports iterative reasoning, tool use, and error recovery. We distil these capabilities into 3B and 8B models via two-stage LoRA fine-tuning on synthetic GPT-4o-generated data. Evaluation with a human-aligned GPT-Judge and a user study with 108 students shows that 8B-SCRIBE models achieve comparable or superior quality to much larger models in key dimensions such as relevance and actionability, while being perceived on par with GPT-4o and Llama-3.3 70B by students. These findings demonstrate the viability of SCRIBE for low-resource, privacy-sensitive educational applications.
A Human-Centric Approach to Explainable AI for Personalized Education
May 28, 2025Deep neural networks form the backbone of artificial intelligence research, with potential to transform the human experience in areas ranging from autonomous driving to personal assistants, healthcare to education. However, their integration into the daily routines of real-world classrooms remains limited. It is not yet common for a teacher to assign students individualized homework targeting their specific weaknesses, provide students with instant feedback, or simulate student responses to a new exam question. While these models excel in predictive performance, this lack of adoption can be attributed to a significant weakness: the lack of explainability of model decisions, leading to a lack of trust from students, parents, and teachers. This thesis aims to bring human needs to the forefront of eXplainable AI (XAI) research, grounded in the concrete use case of personalized learning and teaching. We frame the contributions along two verticals: technical advances in XAI and their aligned human studies. We investigate explainability in AI for education, revealing systematic disagreements between post-hoc explainers and identifying a need for inherently interpretable model architectures. We propose four novel technical contributions in interpretability with a multimodal modular architecture (MultiModN), an interpretable mixture-of-experts model (InterpretCC), adversarial training for explainer stability, and a theory-driven LLM-XAI framework to present explanations to students (iLLuMinaTE), which we evaluate in diverse settings with professors, teachers, learning scientists, and university students. By combining empirical evaluations of existing explainers with novel architectural designs and human studies, our work lays a foundation for human-centric AI systems that balance state-of-the-art performance with built-in transparency and trust.
From Explanations to Action: A Zero-Shot, Theory-Driven LLM Framework for Student Performance Feedback
Sep 12, 2024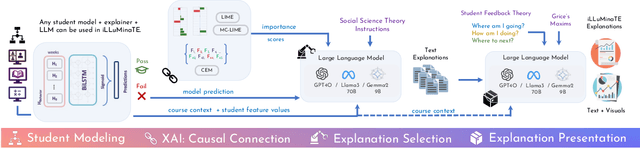
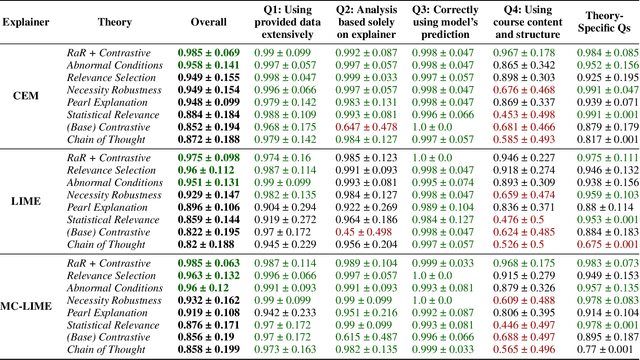
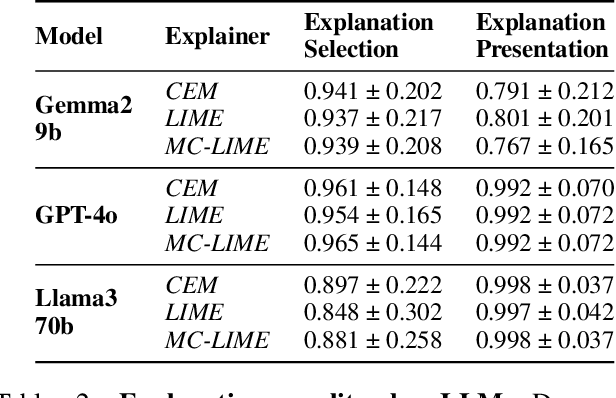
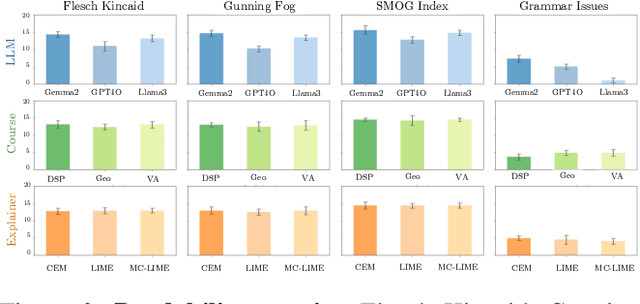
Recent advances in eXplainable AI (XAI) for education have highlighted a critical challenge: ensuring that explanations for state-of-the-art AI models are understandable for non-technical users such as educators and students. In response, we introduce iLLuMinaTE, a zero-shot, chain-of-prompts LLM-XAI pipeline inspired by Miller's cognitive model of explanation. iLLuMinaTE is designed to deliver theory-driven, actionable feedback to students in online courses. iLLuMinaTE navigates three main stages - causal connection, explanation selection, and explanation presentation - with variations drawing from eight social science theories (e.g. Abnormal Conditions, Pearl's Model of Explanation, Necessity and Robustness Selection, Contrastive Explanation). We extensively evaluate 21,915 natural language explanations of iLLuMinaTE extracted from three LLMs (GPT-4o, Gemma2-9B, Llama3-70B), with three different underlying XAI methods (LIME, Counterfactuals, MC-LIME), across students from three diverse online courses. Our evaluation involves analyses of explanation alignment to the social science theory, understandability of the explanation, and a real-world user preference study with 114 university students containing a novel actionability simulation. We find that students prefer iLLuMinaTE explanations over traditional explainers 89.52% of the time. Our work provides a robust, ready-to-use framework for effectively communicating hybrid XAI-driven insights in education, with significant generalization potential for other human-centric fields.
Student Answer Forecasting: Transformer-Driven Answer Choice Prediction for Language Learning
May 30, 2024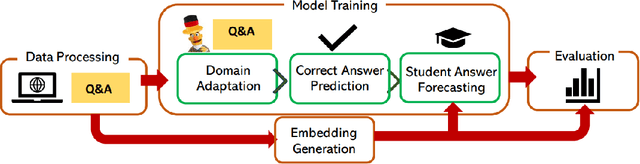
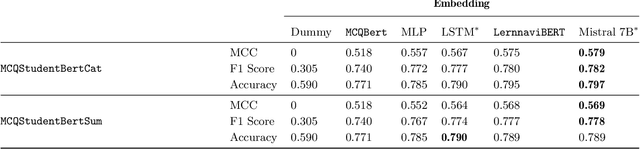
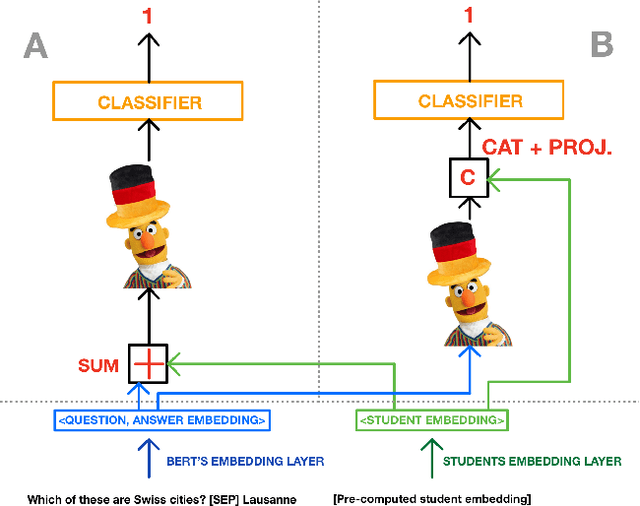
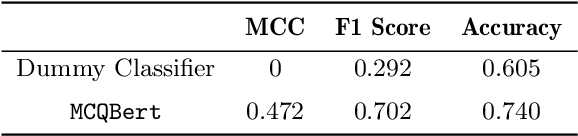
Intelligent Tutoring Systems (ITS) enhance personalized learning by predicting student answers to provide immediate and customized instruction. However, recent research has primarily focused on the correctness of the answer rather than the student's performance on specific answer choices, limiting insights into students' thought processes and potential misconceptions. To address this gap, we present MCQStudentBert, an answer forecasting model that leverages the capabilities of Large Language Models (LLMs) to integrate contextual understanding of students' answering history along with the text of the questions and answers. By predicting the specific answer choices students are likely to make, practitioners can easily extend the model to new answer choices or remove answer choices for the same multiple-choice question (MCQ) without retraining the model. In particular, we compare MLP, LSTM, BERT, and Mistral 7B architectures to generate embeddings from students' past interactions, which are then incorporated into a finetuned BERT's answer-forecasting mechanism. We apply our pipeline to a dataset of language learning MCQ, gathered from an ITS with over 10,000 students to explore the predictive accuracy of MCQStudentBert, which incorporates student interaction patterns, in comparison to correct answer prediction and traditional mastery-learning feature-based approaches. This work opens the door to more personalized content, modularization, and granular support.
InterpretCC: Conditional Computation for Inherently Interpretable Neural Networks
Feb 05, 2024



Real-world interpretability for neural networks is a tradeoff between three concerns: 1) it requires humans to trust the explanation approximation (e.g. post-hoc approaches), 2) it compromises the understandability of the explanation (e.g. automatically identified feature masks), and 3) it compromises the model performance (e.g. decision trees). These shortcomings are unacceptable for human-facing domains, like education, healthcare, or natural language, which require trustworthy explanations, actionable interpretations, and accurate predictions. In this work, we present InterpretCC (interpretable conditional computation), a family of interpretable-by-design neural networks that guarantee human-centric interpretability while maintaining comparable performance to state-of-the-art models by adaptively and sparsely activating features before prediction. We extend this idea into an interpretable mixture-of-experts model, that allows humans to specify topics of interest, discretely separates the feature space for each data point into topical subnetworks, and adaptively and sparsely activates these topical subnetworks. We demonstrate variations of the InterpretCC architecture for text and tabular data across several real-world benchmarks: six online education courses, news classification, breast cancer diagnosis, and review sentiment.
MEDITRON-70B: Scaling Medical Pretraining for Large Language Models
Nov 27, 2023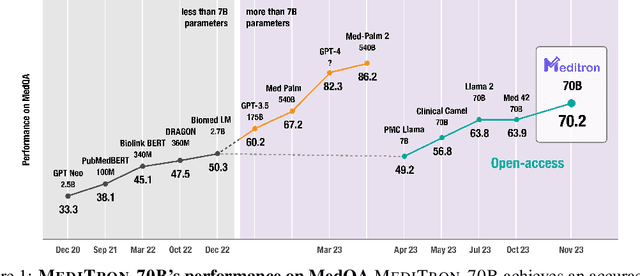
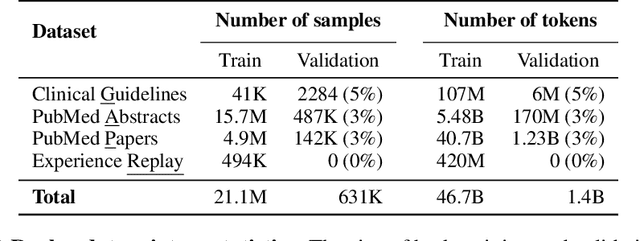
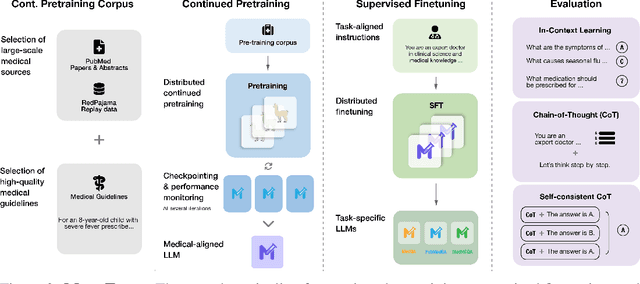

Large language models (LLMs) can potentially democratize access to medical knowledge. While many efforts have been made to harness and improve LLMs' medical knowledge and reasoning capacities, the resulting models are either closed-source (e.g., PaLM, GPT-4) or limited in scale (<= 13B parameters), which restricts their abilities. In this work, we improve access to large-scale medical LLMs by releasing MEDITRON: a suite of open-source LLMs with 7B and 70B parameters adapted to the medical domain. MEDITRON builds on Llama-2 (through our adaptation of Nvidia's Megatron-LM distributed trainer), and extends pretraining on a comprehensively curated medical corpus, including selected PubMed articles, abstracts, and internationally-recognized medical guidelines. Evaluations using four major medical benchmarks show significant performance gains over several state-of-the-art baselines before and after task-specific finetuning. Overall, MEDITRON achieves a 6% absolute performance gain over the best public baseline in its parameter class and 3% over the strongest baseline we finetuned from Llama-2. Compared to closed-source LLMs, MEDITRON-70B outperforms GPT-3.5 and Med-PaLM and is within 5% of GPT-4 and 10% of Med-PaLM-2. We release our code for curating the medical pretraining corpus and the MEDITRON model weights to drive open-source development of more capable medical LLMs.
Unraveling Downstream Gender Bias from Large Language Models: A Study on AI Educational Writing Assistance
Nov 06, 2023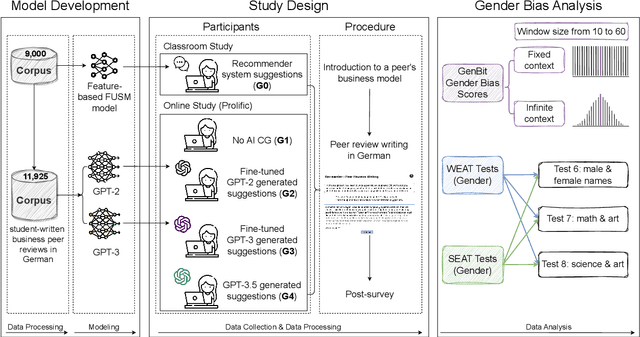
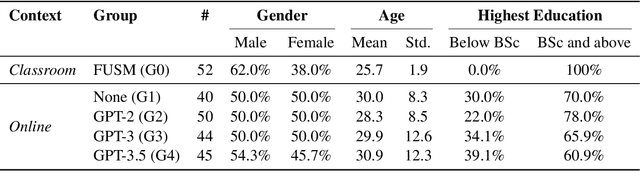
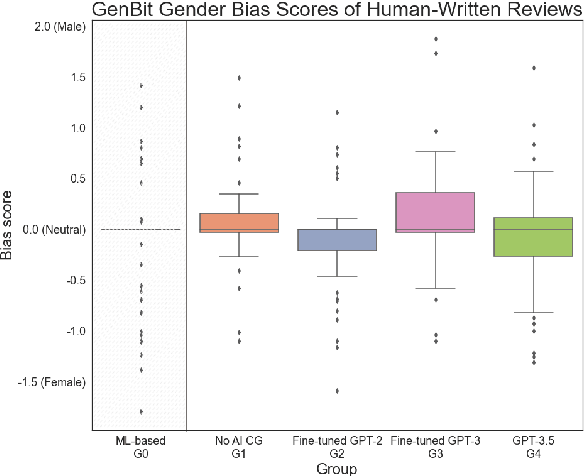
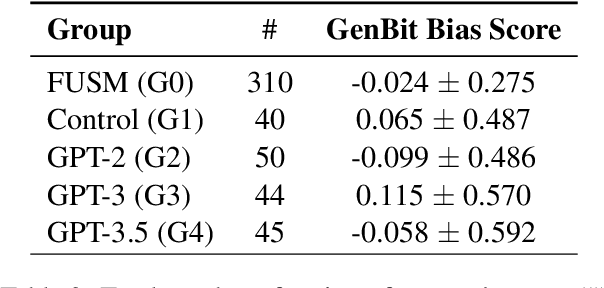
Large Language Models (LLMs) are increasingly utilized in educational tasks such as providing writing suggestions to students. Despite their potential, LLMs are known to harbor inherent biases which may negatively impact learners. Previous studies have investigated bias in models and data representations separately, neglecting the potential impact of LLM bias on human writing. In this paper, we investigate how bias transfers through an AI writing support pipeline. We conduct a large-scale user study with 231 students writing business case peer reviews in German. Students are divided into five groups with different levels of writing support: one classroom group with feature-based suggestions and four groups recruited from Prolific -- a control group with no assistance, two groups with suggestions from fine-tuned GPT-2 and GPT-3 models, and one group with suggestions from pre-trained GPT-3.5. Using GenBit gender bias analysis, Word Embedding Association Tests (WEAT), and Sentence Embedding Association Test (SEAT) we evaluate the gender bias at various stages of the pipeline: in model embeddings, in suggestions generated by the models, and in reviews written by students. Our results demonstrate that there is no significant difference in gender bias between the resulting peer reviews of groups with and without LLM suggestions. Our research is therefore optimistic about the use of AI writing support in the classroom, showcasing a context where bias in LLMs does not transfer to students' responses.
MultiModN- Multimodal, Multi-Task, Interpretable Modular Networks
Sep 25, 2023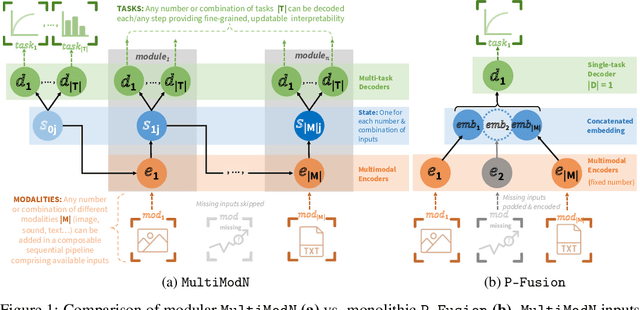

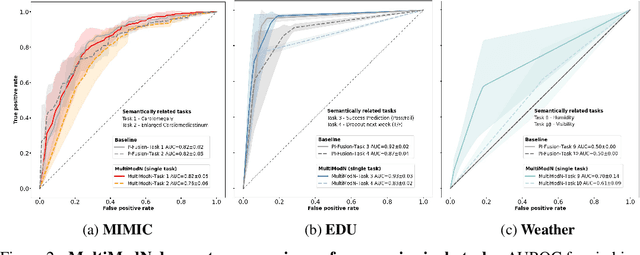

Predicting multiple real-world tasks in a single model often requires a particularly diverse feature space. Multimodal (MM) models aim to extract the synergistic predictive potential of multiple data types to create a shared feature space with aligned semantic meaning across inputs of drastically varying sizes (i.e. images, text, sound). Most current MM architectures fuse these representations in parallel, which not only limits their interpretability but also creates a dependency on modality availability. We present MultiModN, a multimodal, modular network that fuses latent representations in a sequence of any number, combination, or type of modality while providing granular real-time predictive feedback on any number or combination of predictive tasks. MultiModN's composable pipeline is interpretable-by-design, as well as innately multi-task and robust to the fundamental issue of biased missingness. We perform four experiments on several benchmark MM datasets across 10 real-world tasks (predicting medical diagnoses, academic performance, and weather), and show that MultiModN's sequential MM fusion does not compromise performance compared with a baseline of parallel fusion. By simulating the challenging bias of missing not-at-random (MNAR), this work shows that, contrary to MultiModN, parallel fusion baselines erroneously learn MNAR and suffer catastrophic failure when faced with different patterns of MNAR at inference. To the best of our knowledge, this is the first inherently MNAR-resistant approach to MM modeling. In conclusion, MultiModN provides granular insights, robustness, and flexibility without compromising performance.
The future of human-centric eXplainable Artificial Intelligence (XAI) is not post-hoc explanations
Jul 01, 2023Explainable Artificial Intelligence (XAI) plays a crucial role in enabling human understanding and trust in deep learning systems, often defined as determining which features are most important to a model's prediction. As models get larger, more ubiquitous, and pervasive in aspects of daily life, explainability is necessary to avoid or minimize adverse effects of model mistakes. Unfortunately, current approaches in human-centric XAI (e.g. predictive tasks in healthcare, education, or personalized ads) tend to rely on a single explainer. This is a particularly concerning trend when considering that recent work has identified systematic disagreement in explainability methods when applied to the same points and underlying black-box models. In this paper, we therefore present a call for action to address the limitations of current state-of-the-art explainers. We propose to shift from post-hoc explainability to designing interpretable neural network architectures; moving away from approximation techniques in human-centric and high impact applications. We identify five needs of human-centric XAI (real-time, accurate, actionable, human-interpretable, and consistent) and propose two schemes for interpretable-by-design neural network workflows (adaptive routing for interpretable conditional computation and diagnostic benchmarks for iterative model learning). We postulate that the future of human-centric XAI is neither in explaining black-boxes nor in reverting to traditional, interpretable models, but in neural networks that are intrinsically interpretable.
Trusting the Explainers: Teacher Validation of Explainable Artificial Intelligence for Course Design
Dec 26, 2022Deep learning models for learning analytics have become increasingly popular over the last few years; however, these approaches are still not widely adopted in real-world settings, likely due to a lack of trust and transparency. In this paper, we tackle this issue by implementing explainable AI methods for black-box neural networks. This work focuses on the context of online and blended learning and the use case of student success prediction models. We use a pairwise study design, enabling us to investigate controlled differences between pairs of courses. Our analyses cover five course pairs that differ in one educationally relevant aspect and two popular instance-based explainable AI methods (LIME and SHAP). We quantitatively compare the distances between the explanations across courses and methods. We then validate the explanations of LIME and SHAP with 26 semi-structured interviews of university-level educators regarding which features they believe contribute most to student success, which explanations they trust most, and how they could transform these insights into actionable course design decisions. Our results show that quantitatively, explainers significantly disagree with each other about what is important, and qualitatively, experts themselves do not agree on which explanations are most trustworthy. All code, extended results, and the interview protocol are provided at https://github.com/epfl-ml4ed/trusting-explainers.