 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRate Maximization for UAV-assisted ISAC System with Fluid Antennas
Oct 09, 2025This letter investigates the joint sensing problem between unmanned aerial vehicles (UAV) and base stations (BS) in integrated sensing and communication (ISAC) systems with fluid antennas (FA). In this system, the BS enhances its sensing performance through the UAV's perception system. We aim to maximize the communication rate between the BS and UAV while guaranteeing the joint system's sensing capability. By establishing a communication-sensing model with convex optimization properties, we decompose the problem and apply convex optimization to progressively solve key variables. An iterative algorithm employing an alternating optimization approach is subsequently developed to determine the optimal solution, significantly reducing the solution complexity. Simulation results validate the algorithm's effectiveness in balancing system performance.
GALA: Guided Attention with Language Alignment for Open Vocabulary Gaussian Splatting
Aug 21, 2025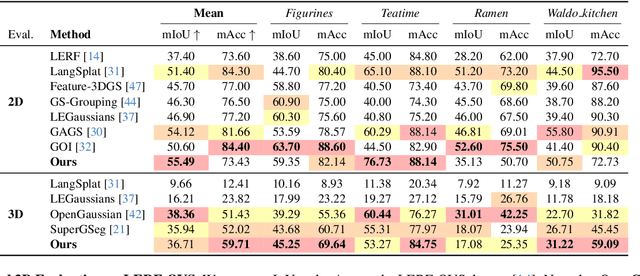
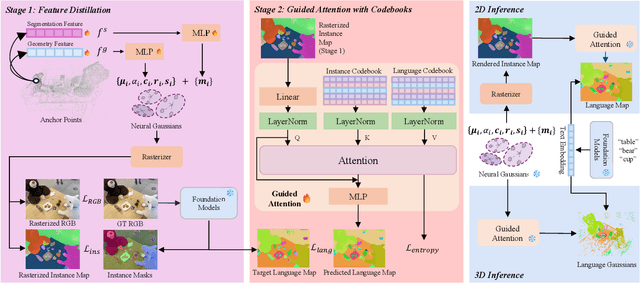
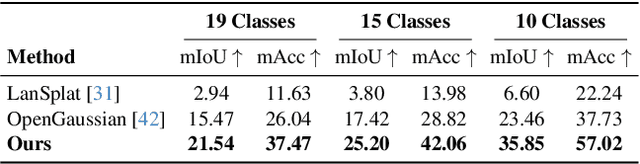

3D scene reconstruction and understanding have gained increasing popularity, yet existing methods still struggle to capture fine-grained, language-aware 3D representations from 2D images. In this paper, we present GALA, a novel framework for open-vocabulary 3D scene understanding with 3D Gaussian Splatting (3DGS). GALA distills a scene-specific 3D instance feature field via self-supervised contrastive learning. To extend to generalized language feature fields, we introduce the core contribution of GALA, a cross-attention module with two learnable codebooks that encode view-independent semantic embeddings. This design not only ensures intra-instance feature similarity but also supports seamless 2D and 3D open-vocabulary queries. It reduces memory consumption by avoiding per-Gaussian high-dimensional feature learning. Extensive experiments on real-world datasets demonstrate GALA's remarkable open-vocabulary performance on both 2D and 3D.
Scene Graph-Aided Probabilistic Semantic Communication for Image Transmission
Jul 16, 2025Semantic communication emphasizes the transmission of meaning rather than raw symbols. It offers a promising solution to alleviate network congestion and improve transmission efficiency. In this paper, we propose a wireless image communication framework that employs probability graphs as shared semantic knowledge base among distributed users. High-level image semantics are represented via scene graphs, and a two-stage compression algorithm is devised to remove predictable components based on learned conditional and co-occurrence probabilities. At the transmitter, the algorithm filters redundant relations and entity pairs, while at the receiver, semantic recovery leverages the same probability graphs to reconstruct omitted information. For further research, we also put forward a multi-round semantic compression algorithm with its theoretical performance analysis. Simulation results demonstrate that our semantic-aware scheme achieves superior transmission throughput and satiable semantic alignment, validating the efficacy of leveraging high-level semantics for image communication.
SuperGSeg: Open-Vocabulary 3D Segmentation with Structured Super-Gaussians
Dec 13, 2024



3D Gaussian Splatting has recently gained traction for its efficient training and real-time rendering. While the vanilla Gaussian Splatting representation is mainly designed for view synthesis, more recent works investigated how to extend it with scene understanding and language features. However, existing methods lack a detailed comprehension of scenes, limiting their ability to segment and interpret complex structures. To this end, We introduce SuperGSeg, a novel approach that fosters cohesive, context-aware scene representation by disentangling segmentation and language field distillation. SuperGSeg first employs neural Gaussians to learn instance and hierarchical segmentation features from multi-view images with the aid of off-the-shelf 2D masks. These features are then leveraged to create a sparse set of what we call Super-Gaussians. Super-Gaussians facilitate the distillation of 2D language features into 3D space. Through Super-Gaussians, our method enables high-dimensional language feature rendering without extreme increases in GPU memory. Extensive experiments demonstrate that SuperGSeg outperforms prior works on both open-vocabulary object localization and semantic segmentation tasks.
Surface Normal Estimation with Transformers
Jan 11, 2024We propose the use of a Transformer to accurately predict normals from point clouds with noise and density variations. Previous learning-based methods utilize PointNet variants to explicitly extract multi-scale features at different input scales, then focus on a surface fitting method by which local point cloud neighborhoods are fitted to a geometric surface approximated by either a polynomial function or a multi-layer perceptron (MLP). However, fitting surfaces to fixed-order polynomial functions can suffer from overfitting or underfitting, and learning MLP-represented hyper-surfaces requires pre-generated per-point weights. To avoid these limitations, we first unify the design choices in previous works and then propose a simplified Transformer-based model to extract richer and more robust geometric features for the surface normal estimation task. Through extensive experiments, we demonstrate that our Transformer-based method achieves state-of-the-art performance on both the synthetic shape dataset PCPNet, and the real-world indoor scene dataset SceneNN, exhibiting more noise-resilient behavior and significantly faster inference. Most importantly, we demonstrate that the sophisticated hand-designed modules in existing works are not necessary to excel at the task of surface normal estimation.