 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to Trust: How Humans Mentally Recalibrate AI Confidence Signals
Mar 23, 2026Productive human-AI collaboration requires appropriate reliance, yet contemporary AI systems are often miscalibrated, exhibiting systematic overconfidence or underconfidence. We investigate whether humans can learn to mentally recalibrate AI confidence signals through repeated experience. In a behavioral experiment (N = 200), participants predicted the AI's correctness across four AI calibration conditions: standard, overconfidence, underconfidence, and a counterintuitive "reverse confidence" mapping. Results demonstrate robust learning across all conditions, with participants significantly improving their accuracy, discrimination, and calibration alignment over 50 trials. We present a computational model utilizing a linear-in-log-odds (LLO) transformation and a Rescorla-Wagner learning rule to explain these dynamics. The model reveals that humans adapt by updating their baseline trust and confidence sensitivity, using asymmetric learning rates to prioritize the most informative errors. While humans can compensate for monotonic miscalibration, we identify a significant boundary in the reverse confidence scenario, where a substantial proportion of participants struggled to override initial inductive biases. These findings provide a mechanistic account of how humans adapt their trust in AI confidence signals through experience.
Beyond Accuracy: How AI Metacognitive Sensitivity improves AI-assisted Decision Making
Jul 30, 2025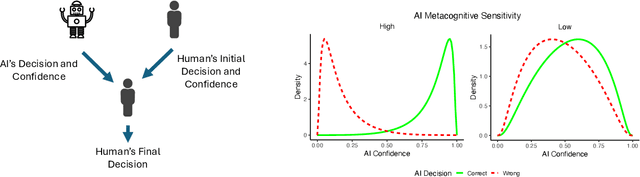


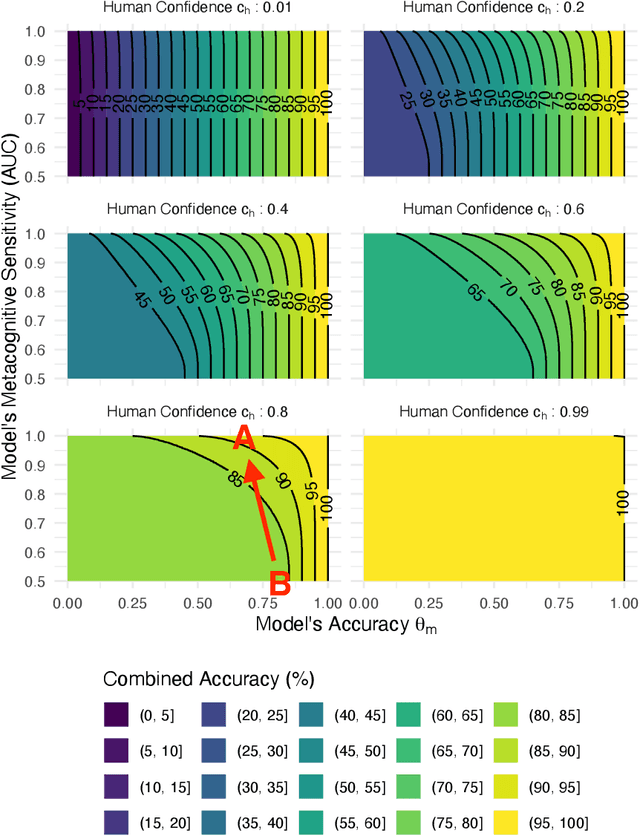
In settings where human decision-making relies on AI input, both the predictive accuracy of the AI system and the reliability of its confidence estimates influence decision quality. We highlight the role of AI metacognitive sensitivity -- its ability to assign confidence scores that accurately distinguish correct from incorrect predictions -- and introduce a theoretical framework for assessing the joint impact of AI's predictive accuracy and metacognitive sensitivity in hybrid decision-making settings. Our analysis identifies conditions under which an AI with lower predictive accuracy but higher metacognitive sensitivity can enhance the overall accuracy of human decision making. Finally, a behavioral experiment confirms that greater AI metacognitive sensitivity improves human decision performance. Together, these findings underscore the importance of evaluating AI assistance not only by accuracy but also by metacognitive sensitivity, and of optimizing both to achieve superior decision outcomes.
Getting too personal(ized): The importance of feature choice in online adaptive algorithms
Sep 06, 2023



Digital educational technologies offer the potential to customize students' experiences and learn what works for which students, enhancing the technology as more students interact with it. We consider whether and when attempting to discover how to personalize has a cost, such as if the adaptation to personal information can delay the adoption of policies that benefit all students. We explore these issues in the context of using multi-armed bandit (MAB) algorithms to learn a policy for what version of an educational technology to present to each student, varying the relation between student characteristics and outcomes and also whether the algorithm is aware of these characteristics. Through simulations, we demonstrate that the inclusion of student characteristics for personalization can be beneficial when those characteristics are needed to learn the optimal action. In other scenarios, this inclusion decreases performance of the bandit algorithm. Moreover, including unneeded student characteristics can systematically disadvantage students with less common values for these characteristics. Our simulations do however suggest that real-time personalization will be helpful in particular real-world scenarios, and we illustrate this through case studies using existing experimental results in ASSISTments. Overall, our simulations show that adaptive personalization in educational technologies can be a double-edged sword: real-time adaptation improves student experiences in some contexts, but the slower adaptation and potentially discriminatory results mean that a more personalized model is not always beneficial.
Explainable AI for Natural Adversarial Images
Jun 16, 2021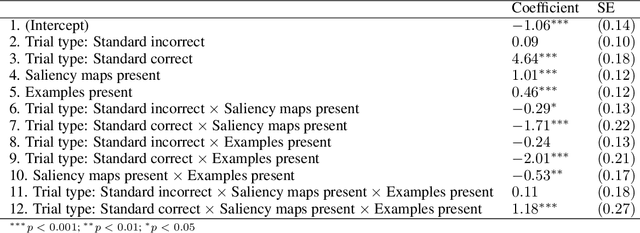
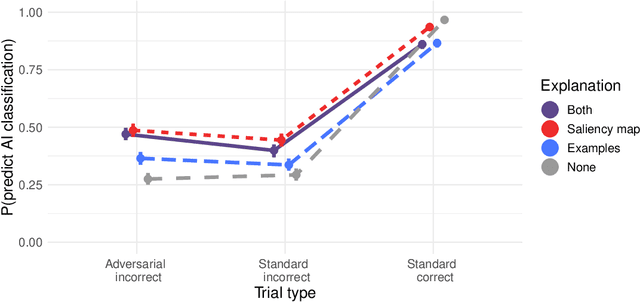
Adversarial images highlight how vulnerable modern image classifiers are to perturbations outside of their training set. Human oversight might mitigate this weakness, but depends on humans understanding the AI well enough to predict when it is likely to make a mistake. In previous work we have found that humans tend to assume that the AI's decision process mirrors their own. Here we evaluate if methods from explainable AI can disrupt this assumption to help participants predict AI classifications for adversarial and standard images. We find that both saliency maps and examples facilitate catching AI errors, but their effects are not additive, and saliency maps are more effective than examples.