 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeActive Learning for Object Detection with Non-Redundant Informative Sampling
Jul 17, 2023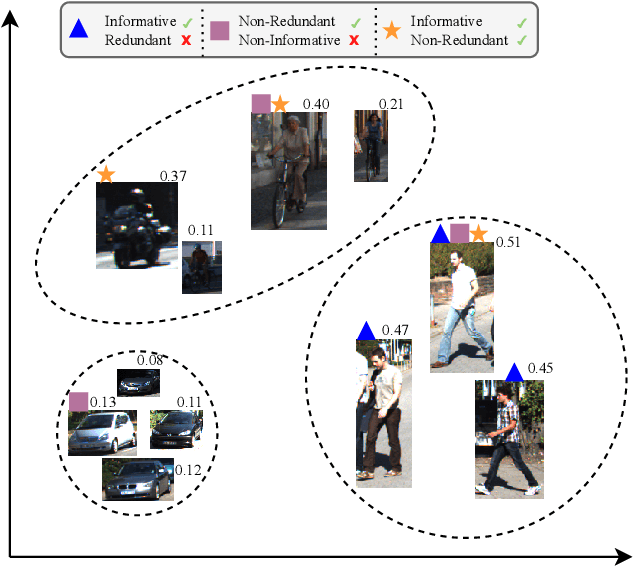



Curating an informative and representative dataset is essential for enhancing the performance of 2D object detectors. We present a novel active learning sampling strategy that addresses both the informativeness and diversity of the selections. Our strategy integrates uncertainty and diversity-based selection principles into a joint selection objective by measuring the collective information score of the selected samples. Specifically, our proposed NORIS algorithm quantifies the impact of training with a sample on the informativeness of other similar samples. By exclusively selecting samples that are simultaneously informative and distant from other highly informative samples, we effectively avoid redundancy while maintaining a high level of informativeness. Moreover, instead of utilizing whole image features to calculate distances between samples, we leverage features extracted from detected object regions within images to define object features. This allows us to construct a dataset encompassing diverse object types, shapes, and angles. Extensive experiments on object detection and image classification tasks demonstrate the effectiveness of our strategy over the state-of-the-art baselines. Specifically, our selection strategy achieves a 20% and 30% reduction in labeling costs compared to random selection for PASCAL-VOC and KITTI, respectively.
Monocular 3D Object Detection with LiDAR Guided Semi Supervised Active Learning
Jul 17, 2023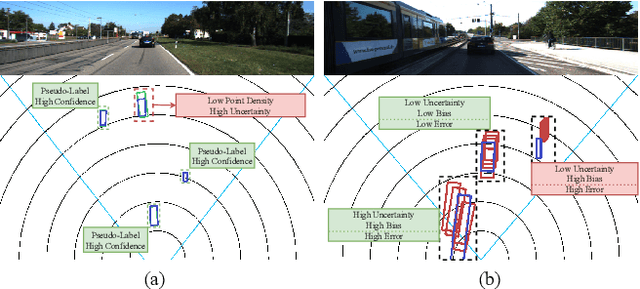
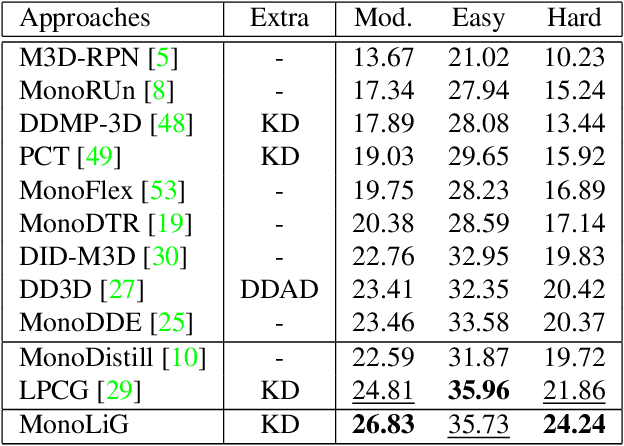
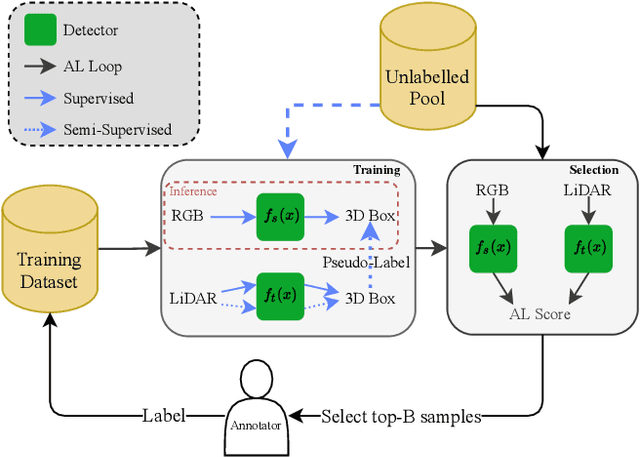
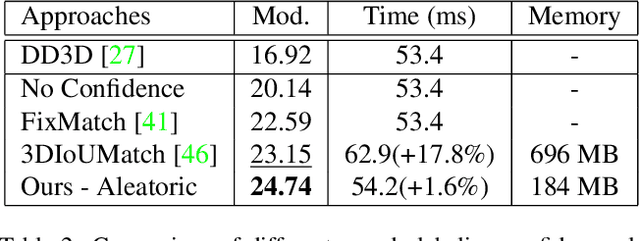
We propose a novel semi-supervised active learning (SSAL) framework for monocular 3D object detection with LiDAR guidance (MonoLiG), which leverages all modalities of collected data during model development. We utilize LiDAR to guide the data selection and training of monocular 3D detectors without introducing any overhead in the inference phase. During training, we leverage the LiDAR teacher, monocular student cross-modal framework from semi-supervised learning to distill information from unlabeled data as pseudo-labels. To handle the differences in sensor characteristics, we propose a data noise-based weighting mechanism to reduce the effect of propagating noise from LiDAR modality to monocular. For selecting which samples to label to improve the model performance, we propose a sensor consistency-based selection score that is also coherent with the training objective. Extensive experimental results on KITTI and Waymo datasets verify the effectiveness of our proposed framework. In particular, our selection strategy consistently outperforms state-of-the-art active learning baselines, yielding up to 17% better saving rate in labeling costs. Our training strategy attains the top place in KITTI 3D and birds-eye-view (BEV) monocular object detection official benchmarks by improving the BEV Average Precision (AP) by 2.02.
Multi-Task Consistency for Active Learning
Jun 21, 2023



Learning-based solutions for vision tasks require a large amount of labeled training data to ensure their performance and reliability. In single-task vision-based settings, inconsistency-based active learning has proven to be effective in selecting informative samples for annotation. However, there is a lack of research exploiting the inconsistency between multiple tasks in multi-task networks. To address this gap, we propose a novel multi-task active learning strategy for two coupled vision tasks: object detection and semantic segmentation. Our approach leverages the inconsistency between them to identify informative samples across both tasks. We propose three constraints that specify how the tasks are coupled and introduce a method for determining the pixels belonging to the object detected by a bounding box, to later quantify the constraints as inconsistency scores. To evaluate the effectiveness of our approach, we establish multiple baselines for multi-task active learning and introduce a new metric, mean Detection Segmentation Quality (mDSQ), tailored for the multi-task active learning comparison that addresses the performance of both tasks. We conduct extensive experiments on the nuImages and A9 datasets, demonstrating that our approach outperforms existing state-of-the-art methods by up to 3.4% mDSQ on nuImages. Our approach achieves 95% of the fully-trained performance using only 67% of the available data, corresponding to 20% fewer labels compared to random selection and 5% fewer labels compared to state-of-the-art selection strategy. Our code will be made publicly available after the review process.