 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA psychological theory of explainability
May 17, 2022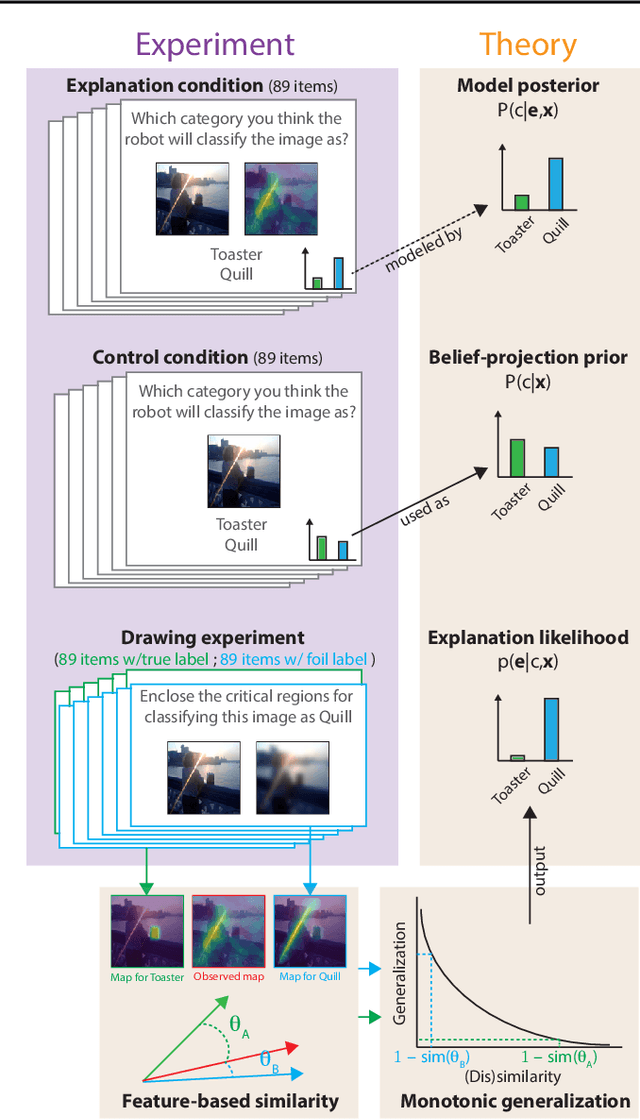
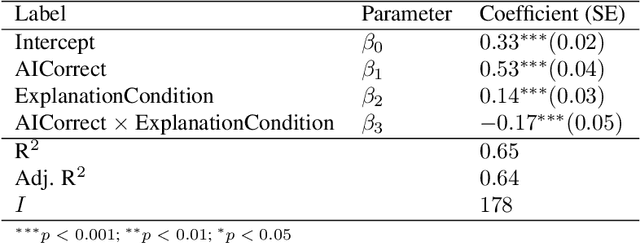
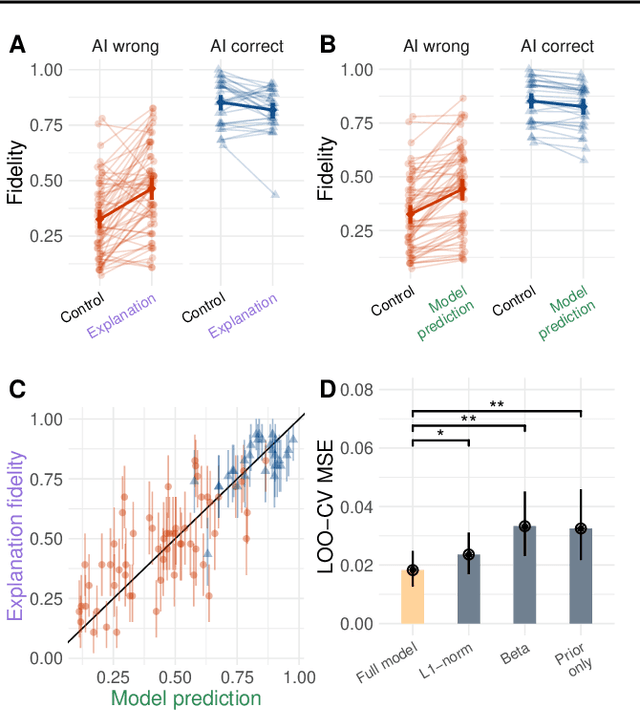
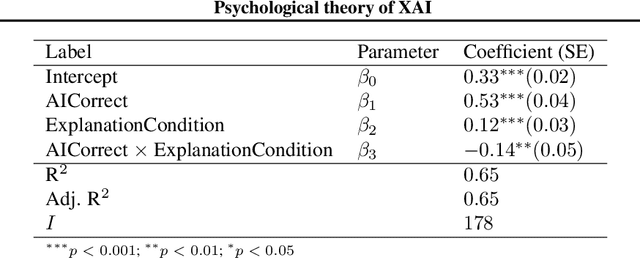
The goal of explainable Artificial Intelligence (XAI) is to generate human-interpretable explanations, but there are no computationally precise theories of how humans interpret AI generated explanations. The lack of theory means that validation of XAI must be done empirically, on a case-by-case basis, which prevents systematic theory-building in XAI. We propose a psychological theory of how humans draw conclusions from saliency maps, the most common form of XAI explanation, which for the first time allows for precise prediction of explainee inference conditioned on explanation. Our theory posits that absent explanation humans expect the AI to make similar decisions to themselves, and that they interpret an explanation by comparison to the explanations they themselves would give. Comparison is formalized via Shepard's universal law of generalization in a similarity space, a classic theory from cognitive science. A pre-registered user study on AI image classifications with saliency map explanations demonstrate that our theory quantitatively matches participants' predictions of the AI.
Explainable AI for Natural Adversarial Images
Jun 16, 2021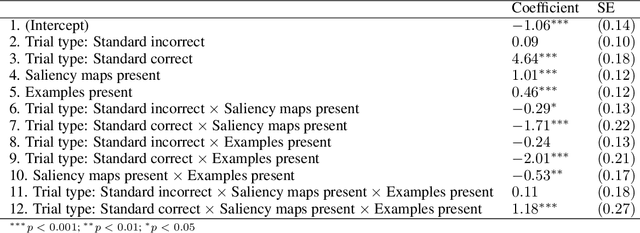
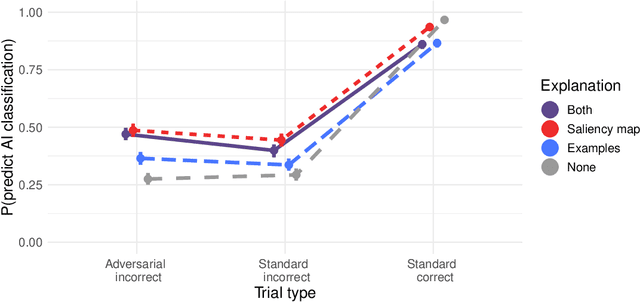
Adversarial images highlight how vulnerable modern image classifiers are to perturbations outside of their training set. Human oversight might mitigate this weakness, but depends on humans understanding the AI well enough to predict when it is likely to make a mistake. In previous work we have found that humans tend to assume that the AI's decision process mirrors their own. Here we evaluate if methods from explainable AI can disrupt this assumption to help participants predict AI classifications for adversarial and standard images. We find that both saliency maps and examples facilitate catching AI errors, but their effects are not additive, and saliency maps are more effective than examples.
Explainable AI for medical imaging: Explaining pneumothorax diagnoses with Bayesian Teaching
Jun 08, 2021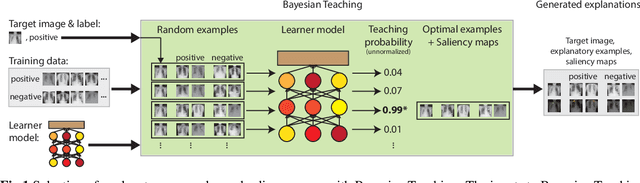


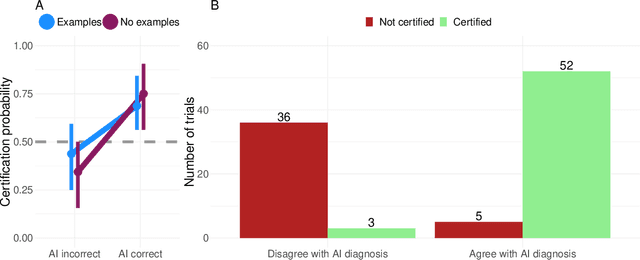
Limited expert time is a key bottleneck in medical imaging. Due to advances in image classification, AI can now serve as decision-support for medical experts, with the potential for great gains in radiologist productivity and, by extension, public health. However, these gains are contingent on building and maintaining experts' trust in the AI agents. Explainable AI may build such trust by helping medical experts to understand the AI decision processes behind diagnostic judgements. Here we introduce and evaluate explanations based on Bayesian Teaching, a formal account of explanation rooted in the cognitive science of human learning. We find that medical experts exposed to explanations generated by Bayesian Teaching successfully predict the AI's diagnostic decisions and are more likely to certify the AI for cases when the AI is correct than when it is wrong, indicating appropriate trust. These results show that Explainable AI can be used to support human-AI collaboration in medical imaging.
Abstraction, Validation, and Generalization for Explainable Artificial Intelligence
May 16, 2021
Neural network architectures are achieving superhuman performance on an expanding range of tasks. To effectively and safely deploy these systems, their decision-making must be understandable to a wide range of stakeholders. Methods to explain AI have been proposed to answer this challenge, but a lack of theory impedes the development of systematic abstractions which are necessary for cumulative knowledge gains. We propose Bayesian Teaching as a framework for unifying explainable AI (XAI) by integrating machine learning and human learning. Bayesian Teaching formalizes explanation as a communication act of an explainer to shift the beliefs of an explainee. This formalization decomposes any XAI method into four components: (1) the inference to be explained, (2) the explanatory medium, (3) the explainee model, and (4) the explainer model. The abstraction afforded by Bayesian Teaching to decompose any XAI method elucidates the invariances among them. The decomposition of XAI systems enables modular validation, as each of the first three components listed can be tested semi-independently. This decomposition also promotes generalization through recombination of components from different XAI systems, which facilitates the generation of novel variants. These new variants need not be evaluated one by one provided that each component has been validated, leading to an exponential decrease in development time. Finally, by making the goal of explanation explicit, Bayesian Teaching helps developers to assess how suitable an XAI system is for its intended real-world use case. Thus, Bayesian Teaching provides a theoretical framework that encourages systematic, scientific investigation of XAI.
Mitigating belief projection in explainable artificial intelligence via Bayesian Teaching
Feb 07, 2021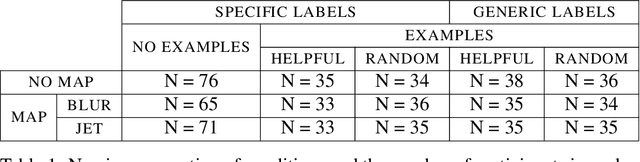

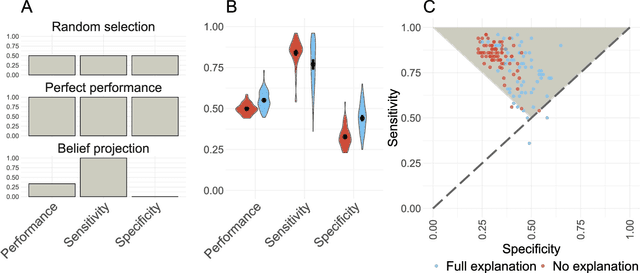
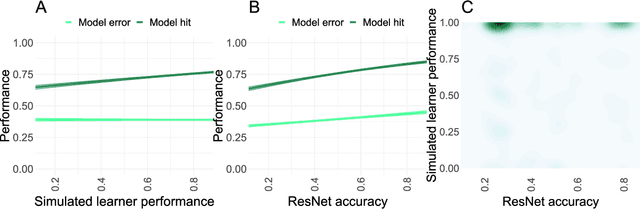
State-of-the-art deep-learning systems use decision rules that are challenging for humans to model. Explainable AI (XAI) attempts to improve human understanding but rarely accounts for how people typically reason about unfamiliar agents. We propose explicitly modeling the human explainee via Bayesian Teaching, which evaluates explanations by how much they shift explainees' inferences toward a desired goal. We assess Bayesian Teaching in a binary image classification task across a variety of contexts. Absent intervention, participants predict that the AI's classifications will match their own, but explanations generated by Bayesian Teaching improve their ability to predict the AI's judgements by moving them away from this prior belief. Bayesian Teaching further allows each case to be broken down into sub-examples (here saliency maps). These sub-examples complement whole examples by improving error detection for familiar categories, whereas whole examples help predict correct AI judgements of unfamiliar cases.