 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGALA: Guided Attention with Language Alignment for Open Vocabulary Gaussian Splatting
Aug 21, 2025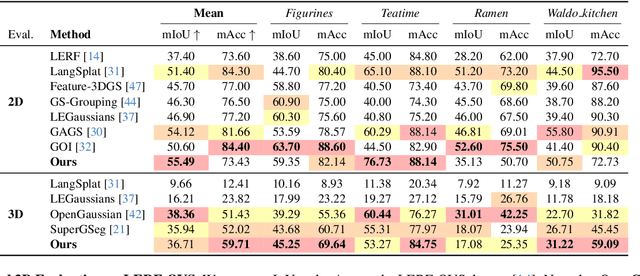
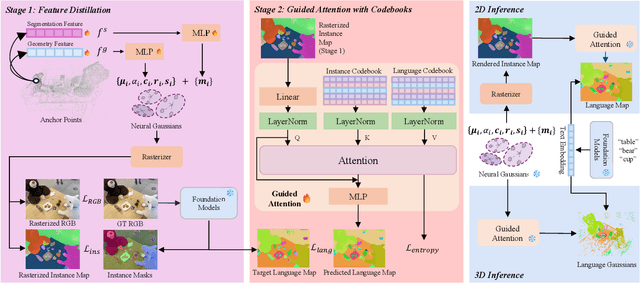
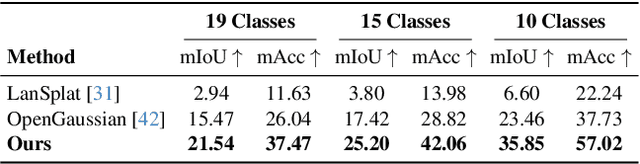

3D scene reconstruction and understanding have gained increasing popularity, yet existing methods still struggle to capture fine-grained, language-aware 3D representations from 2D images. In this paper, we present GALA, a novel framework for open-vocabulary 3D scene understanding with 3D Gaussian Splatting (3DGS). GALA distills a scene-specific 3D instance feature field via self-supervised contrastive learning. To extend to generalized language feature fields, we introduce the core contribution of GALA, a cross-attention module with two learnable codebooks that encode view-independent semantic embeddings. This design not only ensures intra-instance feature similarity but also supports seamless 2D and 3D open-vocabulary queries. It reduces memory consumption by avoiding per-Gaussian high-dimensional feature learning. Extensive experiments on real-world datasets demonstrate GALA's remarkable open-vocabulary performance on both 2D and 3D.
Prior2Former -- Evidential Modeling of Mask Transformers for Assumption-Free Open-World Panoptic Segmentation
Apr 07, 2025In panoptic segmentation, individual instances must be separated within semantic classes. As state-of-the-art methods rely on a pre-defined set of classes, they struggle with novel categories and out-of-distribution (OOD) data. This is particularly problematic in safety-critical applications, such as autonomous driving, where reliability in unseen scenarios is essential. We address the gap between outstanding benchmark performance and reliability by proposing Prior2Former (P2F), the first approach for segmentation vision transformers rooted in evidential learning. P2F extends the mask vision transformer architecture by incorporating a Beta prior for computing model uncertainty in pixel-wise binary mask assignments. This design enables high-quality uncertainty estimation that effectively detects novel and OOD objects enabling state-of-the-art anomaly instance segmentation and open-world panoptic segmentation. Unlike most segmentation models addressing unknown classes, P2F operates without access to OOD data samples or contrastive training on void (i.e., unlabeled) classes, making it highly applicable in real-world scenarios where such prior information is unavailable. Additionally, P2F can be flexibly applied to anomaly instance and panoptic segmentation. Through comprehensive experiments on the Cityscapes, COCO, SegmentMeIfYouCan, and OoDIS datasets, we demonstrate the state-of-the-art performance of P2F. It achieves the highest ranking in the OoDIS anomaly instance benchmark among methods not using OOD data in any way.
From Open-Vocabulary to Vocabulary-Free Semantic Segmentation
Feb 17, 2025Open-vocabulary semantic segmentation enables models to identify novel object categories beyond their training data. While this flexibility represents a significant advancement, current approaches still rely on manually specified class names as input, creating an inherent bottleneck in real-world applications. This work proposes a Vocabulary-Free Semantic Segmentation pipeline, eliminating the need for predefined class vocabularies. Specifically, we address the chicken-and-egg problem where users need knowledge of all potential objects within a scene to identify them, yet the purpose of segmentation is often to discover these objects. The proposed approach leverages Vision-Language Models to automatically recognize objects and generate appropriate class names, aiming to solve the challenge of class specification and naming quality. Through extensive experiments on several public datasets, we highlight the crucial role of the text encoder in model performance, particularly when the image text classes are paired with generated descriptions. Despite the challenges introduced by the sensitivity of the segmentation text encoder to false negatives within the class tagging process, which adds complexity to the task, we demonstrate that our fully automated pipeline significantly enhances vocabulary-free segmentation accuracy across diverse real-world scenarios.
SuperGSeg: Open-Vocabulary 3D Segmentation with Structured Super-Gaussians
Dec 13, 2024



3D Gaussian Splatting has recently gained traction for its efficient training and real-time rendering. While the vanilla Gaussian Splatting representation is mainly designed for view synthesis, more recent works investigated how to extend it with scene understanding and language features. However, existing methods lack a detailed comprehension of scenes, limiting their ability to segment and interpret complex structures. To this end, We introduce SuperGSeg, a novel approach that fosters cohesive, context-aware scene representation by disentangling segmentation and language field distillation. SuperGSeg first employs neural Gaussians to learn instance and hierarchical segmentation features from multi-view images with the aid of off-the-shelf 2D masks. These features are then leveraged to create a sparse set of what we call Super-Gaussians. Super-Gaussians facilitate the distillation of 2D language features into 3D space. Through Super-Gaussians, our method enables high-dimensional language feature rendering without extreme increases in GPU memory. Extensive experiments demonstrate that SuperGSeg outperforms prior works on both open-vocabulary object localization and semantic segmentation tasks.
Zero123-6D: Zero-shot Novel View Synthesis for RGB Category-level 6D Pose Estimation
Mar 21, 2024



Estimating the pose of objects through vision is essential to make robotic platforms interact with the environment. Yet, it presents many challenges, often related to the lack of flexibility and generalizability of state-of-the-art solutions. Diffusion models are a cutting-edge neural architecture transforming 2D and 3D computer vision, outlining remarkable performances in zero-shot novel-view synthesis. Such a use case is particularly intriguing for reconstructing 3D objects. However, localizing objects in unstructured environments is rather unexplored. To this end, this work presents Zero123-6D to demonstrate the utility of Diffusion Model-based novel-view-synthesizers in enhancing RGB 6D pose estimation at category-level by integrating them with feature extraction techniques. The outlined method exploits such a novel view synthesizer to expand a sparse set of RGB-only reference views for the zero-shot 6D pose estimation task. Experiments are quantitatively analyzed on the CO3D dataset, showcasing increased performance over baselines, a substantial reduction in data requirements, and the removal of the necessity of depth information.
Re-Nerfing: Enforcing Geometric Constraints on Neural Radiance Fields through Novel Views Synthesis
Dec 04, 2023



Neural Radiance Fields (NeRFs) have shown remarkable novel view synthesis capabilities even in large-scale, unbounded scenes, albeit requiring hundreds of views or introducing artifacts in sparser settings. Their optimization suffers from shape-radiance ambiguities wherever only a small visual overlap is available. This leads to erroneous scene geometry and artifacts. In this paper, we propose Re-Nerfing, a simple and general multi-stage approach that leverages NeRF's own view synthesis to address these limitations. With Re-Nerfing, we increase the scene's coverage and enhance the geometric consistency of novel views as follows: First, we train a NeRF with the available views. Then, we use the optimized NeRF to synthesize pseudo-views next to the original ones to simulate a stereo or trifocal setup. Finally, we train a second NeRF with both original and pseudo views while enforcing structural, epipolar constraints via the newly synthesized images. Extensive experiments on the mip-NeRF 360 dataset show the effectiveness of Re-Nerfing across denser and sparser input scenarios, bringing improvements to the state-of-the-art Zip-NeRF, even when trained with all views.
VoxNeRF: Bridging Voxel Representation and Neural Radiance Fields for Enhanced Indoor View Synthesis
Nov 09, 2023



Creating high-quality view synthesis is essential for immersive applications but continues to be problematic, particularly in indoor environments and for real-time deployment. Current techniques frequently require extensive computational time for both training and rendering, and often produce less-than-ideal 3D representations due to inadequate geometric structuring. To overcome this, we introduce VoxNeRF, a novel approach that leverages volumetric representations to enhance the quality and efficiency of indoor view synthesis. Firstly, VoxNeRF constructs a structured scene geometry and converts it into a voxel-based representation. We employ multi-resolution hash grids to adaptively capture spatial features, effectively managing occlusions and the intricate geometry of indoor scenes. Secondly, we propose a unique voxel-guided efficient sampling technique. This innovation selectively focuses computational resources on the most relevant portions of ray segments, substantially reducing optimization time. We validate our approach against three public indoor datasets and demonstrate that VoxNeRF outperforms state-of-the-art methods. Remarkably, it achieves these gains while reducing both training and rendering times, surpassing even Instant-NGP in speed and bringing the technology closer to real-time.
3D Adversarial Augmentations for Robust Out-of-Domain Predictions
Aug 29, 2023Since real-world training datasets cannot properly sample the long tail of the underlying data distribution, corner cases and rare out-of-domain samples can severely hinder the performance of state-of-the-art models. This problem becomes even more severe for dense tasks, such as 3D semantic segmentation, where points of non-standard objects can be confidently associated to the wrong class. In this work, we focus on improving the generalization to out-of-domain data. We achieve this by augmenting the training set with adversarial examples. First, we learn a set of vectors that deform the objects in an adversarial fashion. To prevent the adversarial examples from being too far from the existing data distribution, we preserve their plausibility through a series of constraints, ensuring sensor-awareness and shapes smoothness. Then, we perform adversarial augmentation by applying the learned sample-independent vectors to the available objects when training a model. We conduct extensive experiments across a variety of scenarios on data from KITTI, Waymo, and CrashD for 3D object detection, and on data from SemanticKITTI, Waymo, and nuScenes for 3D semantic segmentation. Despite training on a standard single dataset, our approach substantially improves the robustness and generalization of both 3D object detection and 3D semantic segmentation methods to out-of-domain data.
Robust Monocular Depth Estimation under Challenging Conditions
Aug 18, 2023



While state-of-the-art monocular depth estimation approaches achieve impressive results in ideal settings, they are highly unreliable under challenging illumination and weather conditions, such as at nighttime or in the presence of rain. In this paper, we uncover these safety-critical issues and tackle them with md4all: a simple and effective solution that works reliably under both adverse and ideal conditions, as well as for different types of learning supervision. We achieve this by exploiting the efficacy of existing methods under perfect settings. Therefore, we provide valid training signals independently of what is in the input. First, we generate a set of complex samples corresponding to the normal training ones. Then, we train the model by guiding its self- or full-supervision by feeding the generated samples and computing the standard losses on the corresponding original images. Doing so enables a single model to recover information across diverse conditions without modifications at inference time. Extensive experiments on two challenging public datasets, namely nuScenes and Oxford RobotCar, demonstrate the effectiveness of our techniques, outperforming prior works by a large margin in both standard and challenging conditions. Source code and data are available at: https://md4all.github.io.
Holistic Segmentation
Sep 12, 2022
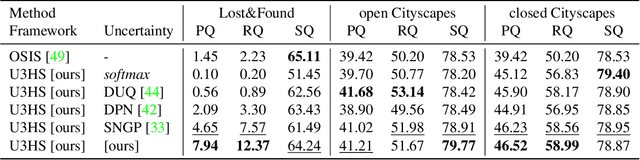
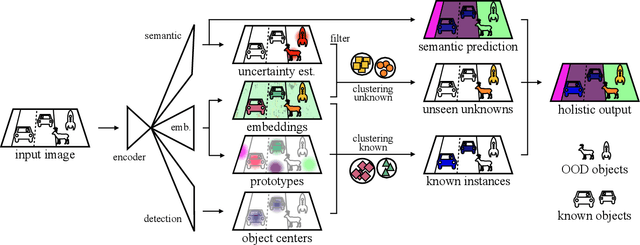

As panoptic segmentation provides a prediction for every pixel in input, non-standard and unseen objects systematically lead to wrong outputs. However, in safety-critical settings, robustness against out-of-distribution samples and corner cases is crucial to avoid dangerous behaviors, such as ignoring an animal or a lost cargo on the road. Since driving datasets cannot contain enough data points to properly sample the long tail of the underlying distribution, a method must deal with unknown and unseen scenarios to be deployed safely. Previous methods targeted part of this issue, by re-identifying already seen unlabeled objects. In this work, we broaden the scope proposing holistic segmentation: a task to identify and separate unseen unknown objects into instances, without learning from unknowns, while performing panoptic segmentation of known classes. We tackle this new problem with U3HS, which first finds unknowns as highly uncertain regions, then clusters the corresponding instance-aware embeddings into individual objects. By doing so, for the first time in panoptic segmentation with unknown objects, our U3HS is not trained with unknown data, thus leaving the settings unconstrained with respect to the type of objects and allowing for a holistic scene understanding. Extensive experiments and comparisons on two public datasets, namely Cityscapes and Lost&Found as a transfer, demonstrate the effectiveness of U3HS in the challenging task of holistic segmentation, with competitive closed-set panoptic segmentation performance.