 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTracing Persona Vectors Through LLM Pretraining
May 13, 2026How large language models internally represent high-level behaviors is a core interpretability question with direct relevance to AI safety: it determines what we can detect, audit, or intervene on. Recent work has shown that traits such as evil or sycophancy correspond to linear directions in the internal activations, the so-called persona vectors. Although these vectors are now routinely utilized to inspect and steer model behavior in safety-relevant settings, how these representations are formed during training remains unknown. To address this gap, we trace persona vectors across the pretraining of OLMo-3-7B, finding that persona vectors form remarkably early -- within 0.22% of OLMo-3 pretraining -- and remain effective for steering the fully post-trained instruct models. Although core representations are formed early on, persona vectors continue to refine geometrically and semantically throughout pretraining. We further compare alternative elicitation strategies and find that all yield effective directions, with each strategy surfacing qualitatively distinct facets of the underlying persona. Replicating our analysis on Apertus-8B reveals that our findings transfer qualitatively beyond OLMo-3. Our results establish persona representations as stable features of early pretraining and open a path to studying how training forms, refines, and shapes them.
Evaluating Answer Leakage Robustness of LLM Tutors against Adversarial Student Attacks
Apr 20, 2026Large Language Models (LLMs) are increasingly used in education, yet their default helpfulness often conflicts with pedagogical principles. Prior work evaluates pedagogical quality via answer leakage-the disclosure of complete solutions instead of scaffolding-but typically assumes well-intentioned learners, leaving tutor robustness under student misuse largely unexplored. In this paper, we study scenarios where students behave adversarially and aim to obtain the correct answer from the tutor. We evaluate a broad set of LLM-based tutor models, including different model families, pedagogically aligned models, and a multi-agent design, under a range of adversarial student attacks. We adapt six groups of adversarial and persuasive techniques to the educational setting and use them to probe how likely a tutor is to reveal the final answer. We evaluate answer leakage robustness using different types of in-context adversarial student agents, finding that they often fail to carry out effective attacks. We therefore introduce an adversarial student agent that we fine-tune to jailbreak LLM-based tutors, which we propose as the core of a standardized benchmark for evaluating tutor robustness. Finally, we present simple but effective defense strategies that reduce answer leakage and strengthen the robustness of LLM-based tutors in adversarial scenarios.
Structuring versus Problematizing: How LLM-based Agents Scaffold Learning in Diagnostic Reasoning
Apr 10, 2026Supporting students in developing diagnostic reasoning is a key challenge across educational domains. Novices often face cognitive biases such as premature closure and over-reliance on heuristics, and they struggle to transfer diagnostic strategies to new cases. Scenario-based learning (SBL) enhanced by Learning Analytics (LA) and large language models (LLM) offers a promising approach by combining realistic case experiences with personalized scaffolding. Yet, how different scaffolding approaches shape reasoning processes remains insufficiently explored. This study introduces PharmaSim Switch, an SBL environment for pharmacy technician training, extended with an LA- and LLM-powered pharmacist agent that implements pedagogical conversations rooted in two theory-driven scaffolding approaches: \emph{structuring} and \emph{problematizing}, as well as a student learning trajectory. In a between-groups experiment, 63 vocational students completed a learning scenario, a near-transfer scenario, and a far-transfer scenario under one of the two scaffolding conditions. Results indicate that both scaffolding approaches were effective in supporting the use of diagnostic strategies. Performance outcomes were primarily influenced by scenario complexity rather than students' prior knowledge or the scaffolding approach used. The structuring approach was associated with more accurate Active and Interactive participation, whereas problematizing elicited more Constructive engagement. These findings underscore the value of combining scaffolding approaches when designing LA- and LLM-based systems to effectively foster diagnostic reasoning.
* 12 pages, 8 figures. Accepted at LAK 2026
Scalable and Explainable Learner-Video Interaction Prediction using Multimodal Large Language Models
Apr 06, 2026Learners' use of video controls in educational videos provides implicit signals of cognitive processing and instructional design quality, yet the lack of scalable and explainable predictive models limits instructors' ability to anticipate such behavior before deployment. We propose a scalable, interpretable pipeline for predicting population-level watching, pausing, skipping, and rewinding behavior as proxies for cognitive load from video content alone. Our approach leverages multimodal large language models (MLLMs) to compute embeddings of short video segments and trains a neural classifier to identify temporally fine-grained interaction peaks. Drawing from multimedia learning theory on instructional design for optimal cognitive load, we code features of the video segments using GPT-5 and employ them as a basis for interpreting model predictions via concept activation vectors. We evaluate our pipeline on 77 million video control events from 66 online courses. Our findings demonstrate that classifiers based on MLLM embeddings reliably predict interaction peaks, generalize to unseen academic fields, and encode interpretable, theory-relevant instructional concepts. Overall, our results show the feasibility of cost-efficient, interpretable pre-screening of educational video design and open new opportunities to empirically examine multimedia learning theory at scale.
REFINE: Real-world Exploration of Interactive Feedback and Student Behaviour
Mar 31, 2026Formative feedback is central to effective learning, yet providing timely, individualised feedback at scale remains a persistent challenge. While recent work has explored the use of large language models (LLMs) to automate feedback, most existing systems still conceptualise feedback as a static, one-way artifact, offering limited support for interpretation, clarification, or follow-up. In this work, we introduce REFINE, a locally deployable, multi-agent feedback system built on small, open-source LLMs that treats feedback as an interactive process. REFINE combines a pedagogically-grounded feedback generation agent with an LLM-as-a-judge-guided regeneration loop using a human-aligned judge, and a self-reflective tool-calling interactive agent that supports student follow-up questions with context-aware, actionable responses. We evaluate REFINE through controlled experiments and an authentic classroom deployment in an undergraduate computer science course. Automatic evaluations show that judge-guided regeneration significantly improves feedback quality, and that the interactive agent produces efficient, high-quality responses comparable to a state-of-the-art closed-source model. Analysis of real student interactions further reveals distinct engagement patterns and indicates that system-generated feedback systematically steers subsequent student inquiry. Our findings demonstrate the feasibility and effectiveness of multi-agent, tool-augmented feedback systems for scalable, interactive feedback.
Moving Beyond Review: Applying Language Models to Planning and Translation in Reflection
Mar 30, 2026Reflective writing is known to support the development of students' metacognitive skills, yet learners often struggle to engage in deep reflection, limiting learning gains. Although large language models (LLMs) have been shown to improve writing skills, their use as conversational agents for reflective writing has produced mixed results and has largely focused on providing feedback on reflective texts, rather than support during planning and organizing. In this paper, inspired by the Cognitive Process Theory of writing (CPT), we propose the first application of LLMs to the planning and translation steps of reflective writing. We introduce Pensée, a tool to explore the effects of explicit AI support during these stages by scaffolding structured reflection planning using a conversational agent, and supporting translation by automatically extracting key concepts. We evaluate Pensée in a controlled between-subjects experiment (N=93), manipulating AI support across writing phases. Results show significantly greater reflection depth and structural quality when learners receive support during planning and translation stages of CPT, though these effects reduce in a delayed post-test. Analyses of learner behavior and perceptions further illustrate how CPT-aligned conversational support shapes reflection processes and learner experience, contributing empirical evidence for theory-driven uses of LLMs in AI-supported reflective writing.
Beyond Holistic Scores: Automatic Trait-Based Quality Scoring of Argumentative Essays
Feb 04, 2026Automated Essay Scoring systems have traditionally focused on holistic scores, limiting their pedagogical usefulness, especially in the case of complex essay genres such as argumentative writing. In educational contexts, teachers and learners require interpretable, trait-level feedback that aligns with instructional goals and established rubrics. In this paper, we study trait-based Automatic Argumentative Essay Scoring using two complementary modeling paradigms designed for realistic educational deployment: (1) structured in-context learning with small open-source LLMs, and (2) a supervised, encoder-based BigBird model with a CORAL-style ordinal regression formulation, optimized for long-sequence understanding. We conduct a systematic evaluation on the ASAP++ dataset, which includes essay scores across five quality traits, offering strong coverage of core argumentation dimensions. LLMs are prompted with designed, rubric-aligned in-context examples, along with feedback and confidence requests, while we explicitly model ordinality in scores with the BigBird model via the rank-consistent CORAL framework. Our results show that explicitly modeling score ordinality substantially improves agreement with human raters across all traits, outperforming LLMs and nominal classification and regression-based baselines. This finding reinforces the importance of aligning model objectives with rubric semantics for educational assessment. At the same time, small open-source LLMs achieve a competitive performance without task-specific fine-tuning, particularly for reasoning-oriented traits, while enabling transparent, privacy-preserving, and locally deployable assessment scenarios. Our findings provide methodological, modeling, and practical insights for the design of AI-based educational systems that aim to deliver interpretable, rubric-aligned feedback for argumentative writing.
SCRIBE: Structured Chain Reasoning for Interactive Behaviour Explanations using Tool Calling
Oct 30, 2025Language models can be used to provide interactive, personalized student feedback in educational settings. However, real-world deployment faces three key challenges: privacy concerns, limited computational resources, and the need for pedagogically valid responses. These constraints require small, open-source models that can run locally and reliably ground their outputs in correct information. We introduce SCRIBE, a framework for multi-hop, tool-augmented reasoning designed to generate valid responses to student questions about feedback reports. SCRIBE combines domain-specific tools with a self-reflective inference pipeline that supports iterative reasoning, tool use, and error recovery. We distil these capabilities into 3B and 8B models via two-stage LoRA fine-tuning on synthetic GPT-4o-generated data. Evaluation with a human-aligned GPT-Judge and a user study with 108 students shows that 8B-SCRIBE models achieve comparable or superior quality to much larger models in key dimensions such as relevance and actionability, while being perceived on par with GPT-4o and Llama-3.3 70B by students. These findings demonstrate the viability of SCRIBE for low-resource, privacy-sensitive educational applications.
ELLIS Alicante at CQs-Gen 2025: Winning the critical thinking questions shared task: LLM-based question generation and selection
Jun 17, 2025The widespread adoption of chat interfaces based on Large Language Models (LLMs) raises concerns about promoting superficial learning and undermining the development of critical thinking skills. Instead of relying on LLMs purely for retrieving factual information, this work explores their potential to foster deeper reasoning by generating critical questions that challenge unsupported or vague claims in debate interventions. This study is part of a shared task of the 12th Workshop on Argument Mining, co-located with ACL 2025, focused on automatic critical question generation. We propose a two-step framework involving two small-scale open source language models: a Questioner that generates multiple candidate questions and a Judge that selects the most relevant ones. Our system ranked first in the shared task competition, demonstrating the potential of the proposed LLM-based approach to encourage critical engagement with argumentative texts.
ClickSight: Interpreting Student Clickstreams to Reveal Insights on Learning Strategies via LLMs
May 21, 2025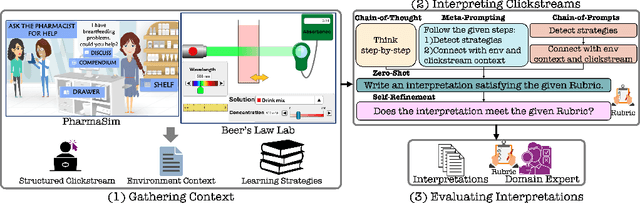

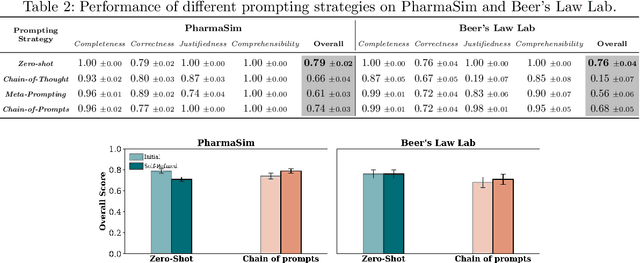
Clickstream data from digital learning environments offer valuable insights into students' learning behaviors, but are challenging to interpret due to their high dimensionality and granularity. Prior approaches have relied mainly on handcrafted features, expert labeling, clustering, or supervised models, therefore often lacking generalizability and scalability. In this work, we introduce ClickSight, an in-context Large Language Model (LLM)-based pipeline that interprets student clickstreams to reveal their learning strategies. ClickSight takes raw clickstreams and a list of learning strategies as input and generates textual interpretations of students' behaviors during interaction. We evaluate four different prompting strategies and investigate the impact of self-refinement on interpretation quality. Our evaluation spans two open-ended learning environments and uses a rubric-based domain-expert evaluation. Results show that while LLMs can reasonably interpret learning strategies from clickstreams, interpretation quality varies by prompting strategy, and self-refinement offers limited improvement. ClickSight demonstrates the potential of LLMs to generate theory-driven insights from educational interaction data.