 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNaviHydra: Controllable Navigation-guided End-to-end Autonomous Driving with Hydra-distillation
Dec 11, 2025



The complexity of autonomous driving scenarios requires robust models that can interpret high-level navigation commands and generate safe trajectories. While traditional rule-based systems can react to these commands, they often struggle in dynamic environments, and end-to-end methods face challenges in complying with explicit navigation commands. To address this, we present NaviHydra, a controllable navigation-guided end-to-end model distilled from an existing rule-based simulator. Our framework accepts high-level navigation commands as control signals, generating trajectories that align with specified intentions. We utilize a Bird's Eye View (BEV) based trajectory gathering method to enhance the trajectory feature extraction. Additionally, we introduce a novel navigation compliance metric to evaluate adherence to intended route, improving controllability and navigation safety. To comprehensively assess our model's controllability, we design a test that evaluates its response to various navigation commands. Our method significantly outperforms baseline models, achieving state-of-the-art results in the NAVSIM benchmark, demonstrating its effectiveness in advancing autonomous driving.
3D Adversarial Augmentations for Robust Out-of-Domain Predictions
Aug 29, 2023Since real-world training datasets cannot properly sample the long tail of the underlying data distribution, corner cases and rare out-of-domain samples can severely hinder the performance of state-of-the-art models. This problem becomes even more severe for dense tasks, such as 3D semantic segmentation, where points of non-standard objects can be confidently associated to the wrong class. In this work, we focus on improving the generalization to out-of-domain data. We achieve this by augmenting the training set with adversarial examples. First, we learn a set of vectors that deform the objects in an adversarial fashion. To prevent the adversarial examples from being too far from the existing data distribution, we preserve their plausibility through a series of constraints, ensuring sensor-awareness and shapes smoothness. Then, we perform adversarial augmentation by applying the learned sample-independent vectors to the available objects when training a model. We conduct extensive experiments across a variety of scenarios on data from KITTI, Waymo, and CrashD for 3D object detection, and on data from SemanticKITTI, Waymo, and nuScenes for 3D semantic segmentation. Despite training on a standard single dataset, our approach substantially improves the robustness and generalization of both 3D object detection and 3D semantic segmentation methods to out-of-domain data.
Active Learning for Object Detection with Non-Redundant Informative Sampling
Jul 17, 2023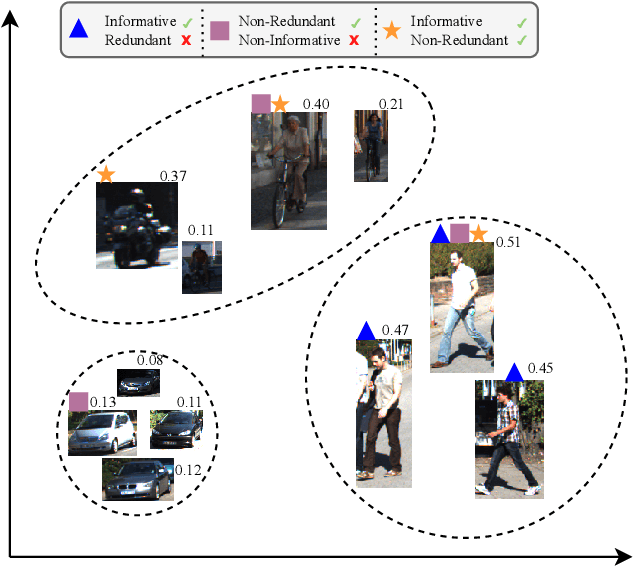



Curating an informative and representative dataset is essential for enhancing the performance of 2D object detectors. We present a novel active learning sampling strategy that addresses both the informativeness and diversity of the selections. Our strategy integrates uncertainty and diversity-based selection principles into a joint selection objective by measuring the collective information score of the selected samples. Specifically, our proposed NORIS algorithm quantifies the impact of training with a sample on the informativeness of other similar samples. By exclusively selecting samples that are simultaneously informative and distant from other highly informative samples, we effectively avoid redundancy while maintaining a high level of informativeness. Moreover, instead of utilizing whole image features to calculate distances between samples, we leverage features extracted from detected object regions within images to define object features. This allows us to construct a dataset encompassing diverse object types, shapes, and angles. Extensive experiments on object detection and image classification tasks demonstrate the effectiveness of our strategy over the state-of-the-art baselines. Specifically, our selection strategy achieves a 20% and 30% reduction in labeling costs compared to random selection for PASCAL-VOC and KITTI, respectively.
Monocular 3D Object Detection with LiDAR Guided Semi Supervised Active Learning
Jul 17, 2023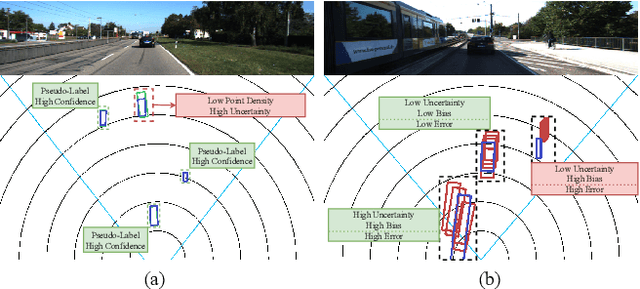
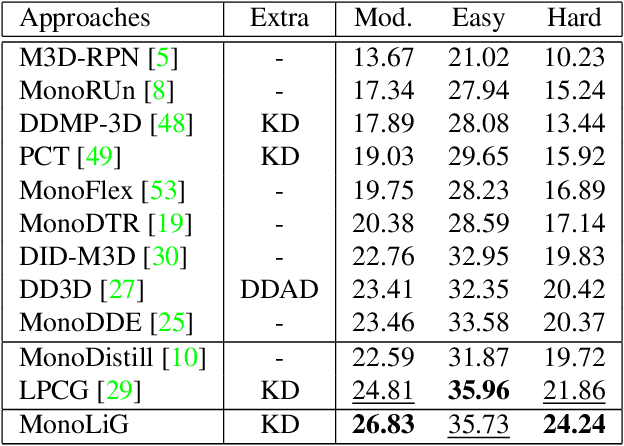
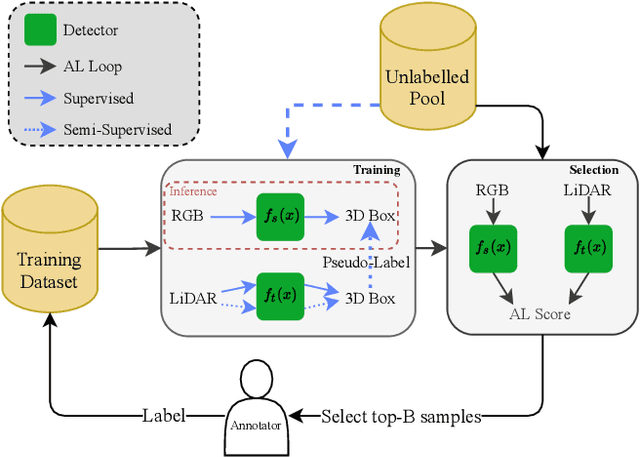
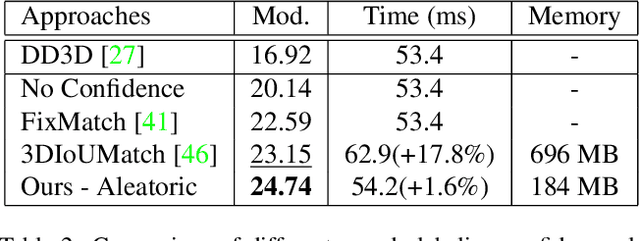
We propose a novel semi-supervised active learning (SSAL) framework for monocular 3D object detection with LiDAR guidance (MonoLiG), which leverages all modalities of collected data during model development. We utilize LiDAR to guide the data selection and training of monocular 3D detectors without introducing any overhead in the inference phase. During training, we leverage the LiDAR teacher, monocular student cross-modal framework from semi-supervised learning to distill information from unlabeled data as pseudo-labels. To handle the differences in sensor characteristics, we propose a data noise-based weighting mechanism to reduce the effect of propagating noise from LiDAR modality to monocular. For selecting which samples to label to improve the model performance, we propose a sensor consistency-based selection score that is also coherent with the training objective. Extensive experimental results on KITTI and Waymo datasets verify the effectiveness of our proposed framework. In particular, our selection strategy consistently outperforms state-of-the-art active learning baselines, yielding up to 17% better saving rate in labeling costs. Our training strategy attains the top place in KITTI 3D and birds-eye-view (BEV) monocular object detection official benchmarks by improving the BEV Average Precision (AP) by 2.02.
Multi-Task Consistency for Active Learning
Jun 21, 2023



Learning-based solutions for vision tasks require a large amount of labeled training data to ensure their performance and reliability. In single-task vision-based settings, inconsistency-based active learning has proven to be effective in selecting informative samples for annotation. However, there is a lack of research exploiting the inconsistency between multiple tasks in multi-task networks. To address this gap, we propose a novel multi-task active learning strategy for two coupled vision tasks: object detection and semantic segmentation. Our approach leverages the inconsistency between them to identify informative samples across both tasks. We propose three constraints that specify how the tasks are coupled and introduce a method for determining the pixels belonging to the object detected by a bounding box, to later quantify the constraints as inconsistency scores. To evaluate the effectiveness of our approach, we establish multiple baselines for multi-task active learning and introduce a new metric, mean Detection Segmentation Quality (mDSQ), tailored for the multi-task active learning comparison that addresses the performance of both tasks. We conduct extensive experiments on the nuImages and A9 datasets, demonstrating that our approach outperforms existing state-of-the-art methods by up to 3.4% mDSQ on nuImages. Our approach achieves 95% of the fully-trained performance using only 67% of the available data, corresponding to 20% fewer labels compared to random selection and 5% fewer labels compared to state-of-the-art selection strategy. Our code will be made publicly available after the review process.
Holistic Segmentation
Sep 12, 2022
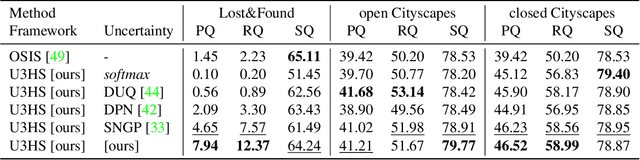
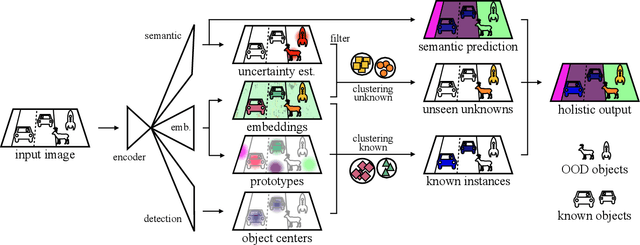

As panoptic segmentation provides a prediction for every pixel in input, non-standard and unseen objects systematically lead to wrong outputs. However, in safety-critical settings, robustness against out-of-distribution samples and corner cases is crucial to avoid dangerous behaviors, such as ignoring an animal or a lost cargo on the road. Since driving datasets cannot contain enough data points to properly sample the long tail of the underlying distribution, a method must deal with unknown and unseen scenarios to be deployed safely. Previous methods targeted part of this issue, by re-identifying already seen unlabeled objects. In this work, we broaden the scope proposing holistic segmentation: a task to identify and separate unseen unknown objects into instances, without learning from unknowns, while performing panoptic segmentation of known classes. We tackle this new problem with U3HS, which first finds unknowns as highly uncertain regions, then clusters the corresponding instance-aware embeddings into individual objects. By doing so, for the first time in panoptic segmentation with unknown objects, our U3HS is not trained with unknown data, thus leaving the settings unconstrained with respect to the type of objects and allowing for a holistic scene understanding. Extensive experiments and comparisons on two public datasets, namely Cityscapes and Lost&Found as a transfer, demonstrate the effectiveness of U3HS in the challenging task of holistic segmentation, with competitive closed-set panoptic segmentation performance.
3D-VField: Learning to Adversarially Deform Point Clouds for Robust 3D Object Detection
Dec 09, 2021
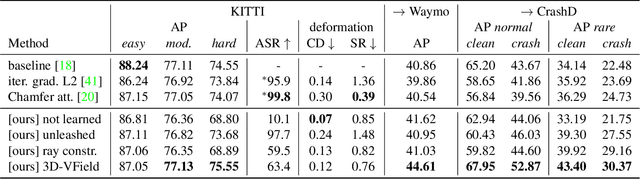
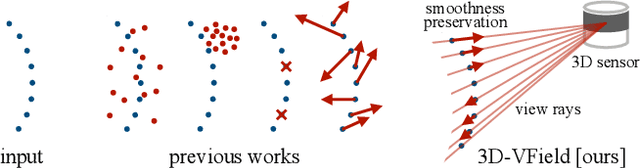

As 3D object detection on point clouds relies on the geometrical relationships between the points, non-standard object shapes can hinder a method's detection capability. However, in safety-critical settings, robustness on out-of-distribution and long-tail samples is fundamental to circumvent dangerous issues, such as the misdetection of damaged or rare cars. In this work, we substantially improve the generalization of 3D object detectors to out-of-domain data by taking into account deformed point clouds during training. We achieve this with 3D-VField: a novel method that plausibly deforms objects via vectors learned in an adversarial fashion. Our approach constrains 3D points to slide along their sensor view rays while neither adding nor removing any of them. The obtained vectors are transferrable, sample-independent and preserve shape smoothness and occlusions. By augmenting normal samples with the deformations produced by these vector fields during training, we significantly improve robustness against differently shaped objects, such as damaged/deformed cars, even while training only on KITTI. Towards this end, we propose and share open source CrashD: a synthetic dataset of realistic damaged and rare cars, with a variety of crash scenarios. Extensive experiments on KITTI, Waymo, our CrashD and SUN RGB-D show the high generalizability of our techniques to out-of-domain data, different models and sensors, namely LiDAR and ToF cameras, for both indoor and outdoor scenes. Our CrashD dataset is available at https://crashd-cars.github.io.
CertainNet: Sampling-free Uncertainty Estimation for Object Detection
Oct 04, 2021
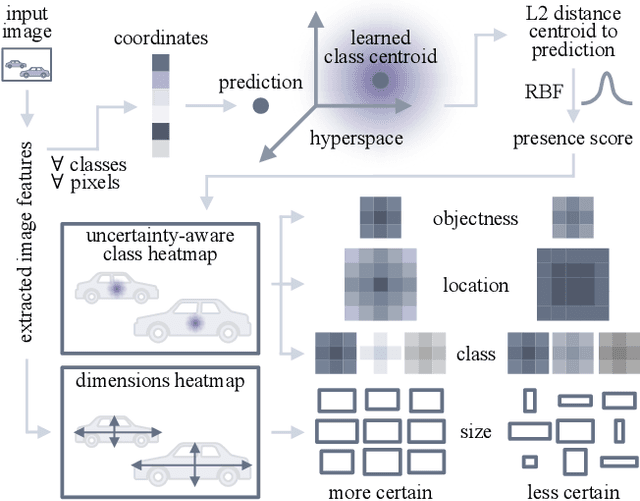
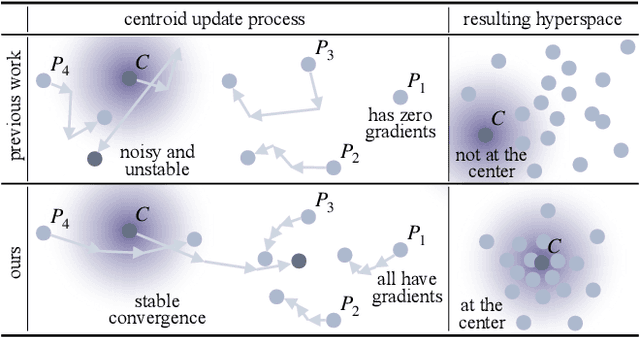
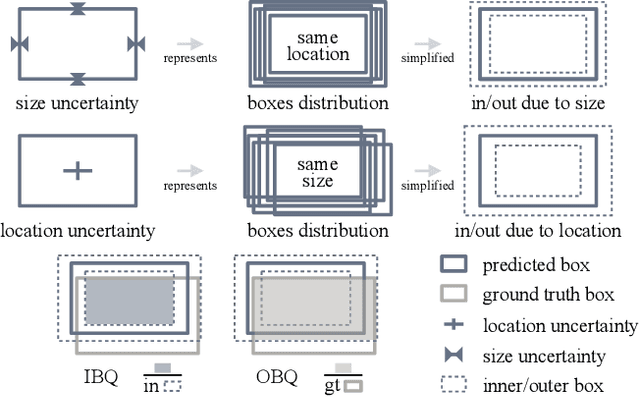
Estimating the uncertainty of a neural network plays a fundamental role in safety-critical settings. In perception for autonomous driving, measuring the uncertainty means providing additional calibrated information to downstream tasks, such as path planning, that can use it towards safe navigation. In this work, we propose a novel sampling-free uncertainty estimation method for object detection. We call it CertainNet, and it is the first to provide separate uncertainties for each output signal: objectness, class, location and size. To achieve this, we propose an uncertainty-aware heatmap, and exploit the neighboring bounding boxes provided by the detector at inference time. We evaluate the detection performance and the quality of the different uncertainty estimates separately, also with challenging out-of-domain samples: BDD100K and nuImages with models trained on KITTI. Additionally, we propose a new metric to evaluate location and size uncertainties. When transferring to unseen datasets, CertainNet generalizes substantially better than previous methods and an ensemble, while being real-time and providing high quality and comprehensive uncertainty estimates.
Panoster: End-to-end Panoptic Segmentation of LiDAR Point Clouds
Oct 28, 2020
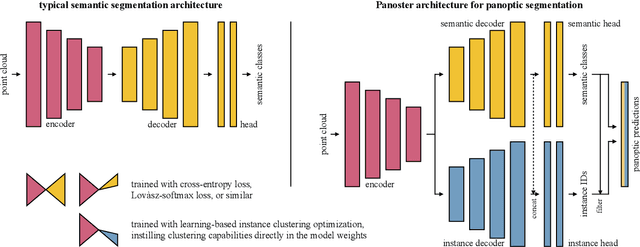


Panoptic segmentation has recently unified semantic and instance segmentation, previously addressed separately, thus taking a step further towards creating more comprehensive and efficient perception systems. In this paper, we present Panoster, a novel proposal-free panoptic segmentation method for point clouds. Unlike previous approaches relying on several steps to group pixels or points into objects, Panoster proposes a simplified framework incorporating a learning-based clustering solution to identify instances. At inference time, this acts as a class-agnostic semantic segmentation, allowing Panoster to be fast, while outperforming prior methods in terms of accuracy. Additionally, we showcase how our approach can be flexibly and effectively applied on diverse existing semantic architectures to deliver panoptic predictions.