 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerative AI for Education (GAIED): Advances, Opportunities, and Challenges
Feb 07, 2024This survey article has grown out of the GAIED (pronounced "guide") workshop organized by the authors at the NeurIPS 2023 conference. We organized the GAIED workshop as part of a community-building effort to bring together researchers, educators, and practitioners to explore the potential of generative AI for enhancing education. This article aims to provide an overview of the workshop activities and highlight several future research directions in the area of GAIED.
Getting too personal(ized): The importance of feature choice in online adaptive algorithms
Sep 06, 2023



Digital educational technologies offer the potential to customize students' experiences and learn what works for which students, enhancing the technology as more students interact with it. We consider whether and when attempting to discover how to personalize has a cost, such as if the adaptation to personal information can delay the adoption of policies that benefit all students. We explore these issues in the context of using multi-armed bandit (MAB) algorithms to learn a policy for what version of an educational technology to present to each student, varying the relation between student characteristics and outcomes and also whether the algorithm is aware of these characteristics. Through simulations, we demonstrate that the inclusion of student characteristics for personalization can be beneficial when those characteristics are needed to learn the optimal action. In other scenarios, this inclusion decreases performance of the bandit algorithm. Moreover, including unneeded student characteristics can systematically disadvantage students with less common values for these characteristics. Our simulations do however suggest that real-time personalization will be helpful in particular real-world scenarios, and we illustrate this through case studies using existing experimental results in ASSISTments. Overall, our simulations show that adaptive personalization in educational technologies can be a double-edged sword: real-time adaptation improves student experiences in some contexts, but the slower adaptation and potentially discriminatory results mean that a more personalized model is not always beneficial.
Reinforcement Learning for Education: Opportunities and Challenges
Jul 15, 2021This survey article has grown out of the RL4ED workshop organized by the authors at the Educational Data Mining (EDM) 2021 conference. We organized this workshop as part of a community-building effort to bring together researchers and practitioners interested in the broad areas of reinforcement learning (RL) and education (ED). This article aims to provide an overview of the workshop activities and summarize the main research directions in the area of RL for ED.
Encodings of Source Syntax: Similarities in NMT Representations Across Target Languages
May 17, 2020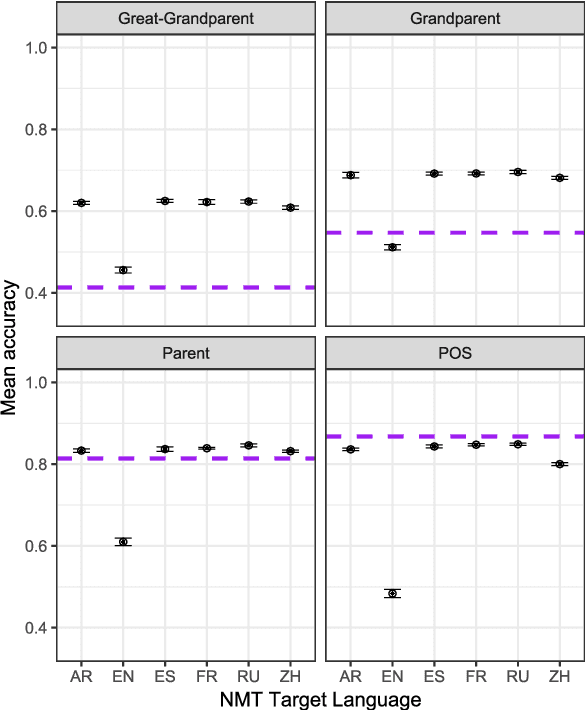
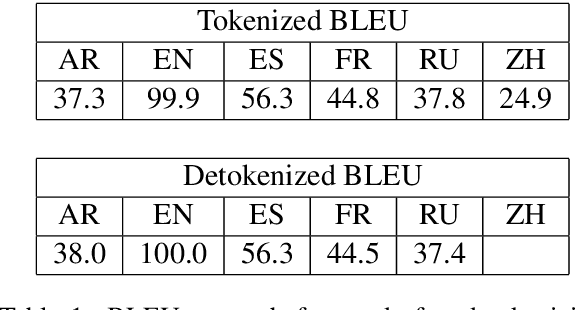


We train neural machine translation (NMT) models from English to six target languages, using NMT encoder representations to predict ancestor constituent labels of source language words. We find that NMT encoders learn similar source syntax regardless of NMT target language, relying on explicit morphosyntactic cues to extract syntactic features from source sentences. Furthermore, the NMT encoders outperform RNNs trained directly on several of the constituent label prediction tasks, suggesting that NMT encoder representations can be used effectively for natural language tasks involving syntax. However, both the NMT encoders and the directly-trained RNNs learn substantially different syntactic information from a probabilistic context-free grammar (PCFG) parser. Despite lower overall accuracy scores, the PCFG often performs well on sentences for which the RNN-based models perform poorly, suggesting that RNN architectures are constrained in the types of syntax they can learn.
An Overview of Machine Teaching
Jan 18, 2018In this paper we try to organize machine teaching as a coherent set of ideas. Each idea is presented as varying along a dimension. The collection of dimensions then form the problem space of machine teaching, such that existing teaching problems can be characterized in this space. We hope this organization allows us to gain deeper understanding of individual teaching problems, discover connections among them, and identify gaps in the field.