 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeClickSight: Interpreting Student Clickstreams to Reveal Insights on Learning Strategies via LLMs
May 21, 2025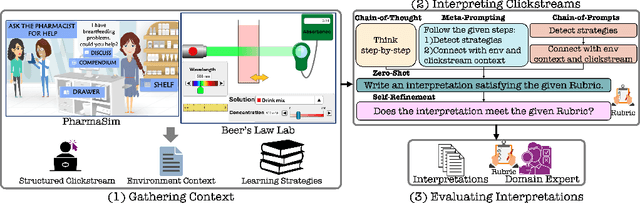

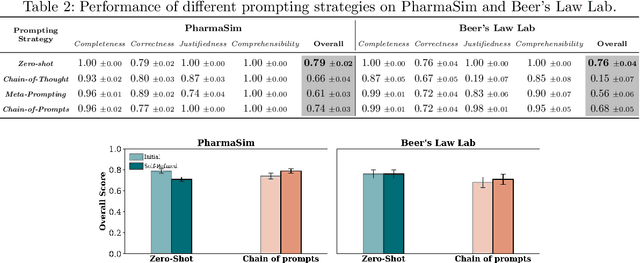
Clickstream data from digital learning environments offer valuable insights into students' learning behaviors, but are challenging to interpret due to their high dimensionality and granularity. Prior approaches have relied mainly on handcrafted features, expert labeling, clustering, or supervised models, therefore often lacking generalizability and scalability. In this work, we introduce ClickSight, an in-context Large Language Model (LLM)-based pipeline that interprets student clickstreams to reveal their learning strategies. ClickSight takes raw clickstreams and a list of learning strategies as input and generates textual interpretations of students' behaviors during interaction. We evaluate four different prompting strategies and investigate the impact of self-refinement on interpretation quality. Our evaluation spans two open-ended learning environments and uses a rubric-based domain-expert evaluation. Results show that while LLMs can reasonably interpret learning strategies from clickstreams, interpretation quality varies by prompting strategy, and self-refinement offers limited improvement. ClickSight demonstrates the potential of LLMs to generate theory-driven insights from educational interaction data.
Towards Generalizable Agents in Text-Based Educational Environments: A Study of Integrating RL with LLMs
Apr 29, 2024



There has been a growing interest in developing learner models to enhance learning and teaching experiences in educational environments. However, existing works have primarily focused on structured environments relying on meticulously crafted representations of tasks, thereby limiting the agent's ability to generalize skills across tasks. In this paper, we aim to enhance the generalization capabilities of agents in open-ended text-based learning environments by integrating Reinforcement Learning (RL) with Large Language Models (LLMs). We investigate three types of agents: (i) RL-based agents that utilize natural language for state and action representations to find the best interaction strategy, (ii) LLM-based agents that leverage the model's general knowledge and reasoning through prompting, and (iii) hybrid LLM-assisted RL agents that combine these two strategies to improve agents' performance and generalization. To support the development and evaluation of these agents, we introduce PharmaSimText, a novel benchmark derived from the PharmaSim virtual pharmacy environment designed for practicing diagnostic conversations. Our results show that RL-based agents excel in task completion but lack in asking quality diagnostic questions. In contrast, LLM-based agents perform better in asking diagnostic questions but fall short of completing the task. Finally, hybrid LLM-assisted RL agents enable us to overcome these limitations, highlighting the potential of combining RL and LLMs to develop high-performing agents for open-ended learning environments.
Evaluating the Explainers: Black-Box Explainable Machine Learning for Student Success Prediction in MOOCs
Jul 01, 2022
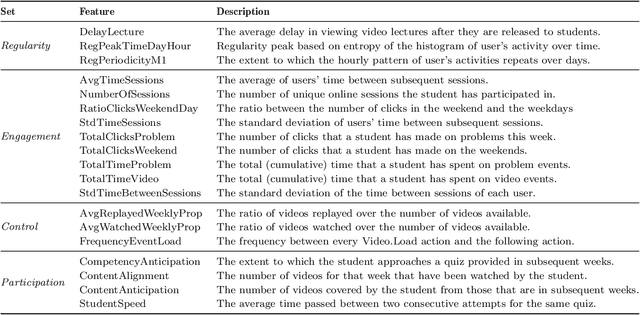

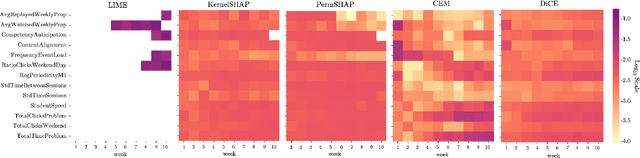
Neural networks are ubiquitous in applied machine learning for education. Their pervasive success in predictive performance comes alongside a severe weakness, the lack of explainability of their decisions, especially relevant in human-centric fields. We implement five state-of-the-art methodologies for explaining black-box machine learning models (LIME, PermutationSHAP, KernelSHAP, DiCE, CEM) and examine the strengths of each approach on the downstream task of student performance prediction for five massive open online courses. Our experiments demonstrate that the families of explainers do not agree with each other on feature importance for the same Bidirectional LSTM models with the same representative set of students. We use Principal Component Analysis, Jensen-Shannon distance, and Spearman's rank-order correlation to quantitatively cross-examine explanations across methods and courses. Furthermore, we validate explainer performance across curriculum-based prerequisite relationships. Our results come to the concerning conclusion that the choice of explainer is an important decision and is in fact paramount to the interpretation of the predictive results, even more so than the course the model is trained on. Source code and models are released at http://github.com/epfl-ml4ed/evaluating-explainers.