 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePathoGen: Diffusion-Based Synthesis of Realistic Lesions in Histopathology Images
Jan 13, 2026The development of robust artificial intelligence models for histopathology diagnosis is severely constrained by the scarcity of expert-annotated lesion data, particularly for rare pathologies and underrepresented disease subtypes. While data augmentation offers a potential solution, existing methods fail to generate sufficiently realistic lesion morphologies that preserve the complex spatial relationships and cellular architectures characteristic of histopathological tissues. Here we present PathoGen, a diffusion-based generative model that enables controllable, high-fidelity inpainting of lesions into benign histopathology images. Unlike conventional augmentation techniques, PathoGen leverages the iterative refinement process of diffusion models to synthesize lesions with natural tissue boundaries, preserved cellular structures, and authentic staining characteristics. We validate PathoGen across four diverse datasets representing distinct diagnostic challenges: kidney, skin, breast, and prostate pathology. Quantitative assessment confirms that PathoGen outperforms state-of-the-art generative baselines, including conditional GAN and Stable Diffusion, in image fidelity and distributional similarity. Crucially, we show that augmenting training sets with PathoGen-synthesized lesions enhances downstream segmentation performance compared to traditional geometric augmentations, particularly in data-scarce regimes. Besides, by simultaneously generating realistic morphology and pixel-level ground truth, PathoGen effectively overcomes the manual annotation bottleneck. This approach offers a scalable pathway for developing generalizable medical AI systems despite limited expert-labeled data.
Enhancing Out-of-Distribution Detection in Medical Imaging with Normalizing Flows
Feb 17, 2025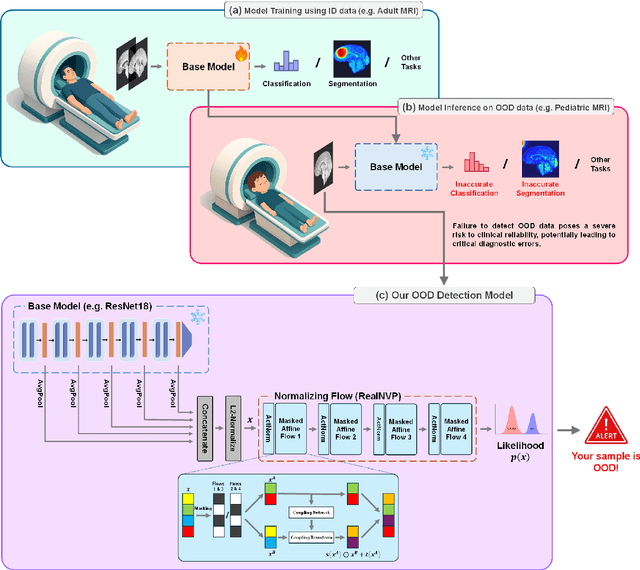
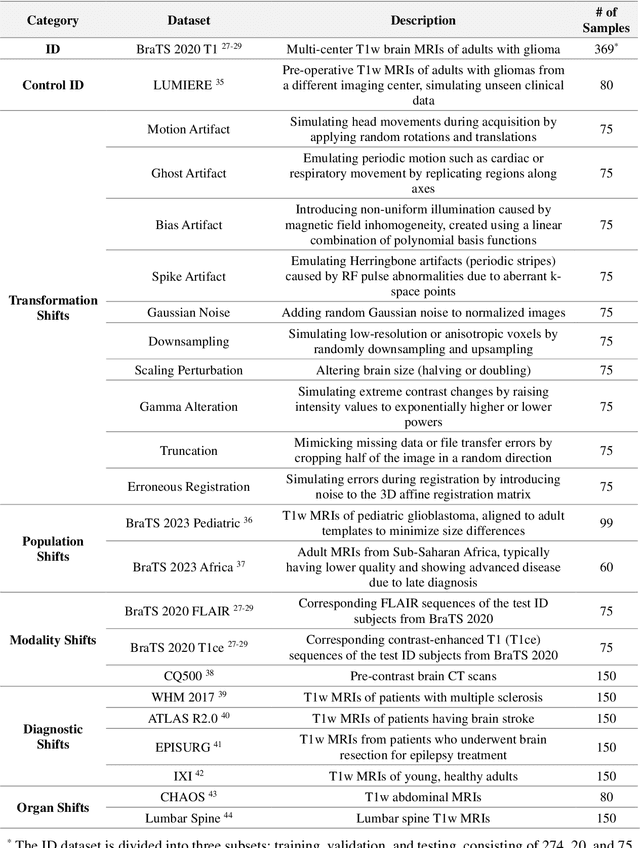
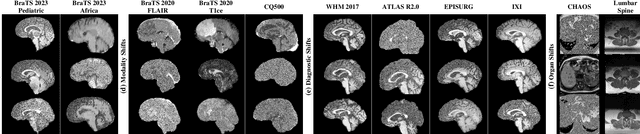
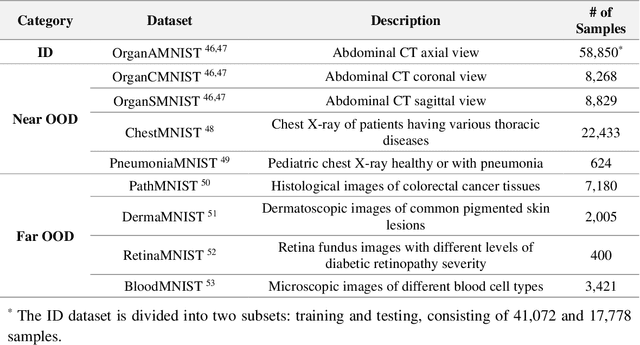
Out-of-distribution (OOD) detection is crucial in AI-driven medical imaging to ensure reliability and safety by identifying inputs outside a model's training distribution. Existing methods often require retraining or modifications to pre-trained models, which is impractical for clinical applications. This study introduces a post-hoc normalizing flow-based approach that seamlessly integrates with pre-trained models. By leveraging normalizing flows, it estimates the likelihood of feature vectors extracted from pre-trained models, capturing semantically meaningful representations without relying on pixel-level statistics. The method was evaluated using the MedMNIST benchmark and a newly curated MedOOD dataset simulating clinically relevant distributional shifts. Performance was measured using standard OOD detection metrics (e.g., AUROC, FPR@95, AUPR_IN, AUPR_OUT), with statistical analyses comparing it against ten baseline methods. On MedMNIST, the proposed model achieved an AUROC of 93.80%, outperforming state-of-the-art methods. On MedOOD, it achieved an AUROC of 84.61%, demonstrating superior performance against other methods. Its post-hoc nature ensures compatibility with existing clinical workflows, addressing the limitations of previous approaches. The model and code to build OOD datasets are available at https://github.com/dlotfi/MedOODFlow.
RMS-FlowNet: Efficient and Robust Multi-Scale Scene Flow Estimation for Large-Scale Point Clouds
Apr 01, 2022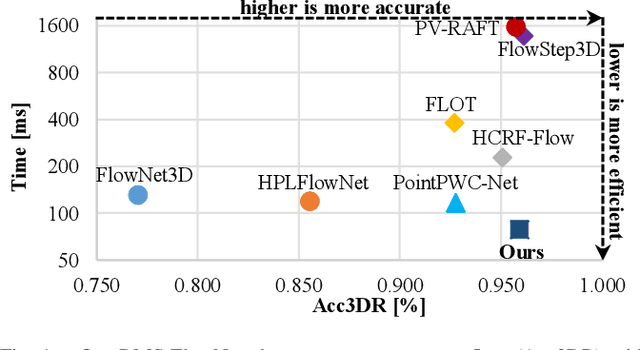
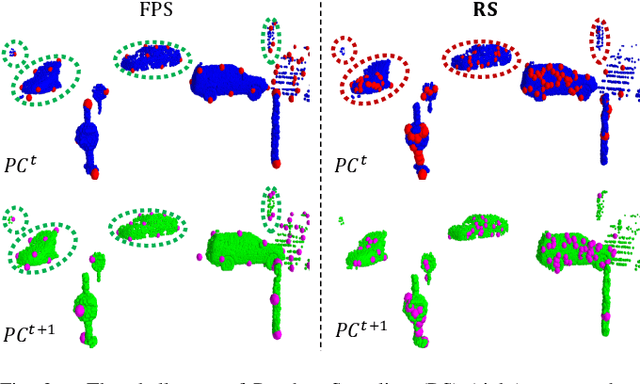
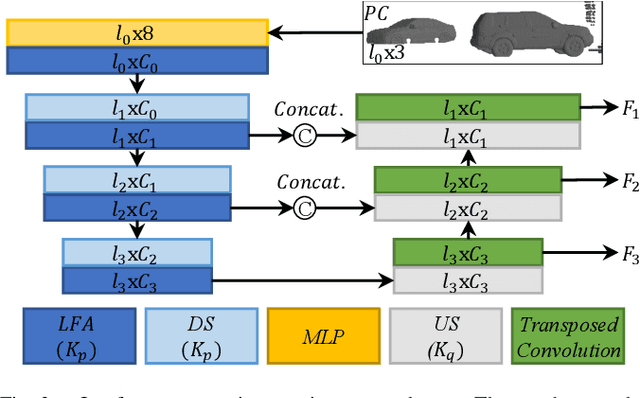
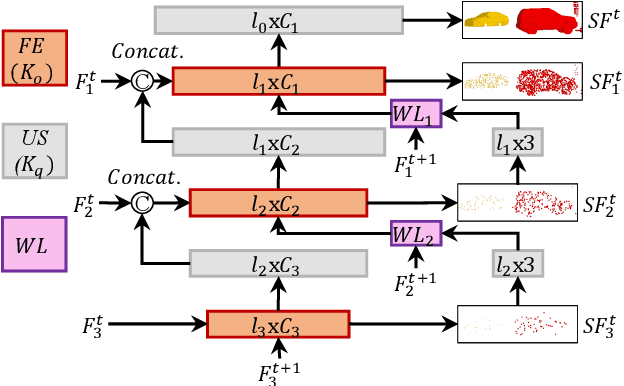
The proposed RMS-FlowNet is a novel end-to-end learning-based architecture for accurate and efficient scene flow estimation which can operate on point clouds of high density. For hierarchical scene flow estimation, the existing methods depend on either expensive Farthest-Point-Sampling (FPS) or structure-based scaling which decrease their ability to handle a large number of points. Unlike these methods, we base our fully supervised architecture on Random-Sampling (RS) for multiscale scene flow prediction. To this end, we propose a novel flow embedding design which can predict more robust scene flow in conjunction with RS. Exhibiting high accuracy, our RMS-FlowNet provides a faster prediction than state-of-the-art methods and works efficiently on consecutive dense point clouds of more than 250K points at once. Our comprehensive experiments verify the accuracy of RMS-FlowNet on the established FlyingThings3D data set with different point cloud densities and validate our design choices. Additionally, we show that our model presents a competitive ability to generalize towards the real-world scenes of KITTI data set without fine-tuning.
3D-VField: Learning to Adversarially Deform Point Clouds for Robust 3D Object Detection
Dec 09, 2021
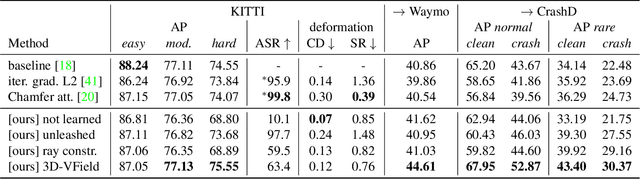
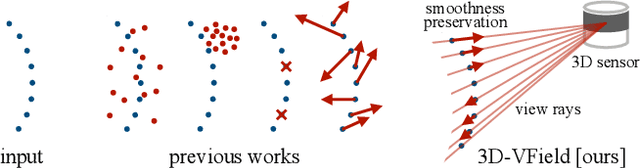

As 3D object detection on point clouds relies on the geometrical relationships between the points, non-standard object shapes can hinder a method's detection capability. However, in safety-critical settings, robustness on out-of-distribution and long-tail samples is fundamental to circumvent dangerous issues, such as the misdetection of damaged or rare cars. In this work, we substantially improve the generalization of 3D object detectors to out-of-domain data by taking into account deformed point clouds during training. We achieve this with 3D-VField: a novel method that plausibly deforms objects via vectors learned in an adversarial fashion. Our approach constrains 3D points to slide along their sensor view rays while neither adding nor removing any of them. The obtained vectors are transferrable, sample-independent and preserve shape smoothness and occlusions. By augmenting normal samples with the deformations produced by these vector fields during training, we significantly improve robustness against differently shaped objects, such as damaged/deformed cars, even while training only on KITTI. Towards this end, we propose and share open source CrashD: a synthetic dataset of realistic damaged and rare cars, with a variety of crash scenarios. Extensive experiments on KITTI, Waymo, our CrashD and SUN RGB-D show the high generalizability of our techniques to out-of-domain data, different models and sensors, namely LiDAR and ToF cameras, for both indoor and outdoor scenes. Our CrashD dataset is available at https://crashd-cars.github.io.
CertainNet: Sampling-free Uncertainty Estimation for Object Detection
Oct 04, 2021
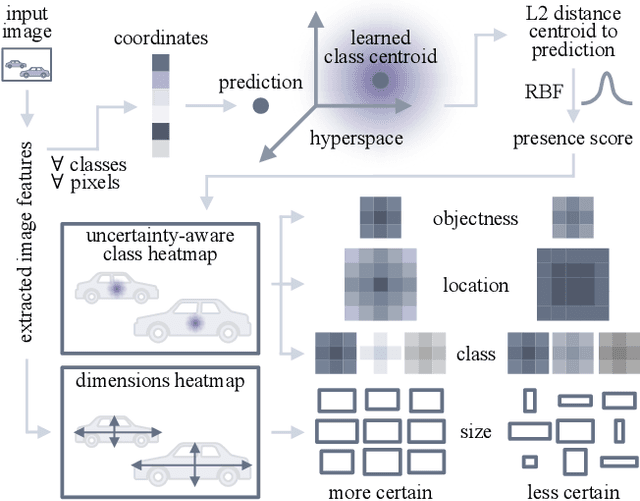
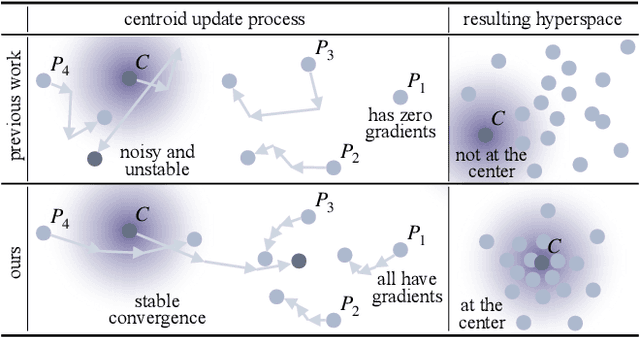
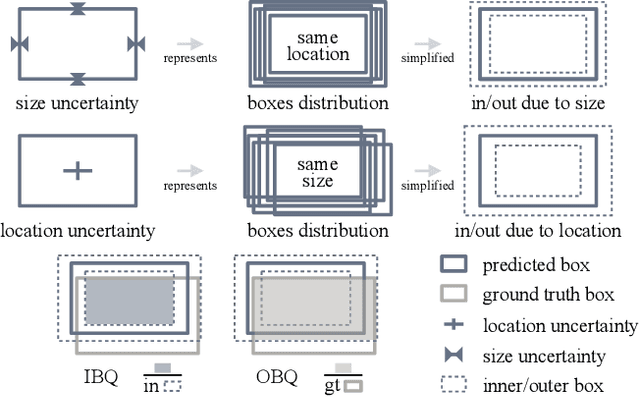
Estimating the uncertainty of a neural network plays a fundamental role in safety-critical settings. In perception for autonomous driving, measuring the uncertainty means providing additional calibrated information to downstream tasks, such as path planning, that can use it towards safe navigation. In this work, we propose a novel sampling-free uncertainty estimation method for object detection. We call it CertainNet, and it is the first to provide separate uncertainties for each output signal: objectness, class, location and size. To achieve this, we propose an uncertainty-aware heatmap, and exploit the neighboring bounding boxes provided by the detector at inference time. We evaluate the detection performance and the quality of the different uncertainty estimates separately, also with challenging out-of-domain samples: BDD100K and nuImages with models trained on KITTI. Additionally, we propose a new metric to evaluate location and size uncertainties. When transferring to unseen datasets, CertainNet generalizes substantially better than previous methods and an ensemble, while being real-time and providing high quality and comprehensive uncertainty estimates.
Panoster: End-to-end Panoptic Segmentation of LiDAR Point Clouds
Oct 28, 2020
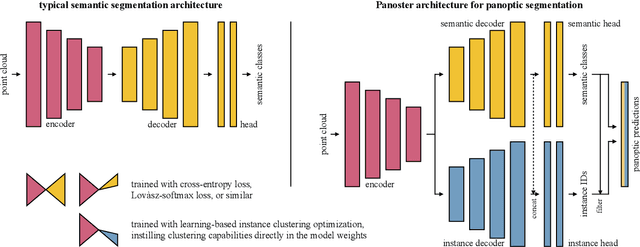


Panoptic segmentation has recently unified semantic and instance segmentation, previously addressed separately, thus taking a step further towards creating more comprehensive and efficient perception systems. In this paper, we present Panoster, a novel proposal-free panoptic segmentation method for point clouds. Unlike previous approaches relying on several steps to group pixels or points into objects, Panoster proposes a simplified framework incorporating a learning-based clustering solution to identify instances. At inference time, this acts as a class-agnostic semantic segmentation, allowing Panoster to be fast, while outperforming prior methods in terms of accuracy. Additionally, we showcase how our approach can be flexibly and effectively applied on diverse existing semantic architectures to deliver panoptic predictions.