 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAction Gaps and Advantages in Continuous-Time Distributional Reinforcement Learning
Oct 14, 2024When decisions are made at high frequency, traditional reinforcement learning (RL) methods struggle to accurately estimate action values. In turn, their performance is inconsistent and often poor. Whether the performance of distributional RL (DRL) agents suffers similarly, however, is unknown. In this work, we establish that DRL agents are sensitive to the decision frequency. We prove that action-conditioned return distributions collapse to their underlying policy's return distribution as the decision frequency increases. We quantify the rate of collapse of these return distributions and exhibit that their statistics collapse at different rates. Moreover, we define distributional perspectives on action gaps and advantages. In particular, we introduce the superiority as a probabilistic generalization of the advantage -- the core object of approaches to mitigating performance issues in high-frequency value-based RL. In addition, we build a superiority-based DRL algorithm. Through simulations in an option-trading domain, we validate that proper modeling of the superiority distribution produces improved controllers at high decision frequencies.
On Feasibility of Intent Obfuscating Attacks
Jul 22, 2024Intent obfuscation is a common tactic in adversarial situations, enabling the attacker to both manipulate the target system and avoid culpability. Surprisingly, it has rarely been implemented in adversarial attacks on machine learning systems. We are the first to propose incorporating intent obfuscation in generating adversarial examples for object detectors: by perturbing another non-overlapping object to disrupt the target object, the attacker hides their intended target. We conduct a randomized experiment on 5 prominent detectors -- YOLOv3, SSD, RetinaNet, Faster R-CNN, and Cascade R-CNN -- using both targeted and untargeted attacks and achieve success on all models and attacks. We analyze the success factors characterizing intent obfuscating attacks, including target object confidence and perturb object sizes. We then demonstrate that the attacker can exploit these success factors to increase success rates for all models and attacks. Finally, we discuss known defenses and legal repercussions.
Structured Evaluation of Synthetic Tabular Data
Mar 29, 2024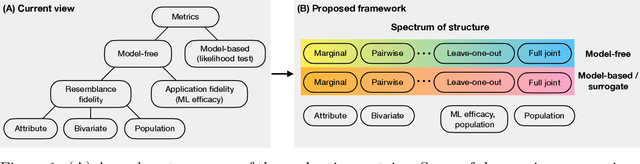
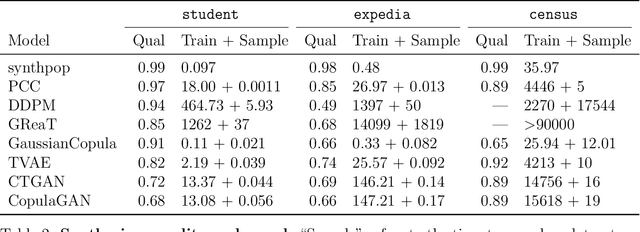
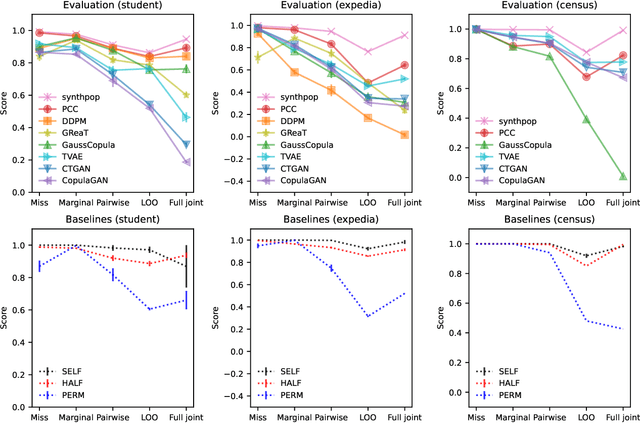
Tabular data is common yet typically incomplete, small in volume, and access-restricted due to privacy concerns. Synthetic data generation offers potential solutions. Many metrics exist for evaluating the quality of synthetic tabular data; however, we lack an objective, coherent interpretation of the many metrics. To address this issue, we propose an evaluation framework with a single, mathematical objective that posits that the synthetic data should be drawn from the same distribution as the observed data. Through various structural decomposition of the objective, this framework allows us to reason for the first time the completeness of any set of metrics, as well as unifies existing metrics, including those that stem from fidelity considerations, downstream application, and model-based approaches. Moreover, the framework motivates model-free baselines and a new spectrum of metrics. We evaluate structurally informed synthesizers and synthesizers powered by deep learning. Using our structured framework, we show that synthetic data generators that explicitly represent tabular structure outperform other methods, especially on smaller datasets.
Coupled Variational Autoencoder
Jun 05, 2023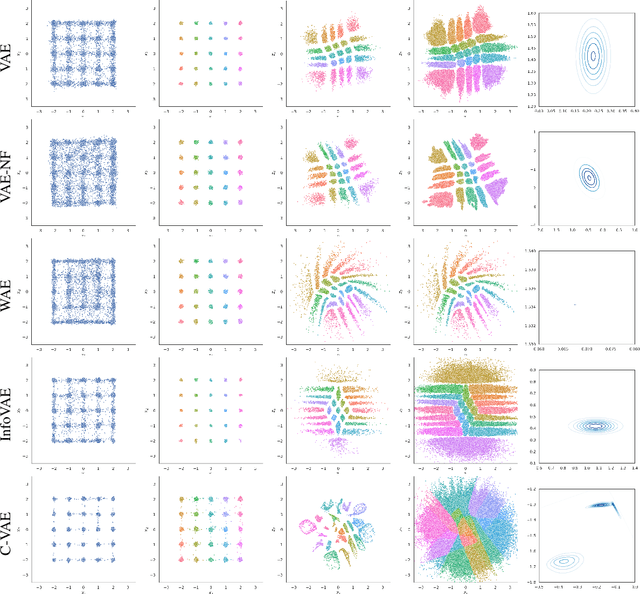
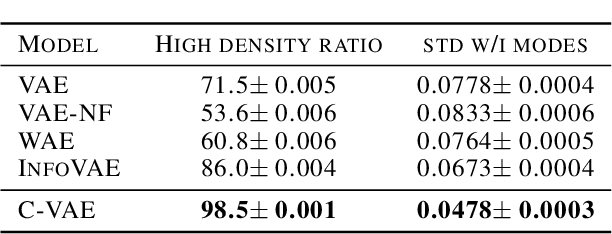

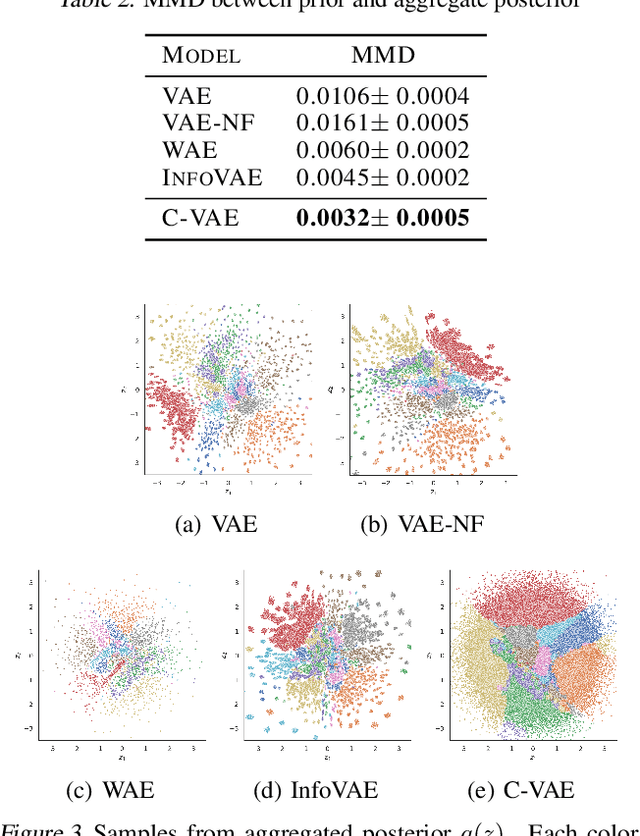
Variational auto-encoders are powerful probabilistic models in generative tasks but suffer from generating low-quality samples which are caused by the holes in the prior. We propose the Coupled Variational Auto-Encoder (C-VAE), which formulates the VAE problem as one of Optimal Transport (OT) between the prior and data distributions. The C-VAE allows greater flexibility in priors and natural resolution of the prior hole problem by enforcing coupling between the prior and the data distribution and enables flexible optimization through the primal, dual, and semi-dual formulations of entropic OT. Simulations on synthetic and real data show that the C-VAE outperforms alternatives including VAE, WAE, and InfoVAE in fidelity to the data, quality of the latent representation, and in quality of generated samples.
Evolution of beliefs in social networks
May 26, 2022
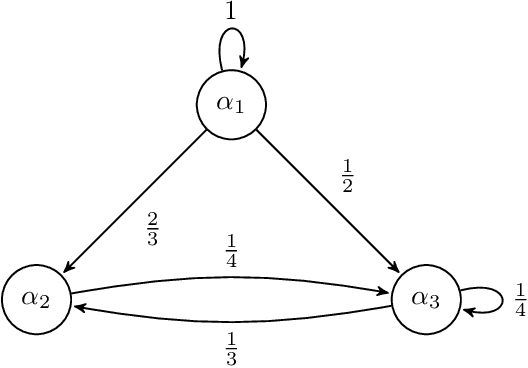
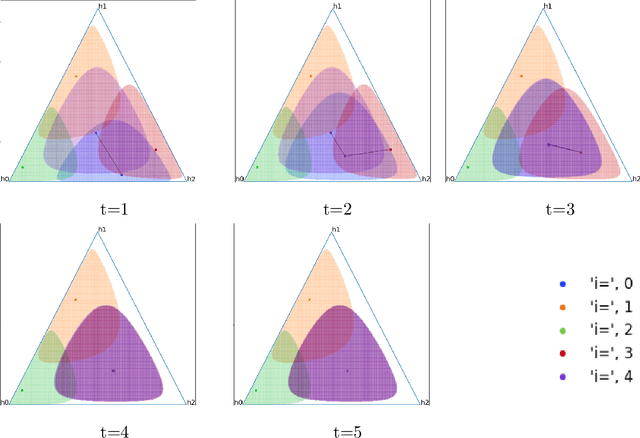
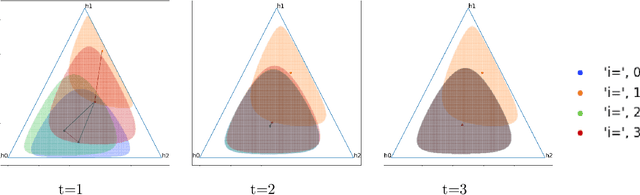
Evolution of beliefs of a society are a product of interactions between people (horizontal transmission) in the society over generations (vertical transmission). Researchers have studied both horizontal and vertical transmission separately. Extending prior work, we propose a new theoretical framework which allows application of tools from Markov chain theory to the analysis of belief evolution via horizontal and vertical transmission. We analyze three cases: static network, randomly changing network, and homophily-based dynamic network. Whereas the former two assume network structure is independent of beliefs, the latter assumes that people tend to communicate with those who have similar beliefs. We prove under general conditions that both static and randomly changing networks converge to a single set of beliefs among all individuals along with the rate of convergence. We prove that homophily-based network structures do not in general converge to a single set of beliefs shared by all and prove lower bounds on the number of different limiting beliefs as a function of initial beliefs. We conclude by discussing implications for prior theories and directions for future work.
A psychological theory of explainability
May 17, 2022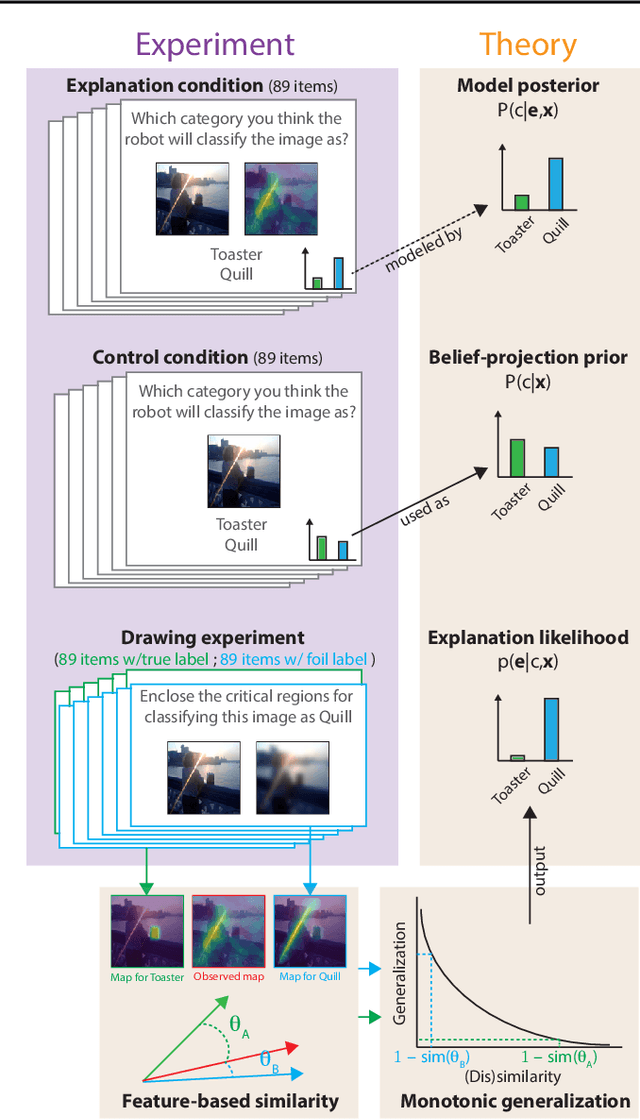
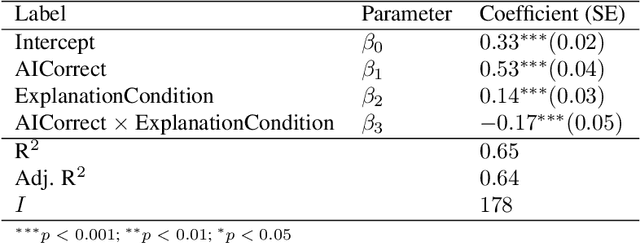
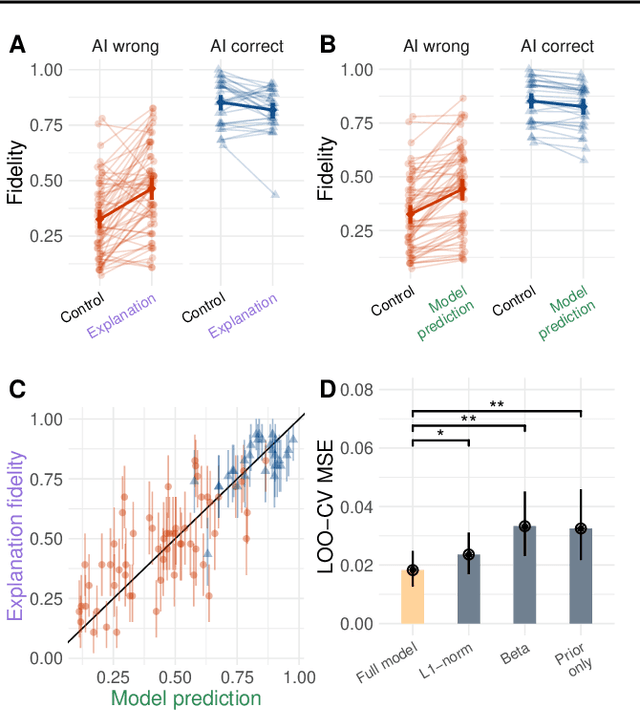
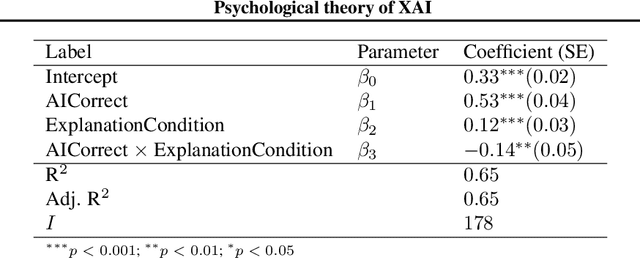
The goal of explainable Artificial Intelligence (XAI) is to generate human-interpretable explanations, but there are no computationally precise theories of how humans interpret AI generated explanations. The lack of theory means that validation of XAI must be done empirically, on a case-by-case basis, which prevents systematic theory-building in XAI. We propose a psychological theory of how humans draw conclusions from saliency maps, the most common form of XAI explanation, which for the first time allows for precise prediction of explainee inference conditioned on explanation. Our theory posits that absent explanation humans expect the AI to make similar decisions to themselves, and that they interpret an explanation by comparison to the explanations they themselves would give. Comparison is formalized via Shepard's universal law of generalization in a similarity space, a classic theory from cognitive science. A pre-registered user study on AI image classifications with saliency map explanations demonstrate that our theory quantitatively matches participants' predictions of the AI.
On Connecting Deep Trigonometric Networks with Deep Gaussian Processes: Covariance, Expressivity, and Neural Tangent Kernel
Mar 14, 2022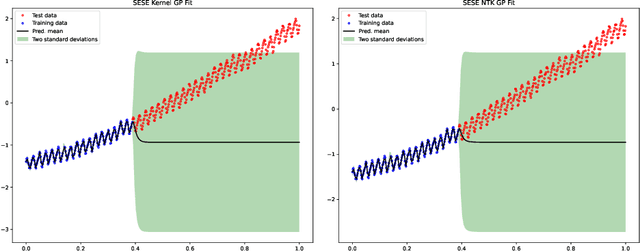
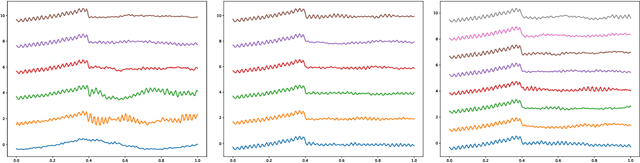
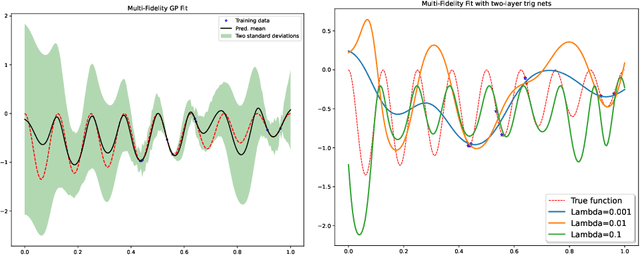
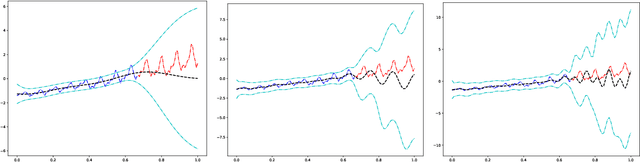
Deep Gaussian Process as a Bayesian learning model is promising because it is expressive and capable of uncertainty estimation. With Bochner's theorem, we can view the deep Gaussian process with squared exponential kernels as a deep trigonometric network consisting of the random feature layers, sine and cosine activation units, and random weight layers. Focusing on this particular class of models allows us to obtain analytical results. We shall show that the weight space view yields the same effective covariance functions which were obtained previously in function space. The heavy statistical tails can be studied with multivariate characteristic function. In addition, the trig networks are flexible and expressive as one can freely adopt different prior distributions over the parameters in weight and feature layers. Lastly, the deep trigonometric network representation of deep Gaussian process allows the derivation of its neural tangent kernel, which can reveal the mean of predictive distribution from the intractable inference.
Probabilistic Inverse Optimal Transport
Dec 17, 2021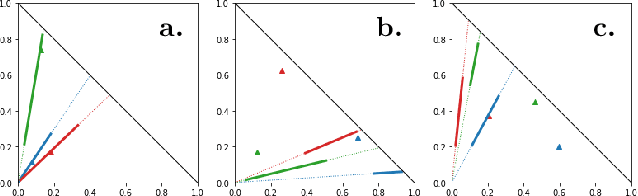
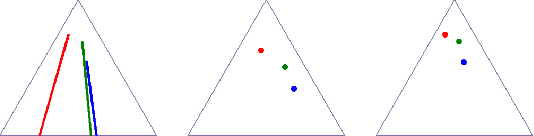
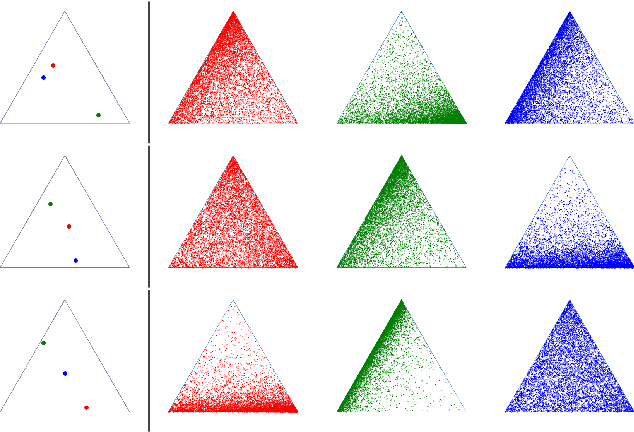
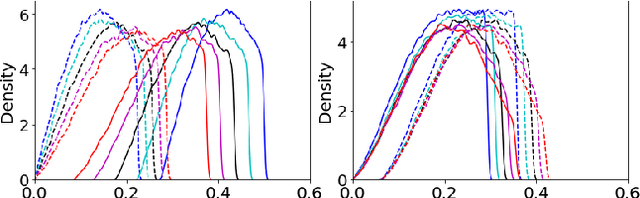
Optimal transport (OT) formalizes the problem of finding an optimal coupling between probability measures given a cost matrix. The inverse problem of inferring the cost given a coupling is Inverse Optimal Transport (IOT). IOT is less well understood than OT. We formalize and systematically analyze the properties of IOT using tools from the study of entropy-regularized OT. Theoretical contributions include characterization of the manifold of cross-ratio equivalent costs, the implications of model priors, and derivation of an MCMC sampler. Empirical contributions include visualizations of cross-ratio equivalent effect on basic examples and simulations validating theoretical results.
Conditional Deep Gaussian Processes: empirical Bayes hyperdata learning
Oct 01, 2021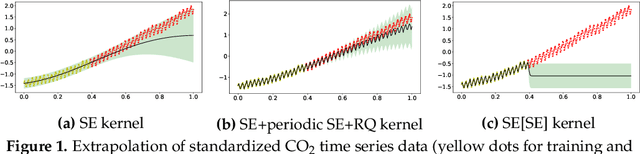
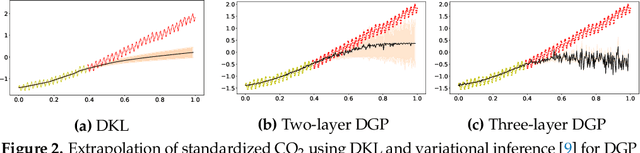
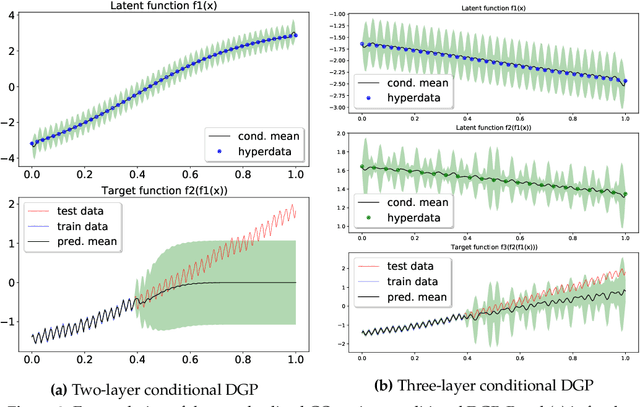
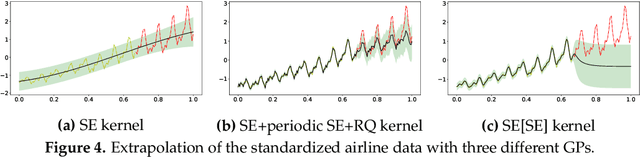
It is desirable to combine the expressive power of deep learning with Gaussian Process (GP) in one expressive Bayesian learning model. Deep kernel learning proposed in [1] showed success in adopting a deep network for feature extraction followed by a GP used as function model. Recently, [2] suggested that the deterministic nature of feature extractor may lead to overfitting while the replacement with a Bayesian network seemed to cure it. Here, we propose the conditional Deep Gaussian Process (DGP) in which the intermediate GPs in hierarchical composition are supported by the hyperdata and the exposed GP remains zero mean. Motivated by the inducing points in sparse GP, the hyperdata also play the role of function supports, but are hyperparameters rather than random variables. We use the moment matching method [3] to approximate the marginal prior for conditional DGP with a GP carrying an effective kernel. Thus, as in empirical Bayes, the hyperdata are learned by optimizing the approximate marginal likelihood which implicitly depends on the hyperdata via the kernel. We shall show the equivalence with the deep kernel learning in the limit of dense hyperdata in latent space. However, the conditional DGP and the corresponding approximate inference enjoy the benefit of being more Bayesian than deep kernel learning. Preliminary extrapolation results demonstrate expressive power of the proposed model compared with GP kernel composition, DGP variational inference, and deep kernel learning. We also address the non-Gaussian aspect of our model as well as way of upgrading to a full Bayes inference.
Explainable AI for Natural Adversarial Images
Jun 16, 2021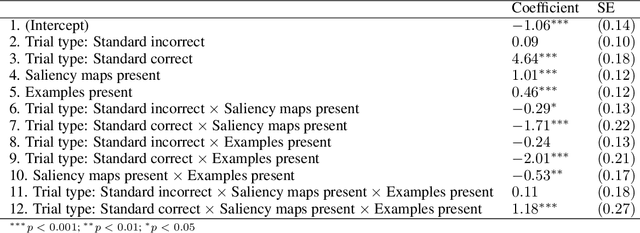
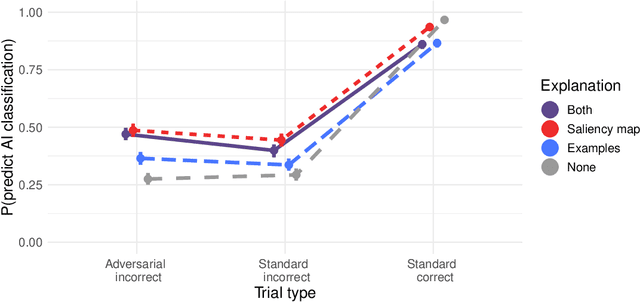
Adversarial images highlight how vulnerable modern image classifiers are to perturbations outside of their training set. Human oversight might mitigate this weakness, but depends on humans understanding the AI well enough to predict when it is likely to make a mistake. In previous work we have found that humans tend to assume that the AI's decision process mirrors their own. Here we evaluate if methods from explainable AI can disrupt this assumption to help participants predict AI classifications for adversarial and standard images. We find that both saliency maps and examples facilitate catching AI errors, but their effects are not additive, and saliency maps are more effective than examples.