 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeApplying IRT to Distinguish Between Human and Generative AI Responses to Multiple-Choice Assessments
Dec 12, 2024Generative AI is transforming the educational landscape, raising significant concerns about cheating. Despite the widespread use of multiple-choice questions in assessments, the detection of AI cheating in MCQ-based tests has been almost unexplored, in contrast to the focus on detecting AI-cheating on text-rich student outputs. In this paper, we propose a method based on the application of Item Response Theory to address this gap. Our approach operates on the assumption that artificial and human intelligence exhibit different response patterns, with AI cheating manifesting as deviations from the expected patterns of human responses. These deviations are modeled using Person-Fit Statistics. We demonstrate that this method effectively highlights the differences between human responses and those generated by premium versions of leading chatbots (ChatGPT, Claude, and Gemini), but that it is also sensitive to the amount of AI cheating in the data. Furthermore, we show that the chatbots differ in their reasoning profiles. Our work provides both a theoretical foundation and empirical evidence for the application of IRT to identify AI cheating in MCQ-based assessments.
Anna Karenina Strikes Again: Pre-Trained LLM Embeddings May Favor High-Performing Learners
Jun 06, 2024Unsupervised clustering of student responses to open-ended questions into behavioral and cognitive profiles using pre-trained LLM embeddings is an emerging technique, but little is known about how well this captures pedagogically meaningful information. We investigate this in the context of student responses to open-ended questions in biology, which were previously analyzed and clustered by experts into theory-driven Knowledge Profiles (KPs). Comparing these KPs to ones discovered by purely data-driven clustering techniques, we report poor discoverability of most KPs, except for the ones including the correct answers. We trace this "discoverability bias" to the representations of KPs in the pre-trained LLM embeddings space.
Kappa Learning: A New Method for Measuring Similarity Between Educational Items Using Performance Data
Dec 20, 2018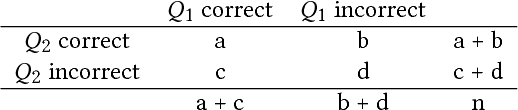
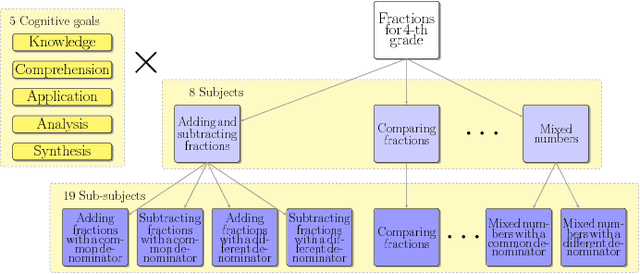
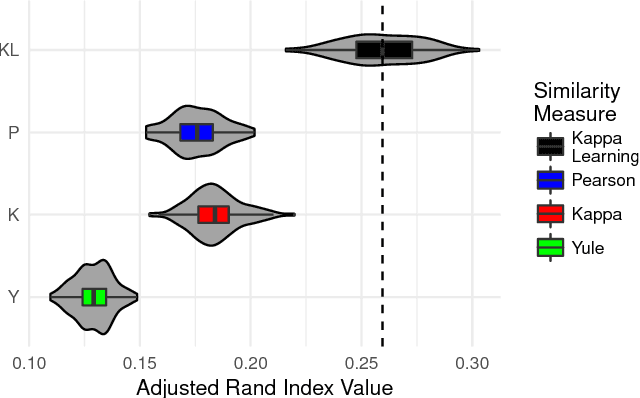

Sequencing items in adaptive learning systems typically relies on a large pool of interactive assessment items (questions) that are analyzed into a hierarchy of skills or Knowledge Components (KCs). Educational data mining techniques can be used to analyze students performance data in order to optimize the mapping of items to KCs. Standard methods that map items into KCs using item-similarity measures make the implicit assumption that students performance on items that depend on the same skill should be similar. This assumption holds if the latent trait (mastery of the underlying skill) is relatively fixed during students activity, as in the context of testing, which is the primary context in which these measures were developed and applied. However, in adaptive learning systems that aim for learning, and address subject matters such as K6 Math that consist of multiple sub-skills, this assumption does not hold. In this paper we propose a new item-similarity measure, termed Kappa Learning (KL), which aims to address this gap. KL identifies similarity between items under the assumption of learning, namely, that learners mastery of the underlying skills changes as they progress through the items. We evaluate Kappa Learning on data from a computerized tutor that teaches Fractions for 4th grade, with experts tagging as ground truth, and on simulated data. Our results show that clustering that is based on Kappa Learning outperforms clustering that is based on commonly used similarity measures (Cohen Kappa, Yule, and Pearson).