 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDynamic Local Average Treatment Effects
May 02, 2024



We consider Dynamic Treatment Regimes (DTRs) with one sided non-compliance that arise in applications such as digital recommendations and adaptive medical trials. These are settings where decision makers encourage individuals to take treatments over time, but adapt encouragements based on previous encouragements, treatments, states, and outcomes. Importantly, individuals may choose to (not) comply with a treatment recommendation, whenever it is made available to them, based on unobserved confounding factors. We provide non-parametric identification, estimation, and inference for Dynamic Local Average Treatment Effects, which are expected values of multi-period treatment contrasts among appropriately defined complier subpopulations. Under standard assumptions in the Instrumental Variable and DTR literature, we show that one can identify local average effects of contrasts that correspond to offering treatment at any single time step. Under an additional cross-period effect-compliance independence assumption, which is satisfied in Staggered Adoption settings and a generalization of them, which we define as Staggered Compliance settings, we identify local average treatment effects of treating in multiple time periods.
Explainable AI for Natural Adversarial Images
Jun 16, 2021
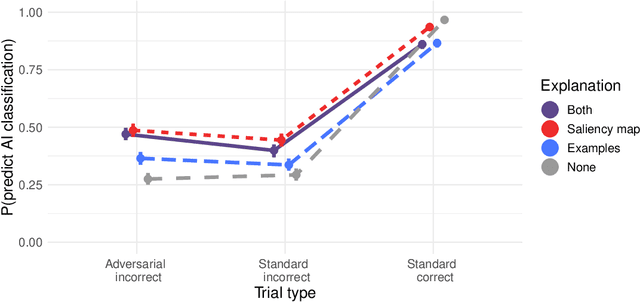
Adversarial images highlight how vulnerable modern image classifiers are to perturbations outside of their training set. Human oversight might mitigate this weakness, but depends on humans understanding the AI well enough to predict when it is likely to make a mistake. In previous work we have found that humans tend to assume that the AI's decision process mirrors their own. Here we evaluate if methods from explainable AI can disrupt this assumption to help participants predict AI classifications for adversarial and standard images. We find that both saliency maps and examples facilitate catching AI errors, but their effects are not additive, and saliency maps are more effective than examples.
Mitigating belief projection in explainable artificial intelligence via Bayesian Teaching
Feb 07, 2021

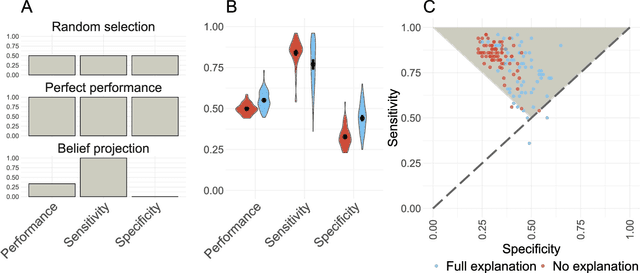
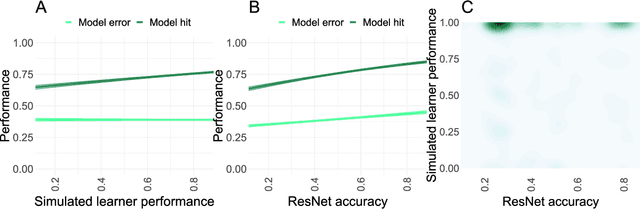
State-of-the-art deep-learning systems use decision rules that are challenging for humans to model. Explainable AI (XAI) attempts to improve human understanding but rarely accounts for how people typically reason about unfamiliar agents. We propose explicitly modeling the human explainee via Bayesian Teaching, which evaluates explanations by how much they shift explainees' inferences toward a desired goal. We assess Bayesian Teaching in a binary image classification task across a variety of contexts. Absent intervention, participants predict that the AI's classifications will match their own, but explanations generated by Bayesian Teaching improve their ability to predict the AI's judgements by moving them away from this prior belief. Bayesian Teaching further allows each case to be broken down into sub-examples (here saliency maps). These sub-examples complement whole examples by improving error detection for familiar categories, whereas whole examples help predict correct AI judgements of unfamiliar cases.