 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNaviHydra: Controllable Navigation-guided End-to-end Autonomous Driving with Hydra-distillation
Dec 11, 2025



The complexity of autonomous driving scenarios requires robust models that can interpret high-level navigation commands and generate safe trajectories. While traditional rule-based systems can react to these commands, they often struggle in dynamic environments, and end-to-end methods face challenges in complying with explicit navigation commands. To address this, we present NaviHydra, a controllable navigation-guided end-to-end model distilled from an existing rule-based simulator. Our framework accepts high-level navigation commands as control signals, generating trajectories that align with specified intentions. We utilize a Bird's Eye View (BEV) based trajectory gathering method to enhance the trajectory feature extraction. Additionally, we introduce a novel navigation compliance metric to evaluate adherence to intended route, improving controllability and navigation safety. To comprehensively assess our model's controllability, we design a test that evaluates its response to various navigation commands. Our method significantly outperforms baseline models, achieving state-of-the-art results in the NAVSIM benchmark, demonstrating its effectiveness in advancing autonomous driving.
syftr: Pareto-Optimal Generative AI
May 26, 2025Retrieval-Augmented Generation (RAG) pipelines are central to applying large language models (LLMs) to proprietary or dynamic data. However, building effective RAG flows is complex, requiring careful selection among vector databases, embedding models, text splitters, retrievers, and synthesizing LLMs. The challenge deepens with the rise of agentic paradigms. Modules like verifiers, rewriters, and rerankers-each with intricate hyperparameter dependencies have to be carefully tuned. Balancing tradeoffs between latency, accuracy, and cost becomes increasingly difficult in performance-sensitive applications. We introduce syftr, a framework that performs efficient multi-objective search over a broad space of agentic and non-agentic RAG configurations. Using Bayesian Optimization, syftr discovers Pareto-optimal flows that jointly optimize task accuracy and cost. A novel early-stopping mechanism further improves efficiency by pruning clearly suboptimal candidates. Across multiple RAG benchmarks, syftr finds flows which are on average approximately 9 times cheaper while preserving most of the accuracy of the most accurate flows on the Pareto-frontier. Furthermore, syftr's ability to design and optimize allows integrating new modules, making it even easier and faster to realize high-performing generative AI pipelines.
Evaluating the performance-deviation of itemKNN in RecBole and LensKit
Jul 18, 2024
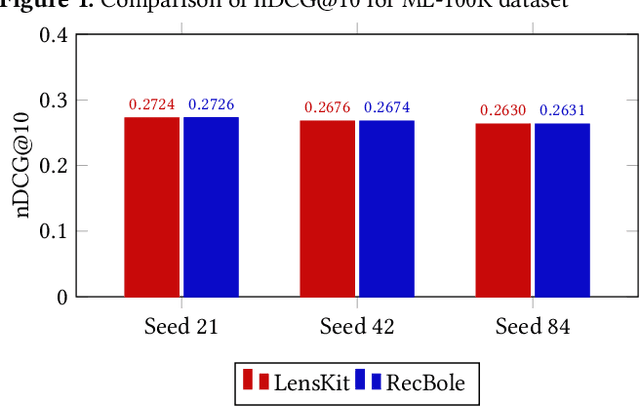
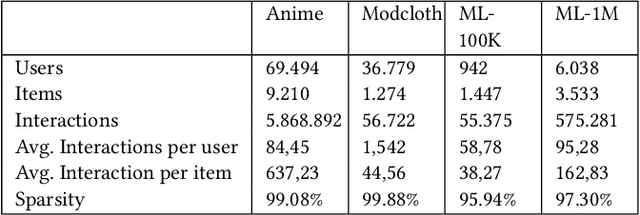

This study examines the performance of item-based k-Nearest Neighbors (ItemKNN) algorithms in the RecBole and LensKit recommender system libraries. Using four data sets (Anime, Modcloth, ML-100K, and ML-1M), we assess each library's efficiency, accuracy, and scalability, focusing primarily on normalized discounted cumulative gain (nDCG). Our results show that RecBole outperforms LensKit on two of three metrics on the ML-100K data set: it achieved an 18% higher nDCG, 14% higher precision, and 35% lower recall. To ensure a fair comparison, we adjusted LensKit's nDCG calculation to match RecBole's method. This alignment made the performance more comparable, with LensKit achieving an nDCG of 0.2540 and RecBole 0.2674. Differences in similarity matrix calculations were identified as the main cause of performance deviations. After modifying LensKit to retain only the top K similar items, both libraries showed nearly identical nDCG values across all data sets. For instance, both achieved an nDCG of 0.2586 on the ML-1M data set with the same random seed. Initially, LensKit's original implementation only surpassed RecBole in the ModCloth dataset.
Structured Evaluation of Synthetic Tabular Data
Mar 29, 2024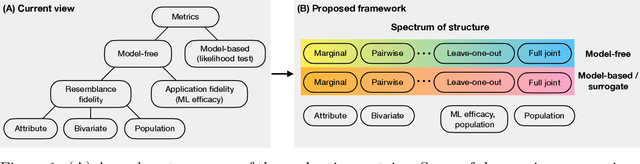
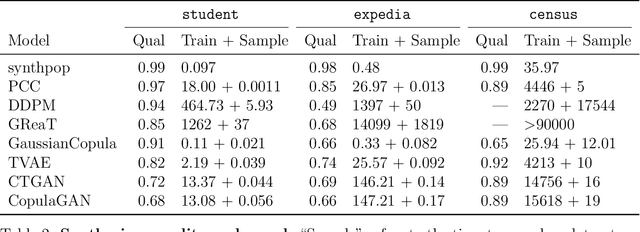
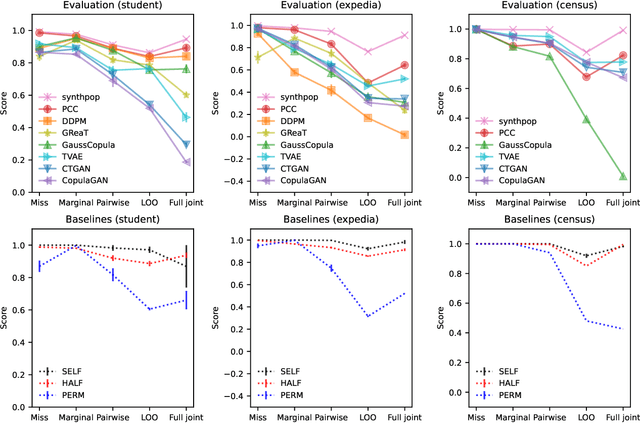
Tabular data is common yet typically incomplete, small in volume, and access-restricted due to privacy concerns. Synthetic data generation offers potential solutions. Many metrics exist for evaluating the quality of synthetic tabular data; however, we lack an objective, coherent interpretation of the many metrics. To address this issue, we propose an evaluation framework with a single, mathematical objective that posits that the synthetic data should be drawn from the same distribution as the observed data. Through various structural decomposition of the objective, this framework allows us to reason for the first time the completeness of any set of metrics, as well as unifies existing metrics, including those that stem from fidelity considerations, downstream application, and model-based approaches. Moreover, the framework motivates model-free baselines and a new spectrum of metrics. We evaluate structurally informed synthesizers and synthesizers powered by deep learning. Using our structured framework, we show that synthetic data generators that explicitly represent tabular structure outperform other methods, especially on smaller datasets.
Word Importance Explains How Prompts Affect Language Model Outputs
Mar 05, 2024The emergence of large language models (LLMs) has revolutionized numerous applications across industries. However, their "black box" nature often hinders the understanding of how they make specific decisions, raising concerns about their transparency, reliability, and ethical use. This study presents a method to improve the explainability of LLMs by varying individual words in prompts to uncover their statistical impact on the model outputs. This approach, inspired by permutation importance for tabular data, masks each word in the system prompt and evaluates its effect on the outputs based on the available text scores aggregated over multiple user inputs. Unlike classical attention, word importance measures the impact of prompt words on arbitrarily-defined text scores, which enables decomposing the importance of words into the specific measures of interest--including bias, reading level, verbosity, etc. This procedure also enables measuring impact when attention weights are not available. To test the fidelity of this approach, we explore the effect of adding different suffixes to multiple different system prompts and comparing subsequent generations with different large language models. Results show that word importance scores are closely related to the expected suffix importances for multiple scoring functions.
3D Adversarial Augmentations for Robust Out-of-Domain Predictions
Aug 29, 2023Since real-world training datasets cannot properly sample the long tail of the underlying data distribution, corner cases and rare out-of-domain samples can severely hinder the performance of state-of-the-art models. This problem becomes even more severe for dense tasks, such as 3D semantic segmentation, where points of non-standard objects can be confidently associated to the wrong class. In this work, we focus on improving the generalization to out-of-domain data. We achieve this by augmenting the training set with adversarial examples. First, we learn a set of vectors that deform the objects in an adversarial fashion. To prevent the adversarial examples from being too far from the existing data distribution, we preserve their plausibility through a series of constraints, ensuring sensor-awareness and shapes smoothness. Then, we perform adversarial augmentation by applying the learned sample-independent vectors to the available objects when training a model. We conduct extensive experiments across a variety of scenarios on data from KITTI, Waymo, and CrashD for 3D object detection, and on data from SemanticKITTI, Waymo, and nuScenes for 3D semantic segmentation. Despite training on a standard single dataset, our approach substantially improves the robustness and generalization of both 3D object detection and 3D semantic segmentation methods to out-of-domain data.
Monocular 3D Object Detection with LiDAR Guided Semi Supervised Active Learning
Jul 17, 2023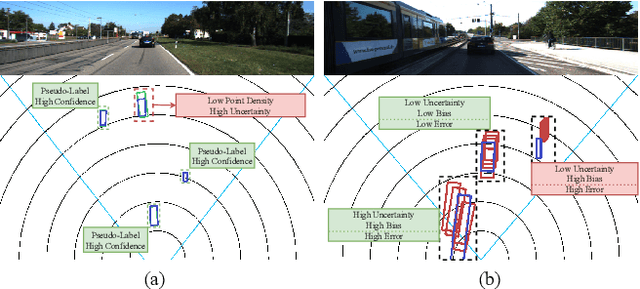
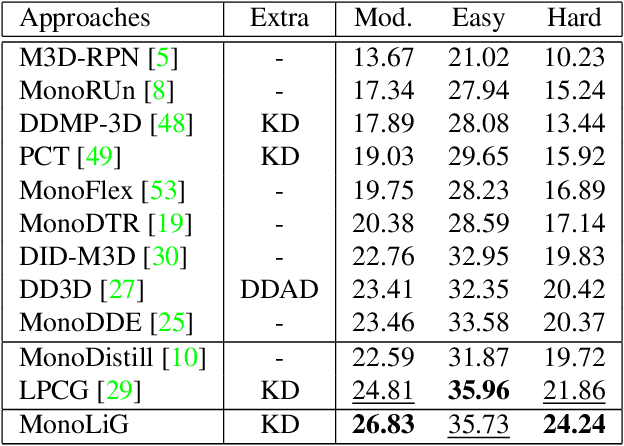
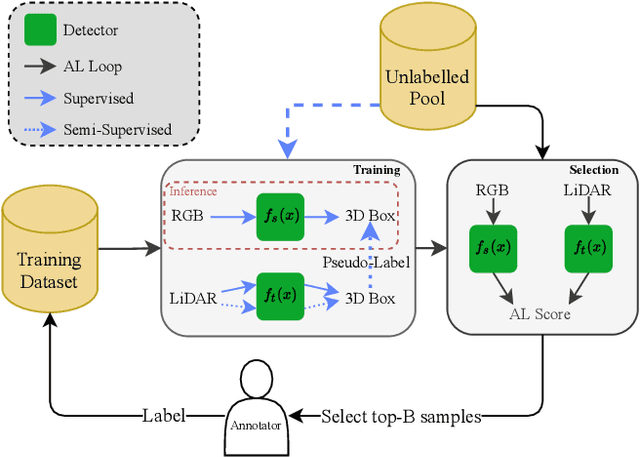
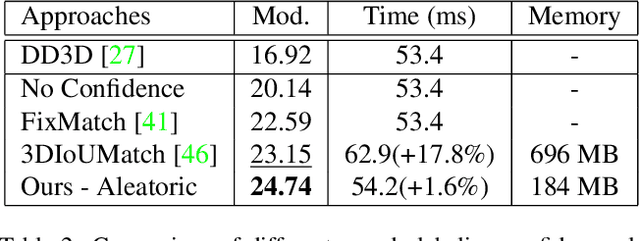
We propose a novel semi-supervised active learning (SSAL) framework for monocular 3D object detection with LiDAR guidance (MonoLiG), which leverages all modalities of collected data during model development. We utilize LiDAR to guide the data selection and training of monocular 3D detectors without introducing any overhead in the inference phase. During training, we leverage the LiDAR teacher, monocular student cross-modal framework from semi-supervised learning to distill information from unlabeled data as pseudo-labels. To handle the differences in sensor characteristics, we propose a data noise-based weighting mechanism to reduce the effect of propagating noise from LiDAR modality to monocular. For selecting which samples to label to improve the model performance, we propose a sensor consistency-based selection score that is also coherent with the training objective. Extensive experimental results on KITTI and Waymo datasets verify the effectiveness of our proposed framework. In particular, our selection strategy consistently outperforms state-of-the-art active learning baselines, yielding up to 17% better saving rate in labeling costs. Our training strategy attains the top place in KITTI 3D and birds-eye-view (BEV) monocular object detection official benchmarks by improving the BEV Average Precision (AP) by 2.02.
Active Learning for Object Detection with Non-Redundant Informative Sampling
Jul 17, 2023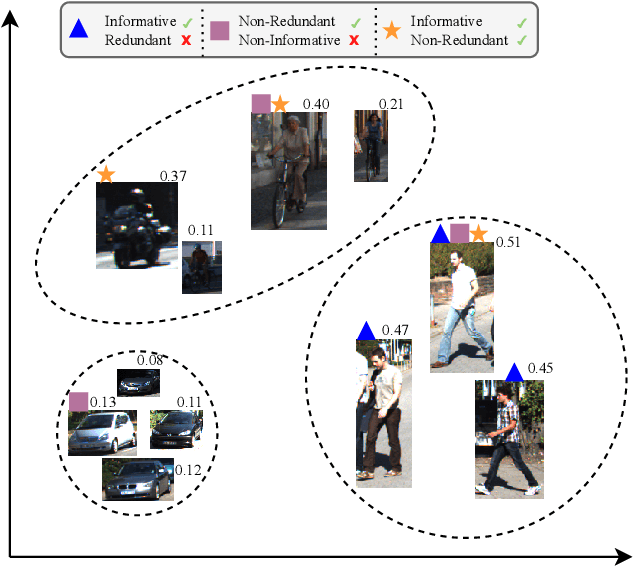



Curating an informative and representative dataset is essential for enhancing the performance of 2D object detectors. We present a novel active learning sampling strategy that addresses both the informativeness and diversity of the selections. Our strategy integrates uncertainty and diversity-based selection principles into a joint selection objective by measuring the collective information score of the selected samples. Specifically, our proposed NORIS algorithm quantifies the impact of training with a sample on the informativeness of other similar samples. By exclusively selecting samples that are simultaneously informative and distant from other highly informative samples, we effectively avoid redundancy while maintaining a high level of informativeness. Moreover, instead of utilizing whole image features to calculate distances between samples, we leverage features extracted from detected object regions within images to define object features. This allows us to construct a dataset encompassing diverse object types, shapes, and angles. Extensive experiments on object detection and image classification tasks demonstrate the effectiveness of our strategy over the state-of-the-art baselines. Specifically, our selection strategy achieves a 20% and 30% reduction in labeling costs compared to random selection for PASCAL-VOC and KITTI, respectively.
Multi-Task Consistency for Active Learning
Jun 21, 2023



Learning-based solutions for vision tasks require a large amount of labeled training data to ensure their performance and reliability. In single-task vision-based settings, inconsistency-based active learning has proven to be effective in selecting informative samples for annotation. However, there is a lack of research exploiting the inconsistency between multiple tasks in multi-task networks. To address this gap, we propose a novel multi-task active learning strategy for two coupled vision tasks: object detection and semantic segmentation. Our approach leverages the inconsistency between them to identify informative samples across both tasks. We propose three constraints that specify how the tasks are coupled and introduce a method for determining the pixels belonging to the object detected by a bounding box, to later quantify the constraints as inconsistency scores. To evaluate the effectiveness of our approach, we establish multiple baselines for multi-task active learning and introduce a new metric, mean Detection Segmentation Quality (mDSQ), tailored for the multi-task active learning comparison that addresses the performance of both tasks. We conduct extensive experiments on the nuImages and A9 datasets, demonstrating that our approach outperforms existing state-of-the-art methods by up to 3.4% mDSQ on nuImages. Our approach achieves 95% of the fully-trained performance using only 67% of the available data, corresponding to 20% fewer labels compared to random selection and 5% fewer labels compared to state-of-the-art selection strategy. Our code will be made publicly available after the review process.
3D-VField: Learning to Adversarially Deform Point Clouds for Robust 3D Object Detection
Dec 09, 2021
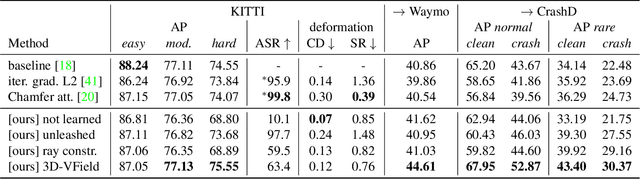
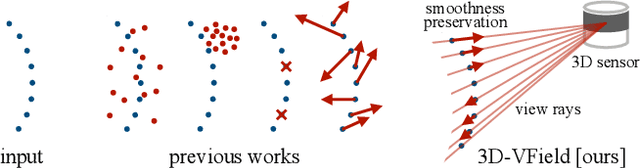

As 3D object detection on point clouds relies on the geometrical relationships between the points, non-standard object shapes can hinder a method's detection capability. However, in safety-critical settings, robustness on out-of-distribution and long-tail samples is fundamental to circumvent dangerous issues, such as the misdetection of damaged or rare cars. In this work, we substantially improve the generalization of 3D object detectors to out-of-domain data by taking into account deformed point clouds during training. We achieve this with 3D-VField: a novel method that plausibly deforms objects via vectors learned in an adversarial fashion. Our approach constrains 3D points to slide along their sensor view rays while neither adding nor removing any of them. The obtained vectors are transferrable, sample-independent and preserve shape smoothness and occlusions. By augmenting normal samples with the deformations produced by these vector fields during training, we significantly improve robustness against differently shaped objects, such as damaged/deformed cars, even while training only on KITTI. Towards this end, we propose and share open source CrashD: a synthetic dataset of realistic damaged and rare cars, with a variety of crash scenarios. Extensive experiments on KITTI, Waymo, our CrashD and SUN RGB-D show the high generalizability of our techniques to out-of-domain data, different models and sensors, namely LiDAR and ToF cameras, for both indoor and outdoor scenes. Our CrashD dataset is available at https://crashd-cars.github.io.