Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExplainable AI for Natural Adversarial Images
Paper and Code
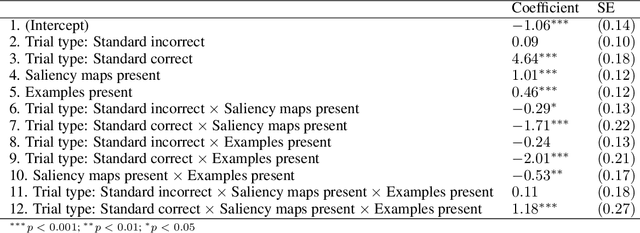
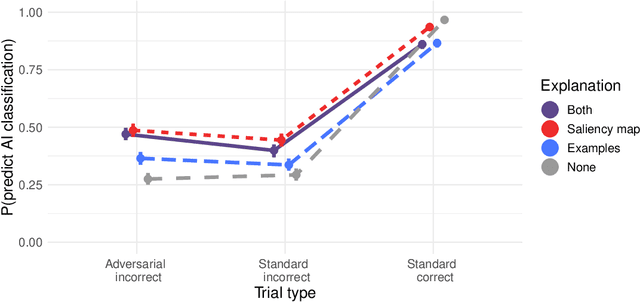
Adversarial images highlight how vulnerable modern image classifiers are to perturbations outside of their training set. Human oversight might mitigate this weakness, but depends on humans understanding the AI well enough to predict when it is likely to make a mistake. In previous work we have found that humans tend to assume that the AI's decision process mirrors their own. Here we evaluate if methods from explainable AI can disrupt this assumption to help participants predict AI classifications for adversarial and standard images. We find that both saliency maps and examples facilitate catching AI errors, but their effects are not additive, and saliency maps are more effective than examples.
View paper on