 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKappa Learning: A New Method for Measuring Similarity Between Educational Items Using Performance Data
Dec 20, 2018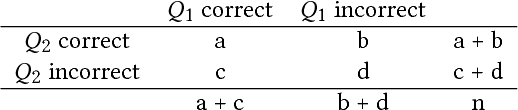
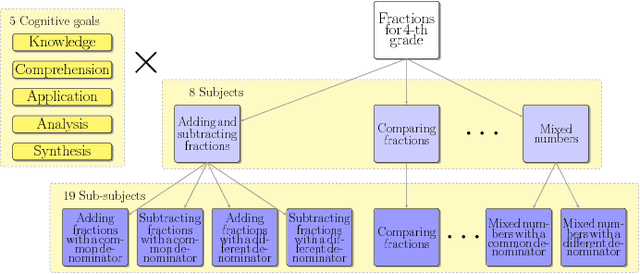
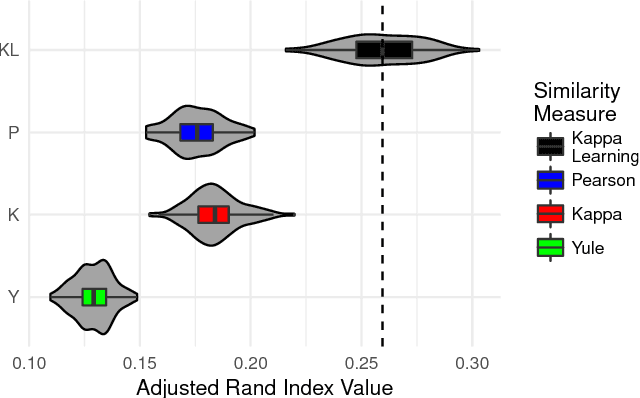

Sequencing items in adaptive learning systems typically relies on a large pool of interactive assessment items (questions) that are analyzed into a hierarchy of skills or Knowledge Components (KCs). Educational data mining techniques can be used to analyze students performance data in order to optimize the mapping of items to KCs. Standard methods that map items into KCs using item-similarity measures make the implicit assumption that students performance on items that depend on the same skill should be similar. This assumption holds if the latent trait (mastery of the underlying skill) is relatively fixed during students activity, as in the context of testing, which is the primary context in which these measures were developed and applied. However, in adaptive learning systems that aim for learning, and address subject matters such as K6 Math that consist of multiple sub-skills, this assumption does not hold. In this paper we propose a new item-similarity measure, termed Kappa Learning (KL), which aims to address this gap. KL identifies similarity between items under the assumption of learning, namely, that learners mastery of the underlying skills changes as they progress through the items. We evaluate Kappa Learning on data from a computerized tutor that teaches Fractions for 4th grade, with experts tagging as ground truth, and on simulated data. Our results show that clustering that is based on Kappa Learning outperforms clustering that is based on commonly used similarity measures (Cohen Kappa, Yule, and Pearson).