 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStructuring versus Problematizing: How LLM-based Agents Scaffold Learning in Diagnostic Reasoning
Apr 10, 2026Supporting students in developing diagnostic reasoning is a key challenge across educational domains. Novices often face cognitive biases such as premature closure and over-reliance on heuristics, and they struggle to transfer diagnostic strategies to new cases. Scenario-based learning (SBL) enhanced by Learning Analytics (LA) and large language models (LLM) offers a promising approach by combining realistic case experiences with personalized scaffolding. Yet, how different scaffolding approaches shape reasoning processes remains insufficiently explored. This study introduces PharmaSim Switch, an SBL environment for pharmacy technician training, extended with an LA- and LLM-powered pharmacist agent that implements pedagogical conversations rooted in two theory-driven scaffolding approaches: \emph{structuring} and \emph{problematizing}, as well as a student learning trajectory. In a between-groups experiment, 63 vocational students completed a learning scenario, a near-transfer scenario, and a far-transfer scenario under one of the two scaffolding conditions. Results indicate that both scaffolding approaches were effective in supporting the use of diagnostic strategies. Performance outcomes were primarily influenced by scenario complexity rather than students' prior knowledge or the scaffolding approach used. The structuring approach was associated with more accurate Active and Interactive participation, whereas problematizing elicited more Constructive engagement. These findings underscore the value of combining scaffolding approaches when designing LA- and LLM-based systems to effectively foster diagnostic reasoning.
* 12 pages, 8 figures. Accepted at LAK 2026
REFINE: Real-world Exploration of Interactive Feedback and Student Behaviour
Mar 31, 2026Formative feedback is central to effective learning, yet providing timely, individualised feedback at scale remains a persistent challenge. While recent work has explored the use of large language models (LLMs) to automate feedback, most existing systems still conceptualise feedback as a static, one-way artifact, offering limited support for interpretation, clarification, or follow-up. In this work, we introduce REFINE, a locally deployable, multi-agent feedback system built on small, open-source LLMs that treats feedback as an interactive process. REFINE combines a pedagogically-grounded feedback generation agent with an LLM-as-a-judge-guided regeneration loop using a human-aligned judge, and a self-reflective tool-calling interactive agent that supports student follow-up questions with context-aware, actionable responses. We evaluate REFINE through controlled experiments and an authentic classroom deployment in an undergraduate computer science course. Automatic evaluations show that judge-guided regeneration significantly improves feedback quality, and that the interactive agent produces efficient, high-quality responses comparable to a state-of-the-art closed-source model. Analysis of real student interactions further reveals distinct engagement patterns and indicates that system-generated feedback systematically steers subsequent student inquiry. Our findings demonstrate the feasibility and effectiveness of multi-agent, tool-augmented feedback systems for scalable, interactive feedback.
SCRIBE: Structured Chain Reasoning for Interactive Behaviour Explanations using Tool Calling
Oct 30, 2025Language models can be used to provide interactive, personalized student feedback in educational settings. However, real-world deployment faces three key challenges: privacy concerns, limited computational resources, and the need for pedagogically valid responses. These constraints require small, open-source models that can run locally and reliably ground their outputs in correct information. We introduce SCRIBE, a framework for multi-hop, tool-augmented reasoning designed to generate valid responses to student questions about feedback reports. SCRIBE combines domain-specific tools with a self-reflective inference pipeline that supports iterative reasoning, tool use, and error recovery. We distil these capabilities into 3B and 8B models via two-stage LoRA fine-tuning on synthetic GPT-4o-generated data. Evaluation with a human-aligned GPT-Judge and a user study with 108 students shows that 8B-SCRIBE models achieve comparable or superior quality to much larger models in key dimensions such as relevance and actionability, while being perceived on par with GPT-4o and Llama-3.3 70B by students. These findings demonstrate the viability of SCRIBE for low-resource, privacy-sensitive educational applications.
Evaluating Trust in AI, Human, and Co-produced Feedback Among Undergraduate Students
Apr 15, 2025As generative AI transforms educational feedback practices, understanding students' perceptions of different feedback providers becomes crucial for effective implementation. This study addresses a critical gap by comparing undergraduate students' trust in AI-generated, human-created, and human-AI co-produced feedback, informing how institutions can adapt feedback practices in this new era. Through a within-subject experiment with 91 participants, we investigated factors predicting students' ability to distinguish between feedback types, perception of feedback quality, and potential biases to AI involvement. Findings revealed that students generally preferred AI and co-produced feedback over human feedback in terms of perceived usefulness and objectivity. Only AI feedback suffered a decline in perceived genuineness when feedback sources were revealed, while co-produced feedback maintained its positive perception. Educational AI experience improved students' ability to identify AI feedback and increased their trust in all feedback types, while general AI experience decreased perceived usefulness and credibility. Male students consistently rated all feedback types as less valuable than their female and non-binary counterparts. These insights inform evidence-based guidelines for integrating AI into higher education feedback systems while addressing trust concerns and fostering AI literacy among students.
Finding Paths for Explainable MOOC Recommendation: A Learner Perspective
Dec 11, 2023



The increasing availability of Massive Open Online Courses (MOOCs) has created a necessity for personalized course recommendation systems. These systems often combine neural networks with Knowledge Graphs (KGs) to achieve richer representations of learners and courses. While these enriched representations allow more accurate and personalized recommendations, explainability remains a significant challenge which is especially problematic for certain domains with significant impact such as education and online learning. Recently, a novel class of recommender systems that uses reinforcement learning and graph reasoning over KGs has been proposed to generate explainable recommendations in the form of paths over a KG. Despite their accuracy and interpretability on e-commerce datasets, these approaches have scarcely been applied to the educational domain and their use in practice has not been studied. In this work, we propose an explainable recommendation system for MOOCs that uses graph reasoning. To validate the practical implications of our approach, we conducted a user study examining user perceptions of our new explainable recommendations. We demonstrate the generalizability of our approach by conducting experiments on two educational datasets: COCO and Xuetang.
Kappa Learning: A New Method for Measuring Similarity Between Educational Items Using Performance Data
Dec 20, 2018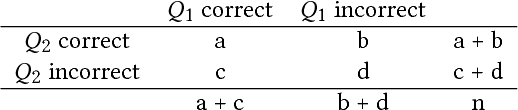
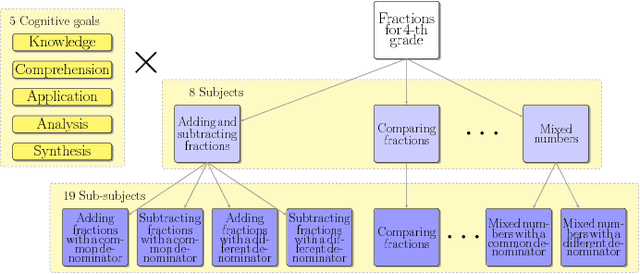
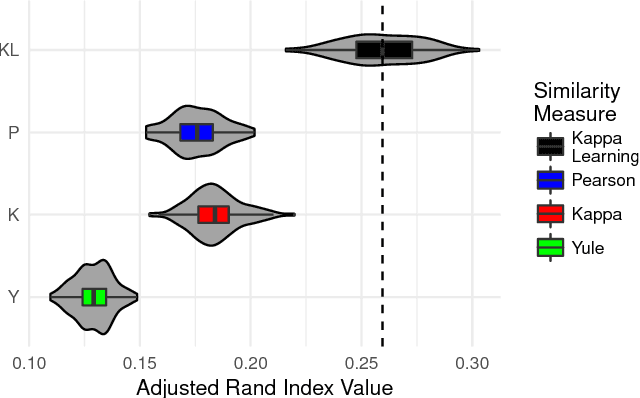

Sequencing items in adaptive learning systems typically relies on a large pool of interactive assessment items (questions) that are analyzed into a hierarchy of skills or Knowledge Components (KCs). Educational data mining techniques can be used to analyze students performance data in order to optimize the mapping of items to KCs. Standard methods that map items into KCs using item-similarity measures make the implicit assumption that students performance on items that depend on the same skill should be similar. This assumption holds if the latent trait (mastery of the underlying skill) is relatively fixed during students activity, as in the context of testing, which is the primary context in which these measures were developed and applied. However, in adaptive learning systems that aim for learning, and address subject matters such as K6 Math that consist of multiple sub-skills, this assumption does not hold. In this paper we propose a new item-similarity measure, termed Kappa Learning (KL), which aims to address this gap. KL identifies similarity between items under the assumption of learning, namely, that learners mastery of the underlying skills changes as they progress through the items. We evaluate Kappa Learning on data from a computerized tutor that teaches Fractions for 4th grade, with experts tagging as ground truth, and on simulated data. Our results show that clustering that is based on Kappa Learning outperforms clustering that is based on commonly used similarity measures (Cohen Kappa, Yule, and Pearson).