 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFinding Paths for Explainable MOOC Recommendation: A Learner Perspective
Dec 11, 2023



The increasing availability of Massive Open Online Courses (MOOCs) has created a necessity for personalized course recommendation systems. These systems often combine neural networks with Knowledge Graphs (KGs) to achieve richer representations of learners and courses. While these enriched representations allow more accurate and personalized recommendations, explainability remains a significant challenge which is especially problematic for certain domains with significant impact such as education and online learning. Recently, a novel class of recommender systems that uses reinforcement learning and graph reasoning over KGs has been proposed to generate explainable recommendations in the form of paths over a KG. Despite their accuracy and interpretability on e-commerce datasets, these approaches have scarcely been applied to the educational domain and their use in practice has not been studied. In this work, we propose an explainable recommendation system for MOOCs that uses graph reasoning. To validate the practical implications of our approach, we conducted a user study examining user perceptions of our new explainable recommendations. We demonstrate the generalizability of our approach by conducting experiments on two educational datasets: COCO and Xuetang.
Assisting Clinical Decisions for Scarcely Available Treatment via Disentangled Latent Representation
Jul 06, 2023



Extracorporeal membrane oxygenation (ECMO) is an essential life-supporting modality for COVID-19 patients who are refractory to conventional therapies. However, the proper treatment decision has been the subject of significant debate and it remains controversial about who benefits from this scarcely available and technically complex treatment option. To support clinical decisions, it is a critical need to predict the treatment need and the potential treatment and no-treatment responses. Targeting this clinical challenge, we propose Treatment Variational AutoEncoder (TVAE), a novel approach for individualized treatment analysis. TVAE is specifically designed to address the modeling challenges like ECMO with strong treatment selection bias and scarce treatment cases. TVAE conceptualizes the treatment decision as a multi-scale problem. We model a patient's potential treatment assignment and the factual and counterfactual outcomes as part of their intrinsic characteristics that can be represented by a deep latent variable model. The factual and counterfactual prediction errors are alleviated via a reconstruction regularization scheme together with semi-supervision, and the selection bias and the scarcity of treatment cases are mitigated by the disentangled and distribution-matched latent space and the label-balancing generative strategy. We evaluate TVAE on two real-world COVID-19 datasets: an international dataset collected from 1651 hospitals across 63 countries, and a institutional dataset collected from 15 hospitals. The results show that TVAE outperforms state-of-the-art treatment effect models in predicting both the propensity scores and factual outcomes on heterogeneous COVID-19 datasets. Additional experiments also show TVAE outperforms the best existing models in individual treatment effect estimation on the synthesized IHDP benchmark dataset.
A Preliminary Approach for Learning Relational Policies for the Management of Critically Ill Children
Jan 13, 2020
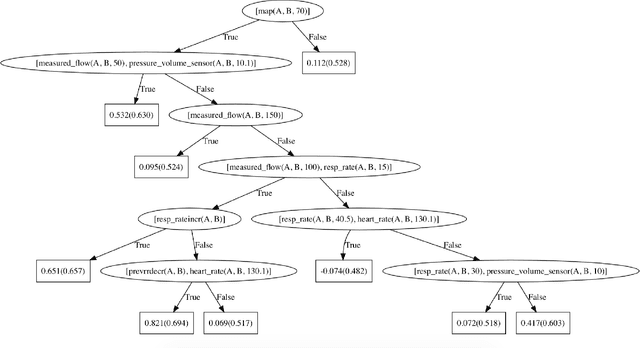


The increased use of electronic health records has made possible the automated extraction of medical policies from patient records to aid in the development of clinical decision support systems. We adapted a boosted Statistical Relational Learning (SRL) framework to learn probabilistic rules from clinical hospital records for the management of physiologic parameters of children with severe cardiac or respiratory failure who were managed with extracorporeal membrane oxygenation. In this preliminary study, the results were promising. In particular, the algorithm returned logic rules for medical actions that are consistent with medical reasoning.
Human-Machine Collaborative Optimization via Apprenticeship Scheduling
May 11, 2018
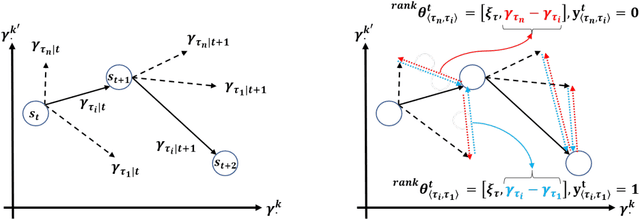

Coordinating agents to complete a set of tasks with intercoupled temporal and resource constraints is computationally challenging, yet human domain experts can solve these difficult scheduling problems using paradigms learned through years of apprenticeship. A process for manually codifying this domain knowledge within a computational framework is necessary to scale beyond the ``single-expert, single-trainee" apprenticeship model. However, human domain experts often have difficulty describing their decision-making processes, causing the codification of this knowledge to become laborious. We propose a new approach for capturing domain-expert heuristics through a pairwise ranking formulation. Our approach is model-free and does not require enumerating or iterating through a large state space. We empirically demonstrate that this approach accurately learns multifaceted heuristics on a synthetic data set incorporating job-shop scheduling and vehicle routing problems, as well as on two real-world data sets consisting of demonstrations of experts solving a weapon-to-target assignment problem and a hospital resource allocation problem. We also demonstrate that policies learned from human scheduling demonstration via apprenticeship learning can substantially improve the efficiency of a branch-and-bound search for an optimal schedule. We employ this human-machine collaborative optimization technique on a variant of the weapon-to-target assignment problem. We demonstrate that this technique generates solutions substantially superior to those produced by human domain experts at a rate up to 9.5 times faster than an optimization approach and can be applied to optimally solve problems twice as complex as those solved by a human demonstrator.
A Multi-Plane Block-Coordinate Frank-Wolfe Algorithm for Training Structural SVMs with a Costly max-Oracle
Nov 18, 2014

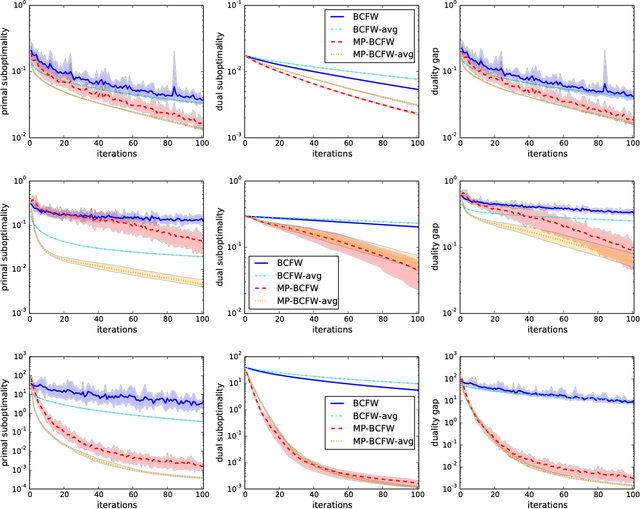
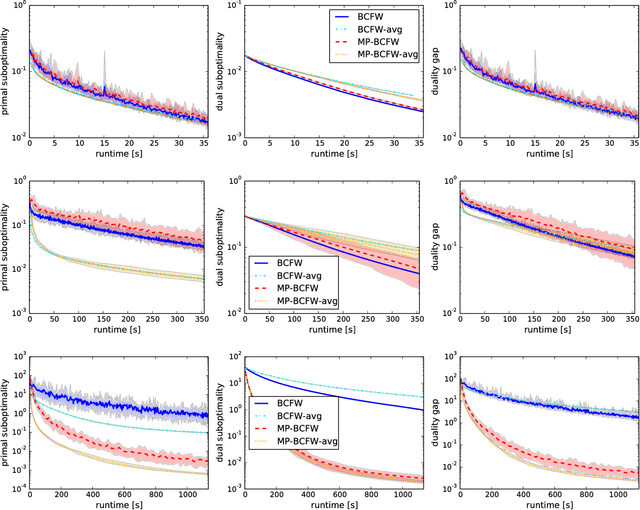
Structural support vector machines (SSVMs) are amongst the best performing models for structured computer vision tasks, such as semantic image segmentation or human pose estimation. Training SSVMs, however, is computationally costly, because it requires repeated calls to a structured prediction subroutine (called \emph{max-oracle}), which has to solve an optimization problem itself, e.g. a graph cut. In this work, we introduce a new algorithm for SSVM training that is more efficient than earlier techniques when the max-oracle is computationally expensive, as it is frequently the case in computer vision tasks. The main idea is to (i) combine the recent stochastic Block-Coordinate Frank-Wolfe algorithm with efficient hyperplane caching, and (ii) use an automatic selection rule for deciding whether to call the exact max-oracle or to rely on an approximate one based on the cached hyperplanes. We show experimentally that this strategy leads to faster convergence to the optimum with respect to the number of requires oracle calls, and that this translates into faster convergence with respect to the total runtime when the max-oracle is slow compared to the other steps of the algorithm. A publicly available C++ implementation is provided at http://pub.ist.ac.at/~vnk/papers/SVM.html .