 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhen Mitigating Bias is Unfair: A Comprehensive Study on the Impact of Bias Mitigation Algorithms
Feb 14, 2023Most works on the fairness of machine learning systems focus on the blind optimization of common fairness metrics, such as Demographic Parity and Equalized Odds. In this paper, we conduct a comparative study of several bias mitigation approaches to investigate their behaviors at a fine grain, the prediction level. Our objective is to characterize the differences between fair models obtained with different approaches. With comparable performances in fairness and accuracy, are the different bias mitigation approaches impacting a similar number of individuals? Do they mitigate bias in a similar way? Do they affect the same individuals when debiasing a model? Our findings show that bias mitigation approaches differ a lot in their strategies, both in the number of impacted individuals and the populations targeted. More surprisingly, we show these results even apply for several runs of the same mitigation approach. These findings raise questions about the limitations of the current group fairness metrics, as well as the arbitrariness, hence unfairness, of the whole debiasing process.
Evaluating the Explainers: Black-Box Explainable Machine Learning for Student Success Prediction in MOOCs
Jul 01, 2022
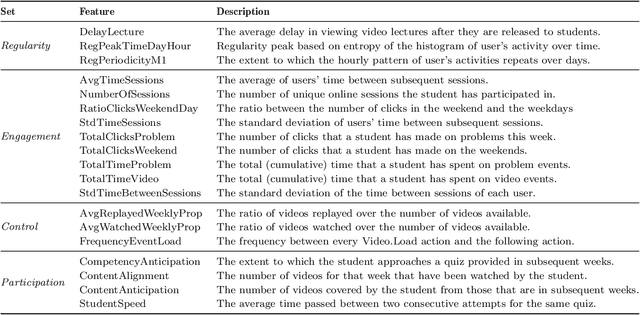

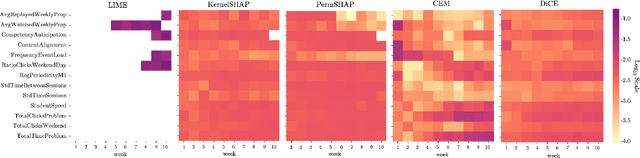
Neural networks are ubiquitous in applied machine learning for education. Their pervasive success in predictive performance comes alongside a severe weakness, the lack of explainability of their decisions, especially relevant in human-centric fields. We implement five state-of-the-art methodologies for explaining black-box machine learning models (LIME, PermutationSHAP, KernelSHAP, DiCE, CEM) and examine the strengths of each approach on the downstream task of student performance prediction for five massive open online courses. Our experiments demonstrate that the families of explainers do not agree with each other on feature importance for the same Bidirectional LSTM models with the same representative set of students. We use Principal Component Analysis, Jensen-Shannon distance, and Spearman's rank-order correlation to quantitatively cross-examine explanations across methods and courses. Furthermore, we validate explainer performance across curriculum-based prerequisite relationships. Our results come to the concerning conclusion that the choice of explainer is an important decision and is in fact paramount to the interpretation of the predictive results, even more so than the course the model is trained on. Source code and models are released at http://github.com/epfl-ml4ed/evaluating-explainers.