 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCould ChatGPT get an Engineering Degree? Evaluating Higher Education Vulnerability to AI Assistants
Aug 07, 2024



AI assistants are being increasingly used by students enrolled in higher education institutions. While these tools provide opportunities for improved teaching and education, they also pose significant challenges for assessment and learning outcomes. We conceptualize these challenges through the lens of vulnerability, the potential for university assessments and learning outcomes to be impacted by student use of generative AI. We investigate the potential scale of this vulnerability by measuring the degree to which AI assistants can complete assessment questions in standard university-level STEM courses. Specifically, we compile a novel dataset of textual assessment questions from 50 courses at EPFL and evaluate whether two AI assistants, GPT-3.5 and GPT-4 can adequately answer these questions. We use eight prompting strategies to produce responses and find that GPT-4 answers an average of 65.8% of questions correctly, and can even produce the correct answer across at least one prompting strategy for 85.1% of questions. When grouping courses in our dataset by degree program, these systems already pass non-project assessments of large numbers of core courses in various degree programs, posing risks to higher education accreditation that will be amplified as these models improve. Our results call for revising program-level assessment design in higher education in light of advances in generative AI.
Graph Reasoning for Explainable Cold Start Recommendation
Jun 11, 2024The cold start problem, where new users or items have no interaction history, remains a critical challenge in recommender systems (RS). A common solution involves using Knowledge Graphs (KG) to train entity embeddings or Graph Neural Networks (GNNs). Since KGs incorporate auxiliary data and not just user/item interactions, these methods can make relevant recommendations for cold users or items. Graph Reasoning (GR) methods, however, find paths from users to items to recommend using relations in the KG and, in the context of RS, have been used for interpretability. In this study, we propose GRECS: a framework for adapting GR to cold start recommendations. By utilizing explicit paths starting for users rather than relying only on entity embeddings, GRECS can find items corresponding to users' preferences by navigating the graph, even when limited information about users is available. Our experiments show that GRECS mitigates the cold start problem and outperforms competitive baselines across 5 standard datasets while being explainable. This study highlights the potential of GR for developing explainable recommender systems better suited for managing cold users and items.
Student Answer Forecasting: Transformer-Driven Answer Choice Prediction for Language Learning
May 30, 2024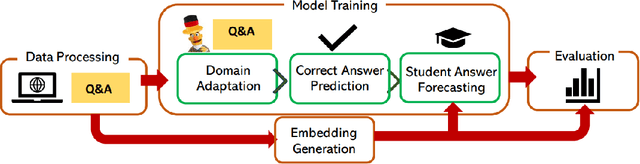
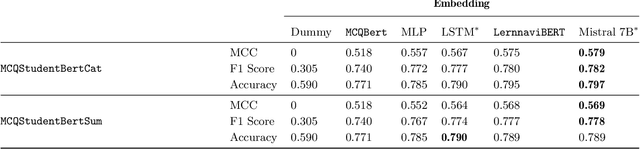
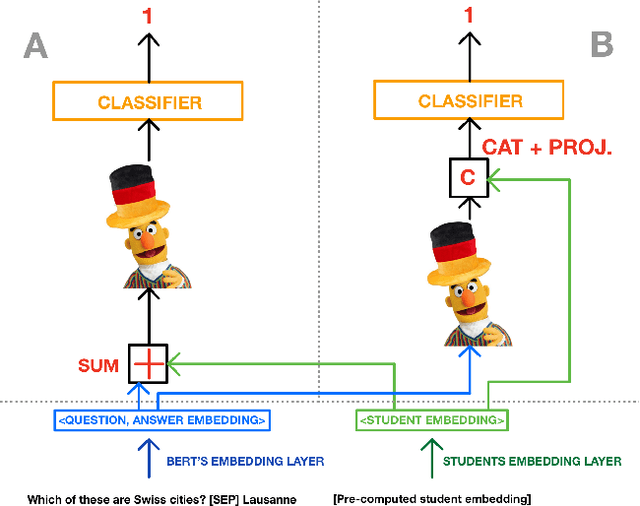
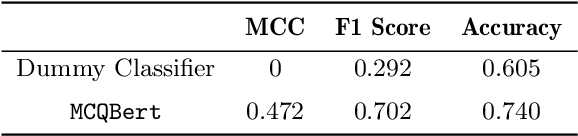
Intelligent Tutoring Systems (ITS) enhance personalized learning by predicting student answers to provide immediate and customized instruction. However, recent research has primarily focused on the correctness of the answer rather than the student's performance on specific answer choices, limiting insights into students' thought processes and potential misconceptions. To address this gap, we present MCQStudentBert, an answer forecasting model that leverages the capabilities of Large Language Models (LLMs) to integrate contextual understanding of students' answering history along with the text of the questions and answers. By predicting the specific answer choices students are likely to make, practitioners can easily extend the model to new answer choices or remove answer choices for the same multiple-choice question (MCQ) without retraining the model. In particular, we compare MLP, LSTM, BERT, and Mistral 7B architectures to generate embeddings from students' past interactions, which are then incorporated into a finetuned BERT's answer-forecasting mechanism. We apply our pipeline to a dataset of language learning MCQ, gathered from an ITS with over 10,000 students to explore the predictive accuracy of MCQStudentBert, which incorporates student interaction patterns, in comparison to correct answer prediction and traditional mastery-learning feature-based approaches. This work opens the door to more personalized content, modularization, and granular support.
Course Recommender Systems Need to Consider the Job Market
Apr 16, 2024



Current course recommender systems primarily leverage learner-course interactions, course content, learner preferences, and supplementary course details like instructor, institution, ratings, and reviews, to make their recommendation. However, these systems often overlook a critical aspect: the evolving skill demand of the job market. This paper focuses on the perspective of academic researchers, working in collaboration with the industry, aiming to develop a course recommender system that incorporates job market skill demands. In light of the job market's rapid changes and the current state of research in course recommender systems, we outline essential properties for course recommender systems to address these demands effectively, including explainable, sequential, unsupervised, and aligned with the job market and user's goals. Our discussion extends to the challenges and research questions this objective entails, including unsupervised skill extraction from job listings, course descriptions, and resumes, as well as predicting recommendations that align with learner objectives and the job market and designing metrics to evaluate this alignment. Furthermore, we introduce an initial system that addresses some existing limitations of course recommender systems using large Language Models (LLMs) for skill extraction and Reinforcement Learning (RL) for alignment with the job market. We provide empirical results using open-source data to demonstrate its effectiveness.
InterpretCC: Conditional Computation for Inherently Interpretable Neural Networks
Feb 05, 2024



Real-world interpretability for neural networks is a tradeoff between three concerns: 1) it requires humans to trust the explanation approximation (e.g. post-hoc approaches), 2) it compromises the understandability of the explanation (e.g. automatically identified feature masks), and 3) it compromises the model performance (e.g. decision trees). These shortcomings are unacceptable for human-facing domains, like education, healthcare, or natural language, which require trustworthy explanations, actionable interpretations, and accurate predictions. In this work, we present InterpretCC (interpretable conditional computation), a family of interpretable-by-design neural networks that guarantee human-centric interpretability while maintaining comparable performance to state-of-the-art models by adaptively and sparsely activating features before prediction. We extend this idea into an interpretable mixture-of-experts model, that allows humans to specify topics of interest, discretely separates the feature space for each data point into topical subnetworks, and adaptively and sparsely activates these topical subnetworks. We demonstrate variations of the InterpretCC architecture for text and tabular data across several real-world benchmarks: six online education courses, news classification, breast cancer diagnosis, and review sentiment.
Finding Paths for Explainable MOOC Recommendation: A Learner Perspective
Dec 11, 2023



The increasing availability of Massive Open Online Courses (MOOCs) has created a necessity for personalized course recommendation systems. These systems often combine neural networks with Knowledge Graphs (KGs) to achieve richer representations of learners and courses. While these enriched representations allow more accurate and personalized recommendations, explainability remains a significant challenge which is especially problematic for certain domains with significant impact such as education and online learning. Recently, a novel class of recommender systems that uses reinforcement learning and graph reasoning over KGs has been proposed to generate explainable recommendations in the form of paths over a KG. Despite their accuracy and interpretability on e-commerce datasets, these approaches have scarcely been applied to the educational domain and their use in practice has not been studied. In this work, we propose an explainable recommendation system for MOOCs that uses graph reasoning. To validate the practical implications of our approach, we conducted a user study examining user perceptions of our new explainable recommendations. We demonstrate the generalizability of our approach by conducting experiments on two educational datasets: COCO and Xuetang.
MultiModN- Multimodal, Multi-Task, Interpretable Modular Networks
Sep 25, 2023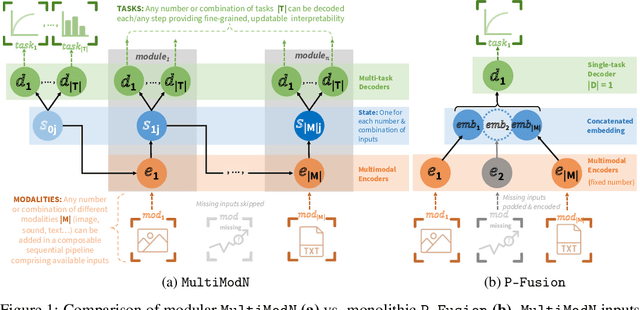

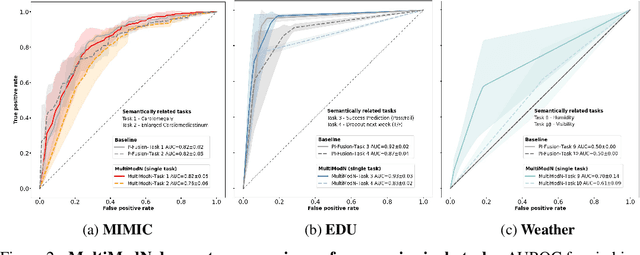

Predicting multiple real-world tasks in a single model often requires a particularly diverse feature space. Multimodal (MM) models aim to extract the synergistic predictive potential of multiple data types to create a shared feature space with aligned semantic meaning across inputs of drastically varying sizes (i.e. images, text, sound). Most current MM architectures fuse these representations in parallel, which not only limits their interpretability but also creates a dependency on modality availability. We present MultiModN, a multimodal, modular network that fuses latent representations in a sequence of any number, combination, or type of modality while providing granular real-time predictive feedback on any number or combination of predictive tasks. MultiModN's composable pipeline is interpretable-by-design, as well as innately multi-task and robust to the fundamental issue of biased missingness. We perform four experiments on several benchmark MM datasets across 10 real-world tasks (predicting medical diagnoses, academic performance, and weather), and show that MultiModN's sequential MM fusion does not compromise performance compared with a baseline of parallel fusion. By simulating the challenging bias of missing not-at-random (MNAR), this work shows that, contrary to MultiModN, parallel fusion baselines erroneously learn MNAR and suffer catastrophic failure when faced with different patterns of MNAR at inference. To the best of our knowledge, this is the first inherently MNAR-resistant approach to MM modeling. In conclusion, MultiModN provides granular insights, robustness, and flexibility without compromising performance.
The future of human-centric eXplainable Artificial Intelligence (XAI) is not post-hoc explanations
Jul 01, 2023Explainable Artificial Intelligence (XAI) plays a crucial role in enabling human understanding and trust in deep learning systems, often defined as determining which features are most important to a model's prediction. As models get larger, more ubiquitous, and pervasive in aspects of daily life, explainability is necessary to avoid or minimize adverse effects of model mistakes. Unfortunately, current approaches in human-centric XAI (e.g. predictive tasks in healthcare, education, or personalized ads) tend to rely on a single explainer. This is a particularly concerning trend when considering that recent work has identified systematic disagreement in explainability methods when applied to the same points and underlying black-box models. In this paper, we therefore present a call for action to address the limitations of current state-of-the-art explainers. We propose to shift from post-hoc explainability to designing interpretable neural network architectures; moving away from approximation techniques in human-centric and high impact applications. We identify five needs of human-centric XAI (real-time, accurate, actionable, human-interpretable, and consistent) and propose two schemes for interpretable-by-design neural network workflows (adaptive routing for interpretable conditional computation and diagnostic benchmarks for iterative model learning). We postulate that the future of human-centric XAI is neither in explaining black-boxes nor in reverting to traditional, interpretable models, but in neural networks that are intrinsically interpretable.
Ripple: Concept-Based Interpretation for Raw Time Series Models in Education
Dec 13, 2022



Time series is the most prevalent form of input data for educational prediction tasks. The vast majority of research using time series data focuses on hand-crafted features, designed by experts for predictive performance and interpretability. However, extracting these features is labor-intensive for humans and computers. In this paper, we propose an approach that utilizes irregular multivariate time series modeling with graph neural networks to achieve comparable or better accuracy with raw time series clickstreams in comparison to hand-crafted features. Furthermore, we extend concept activation vectors for interpretability in raw time series models. We analyze these advances in the education domain, addressing the task of early student performance prediction for downstream targeted interventions and instructional support. Our experimental analysis on 23 MOOCs with millions of combined interactions over six behavioral dimensions show that models designed with our approach can (i) beat state-of-the-art educational time series baselines with no feature extraction and (ii) provide interpretable insights for personalized interventions. Source code: https://github.com/epfl-ml4ed/ripple/.
FlauBERT: Unsupervised Language Model Pre-training for French
Jan 09, 2020
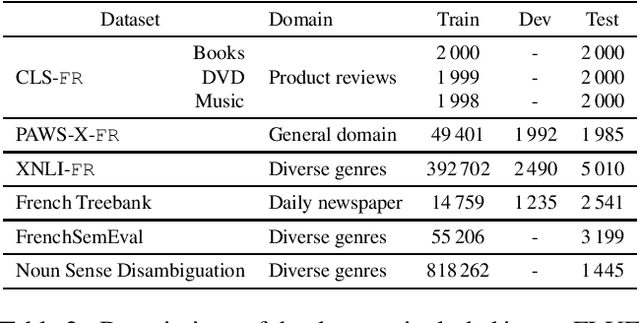
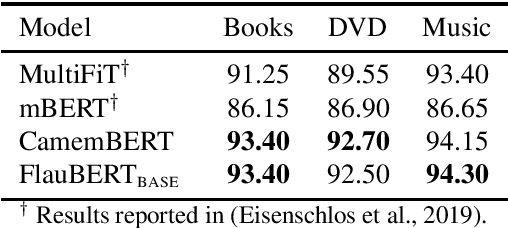

Language models have become a key step to achieve state-of-the art results in many different Natural Language Processing (NLP) tasks. Leveraging the huge amount of unlabeled texts nowadays available, they provide an efficient way to pre-train continuous word representations that can be fine-tuned for a downstream task, along with their contextualization at the sentence level. This has been widely demonstrated for English using contextualized representations (Dai and Le, 2015; Peters et al., 2018; Howard and Ruder, 2018; Radford et al., 2018; Devlin et al., 2019; Yang et al., 2019b). In this paper, we introduce and share FlauBERT, a model learned on a very large and heterogeneous French corpus. Models of different sizes are trained using the new CNRS (French National Centre for Scientific Research) Jean Zay supercomputer. We apply our French language models to diverse NLP tasks (text classification, paraphrasing, natural language inference, parsing, word sense disambiguation) and show that most of the time they outperform other pre-training approaches. Different versions of FlauBERT as well as a unified evaluation protocol for the downstream tasks, called FLUE (French Language Understanding Evaluation), are shared to the research community for further reproducible experiments in French NLP.