 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeoDiffusion: A Training-Free Framework for Accurate 3D Geometric Conditioning in Image Generation
Oct 25, 2025Precise geometric control in image generation is essential for engineering \& product design and creative industries to control 3D object features accurately in image space. Traditional 3D editing approaches are time-consuming and demand specialized skills, while current image-based generative methods lack accuracy in geometric conditioning. To address these challenges, we propose GeoDiffusion, a training-free framework for accurate and efficient geometric conditioning of 3D features in image generation. GeoDiffusion employs a class-specific 3D object as a geometric prior to define keypoints and parametric correlations in 3D space. We ensure viewpoint consistency through a rendered image of a reference 3D object, followed by style transfer to meet user-defined appearance specifications. At the core of our framework is GeoDrag, improving accuracy and speed of drag-based image editing on geometry guidance tasks and general instructions on DragBench. Our results demonstrate that GeoDiffusion enables precise geometric modifications across various iterative design workflows.
Scalable Object Detection in the Car Interior With Vision Foundation Models
Aug 27, 2025



AI tasks in the car interior like identifying and localizing externally introduced objects is crucial for response quality of personal assistants. However, computational resources of on-board systems remain highly constrained, restricting the deployment of such solutions directly within the vehicle. To address this limitation, we propose the novel Object Detection and Localization (ODAL) framework for interior scene understanding. Our approach leverages vision foundation models through a distributed architecture, splitting computational tasks between on-board and cloud. This design overcomes the resource constraints of running foundation models directly in the car. To benchmark model performance, we introduce ODALbench, a new metric for comprehensive assessment of detection and localization.Our analysis demonstrates the framework's potential to establish new standards in this domain. We compare the state-of-the-art GPT-4o vision foundation model with the lightweight LLaVA 1.5 7B model and explore how fine-tuning enhances the lightweight models performance. Remarkably, our fine-tuned ODAL-LLaVA model achieves an ODAL$_{score}$ of 89%, representing a 71% improvement over its baseline performance and outperforming GPT-4o by nearly 20%. Furthermore, the fine-tuned model maintains high detection accuracy while significantly reducing hallucinations, achieving an ODAL$_{SNR}$ three times higher than GPT-4o.
Effective Data Pruning through Score Extrapolation
Jun 10, 2025Training advanced machine learning models demands massive datasets, resulting in prohibitive computational costs. To address this challenge, data pruning techniques identify and remove redundant training samples while preserving model performance. Yet, existing pruning techniques predominantly require a full initial training pass to identify removable samples, negating any efficiency benefits for single training runs. To overcome this limitation, we introduce a novel importance score extrapolation framework that requires training on only a small subset of data. We present two initial approaches in this framework - k-nearest neighbors and graph neural networks - to accurately predict sample importance for the entire dataset using patterns learned from this minimal subset. We demonstrate the effectiveness of our approach for 2 state-of-the-art pruning methods (Dynamic Uncertainty and TDDS), 4 different datasets (CIFAR-10, CIFAR-100, Places-365, and ImageNet), and 3 training paradigms (supervised, unsupervised, and adversarial). Our results indicate that score extrapolation is a promising direction to scale expensive score calculation methods, such as pruning, data attribution, or other tasks.
Prior2Former -- Evidential Modeling of Mask Transformers for Assumption-Free Open-World Panoptic Segmentation
Apr 07, 2025In panoptic segmentation, individual instances must be separated within semantic classes. As state-of-the-art methods rely on a pre-defined set of classes, they struggle with novel categories and out-of-distribution (OOD) data. This is particularly problematic in safety-critical applications, such as autonomous driving, where reliability in unseen scenarios is essential. We address the gap between outstanding benchmark performance and reliability by proposing Prior2Former (P2F), the first approach for segmentation vision transformers rooted in evidential learning. P2F extends the mask vision transformer architecture by incorporating a Beta prior for computing model uncertainty in pixel-wise binary mask assignments. This design enables high-quality uncertainty estimation that effectively detects novel and OOD objects enabling state-of-the-art anomaly instance segmentation and open-world panoptic segmentation. Unlike most segmentation models addressing unknown classes, P2F operates without access to OOD data samples or contrastive training on void (i.e., unlabeled) classes, making it highly applicable in real-world scenarios where such prior information is unavailable. Additionally, P2F can be flexibly applied to anomaly instance and panoptic segmentation. Through comprehensive experiments on the Cityscapes, COCO, SegmentMeIfYouCan, and OoDIS datasets, we demonstrate the state-of-the-art performance of P2F. It achieves the highest ranking in the OoDIS anomaly instance benchmark among methods not using OOD data in any way.
EmoGRACE: Aspect-based emotion analysis for social media data
Mar 19, 2025While sentiment analysis has advanced from sentence to aspect-level, i.e., the identification of concrete terms related to a sentiment, the equivalent field of Aspect-based Emotion Analysis (ABEA) is faced with dataset bottlenecks and the increased complexity of emotion classes in contrast to binary sentiments. This paper addresses these gaps, by generating a first ABEA training dataset, consisting of 2,621 English Tweets, and fine-tuning a BERT-based model for the ABEA sub-tasks of Aspect Term Extraction (ATE) and Aspect Emotion Classification (AEC). The dataset annotation process was based on the hierarchical emotion theory by Shaver et al. [1] and made use of group annotation and majority voting strategies to facilitate label consistency. The resulting dataset contained aspect-level emotion labels for Anger, Sadness, Happiness, Fear, and a None class. Using the new ABEA training dataset, the state-of-the-art ABSA model GRACE by Luo et al. [2] was fine-tuned for ABEA. The results reflected a performance plateau at an F1-score of 70.1% for ATE and 46.9% for joint ATE and AEC extraction. The limiting factors for model performance were broadly identified as the small training dataset size coupled with the increased task complexity, causing model overfitting and limited abilities to generalize well on new data.
Joint Out-of-Distribution Filtering and Data Discovery Active Learning
Mar 04, 2025As the data demand for deep learning models increases, active learning (AL) becomes essential to strategically select samples for labeling, which maximizes data efficiency and reduces training costs. Real-world scenarios necessitate the consideration of incomplete data knowledge within AL. Prior works address handling out-of-distribution (OOD) data, while another research direction has focused on category discovery. However, a combined analysis of real-world considerations combining AL with out-of-distribution data and category discovery remains unexplored. To address this gap, we propose Joint Out-of-distribution filtering and data Discovery Active learning (Joda) , to uniquely address both challenges simultaneously by filtering out OOD data before selecting candidates for labeling. In contrast to previous methods, we deeply entangle the training procedure with filter and selection to construct a common feature space that aligns known and novel categories while separating OOD samples. Unlike previous works, Joda is highly efficient and completely omits auxiliary models and training access to the unlabeled pool for filtering or selection. In extensive experiments on 18 configurations and 3 metrics, \ours{} consistently achieves the highest accuracy with the best class discovery to OOD filtering balance compared to state-of-the-art competitor approaches.
Active Learning for Identifying Disaster-Related Tweets: A Comparison with Keyword Filtering and Generic Fine-Tuning
Aug 19, 2024Information from social media can provide essential information for emergency response during natural disasters in near real-time. However, it is difficult to identify the disaster-related posts among the large amounts of unstructured data available. Previous methods often use keyword filtering, topic modelling or classification-based techniques to identify such posts. Active Learning (AL) presents a promising sub-field of Machine Learning (ML) that has not been used much in the field of text classification of social media content. This study therefore investigates the potential of AL for identifying disaster-related Tweets. We compare a keyword filtering approach, a RoBERTa model fine-tuned with generic data from CrisisLex, a base RoBERTa model trained with AL and a fine-tuned RoBERTa model trained with AL regarding classification performance. For testing, data from CrisisLex and manually labelled data from the 2021 flood in Germany and the 2023 Chile forest fires were considered. The results show that generic fine-tuning combined with 10 rounds of AL outperformed all other approaches. Consequently, a broadly applicable model for the identification of disaster-related Tweets could be trained with very little labelling effort. The model can be applied to use cases beyond this study and provides a useful tool for further research in social media analysis.
* Submitted for the Intelligent Systems Conference (IntelliSys 2024). The version of record of this contribution is published in the Springer series Lecture Notes in Networks and Systems, and is available online at https://doi.org/10.1007/978-3-031-66428-1_8. This preprint has not undergone peer review or any post-submission improvements or corrections. 13 pages, 2 figures
A Unified Approach Towards Active Learning and Out-of-Distribution Detection
May 18, 2024When applying deep learning models in open-world scenarios, active learning (AL) strategies are crucial for identifying label candidates from a nearly infinite amount of unlabeled data. In this context, robust out-of-distribution (OOD) detection mechanisms are essential for handling data outside the target distribution of the application. However, current works investigate both problems separately. In this work, we introduce SISOM as the first unified solution for both AL and OOD detection. By leveraging feature space distance metrics SISOM combines the strengths of the currently independent tasks to solve both effectively. We conduct extensive experiments showing the problems arising when migrating between both tasks. In these evaluations SISOM underlined its effectiveness by achieving first place in two of the widely used OpenOOD benchmarks and second place in the remaining one. In AL, SISOM outperforms others and delivers top-1 performance in three benchmarks
Developing trustworthy AI applications with foundation models
May 08, 2024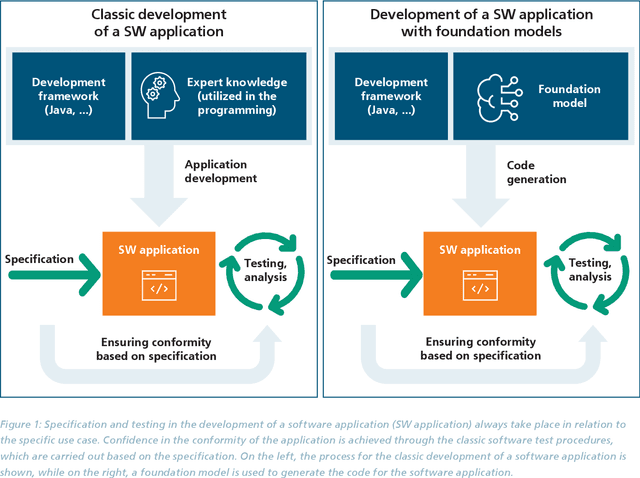
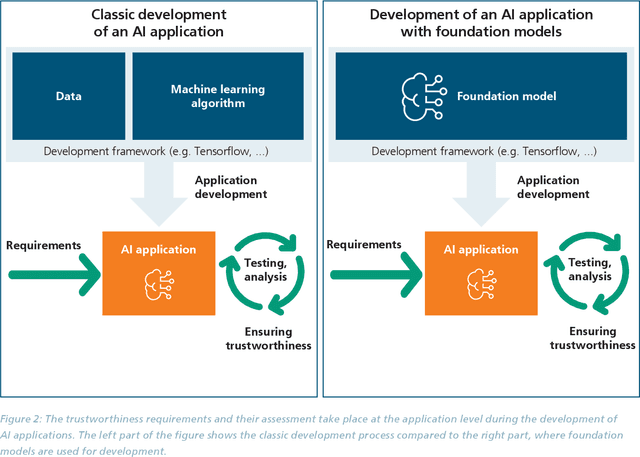

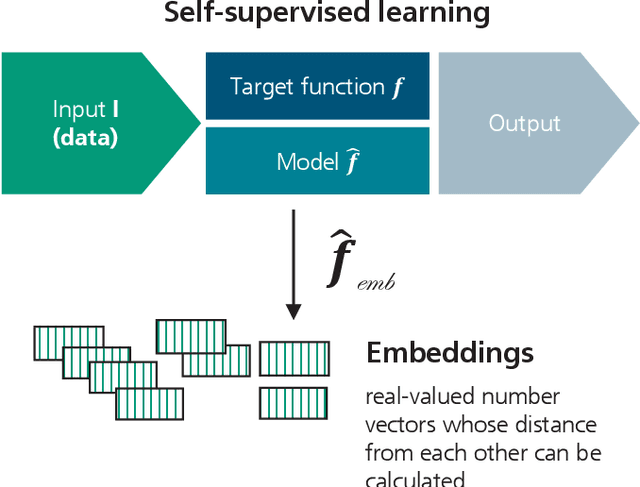
The trustworthiness of AI applications has been the subject of recent research and is also addressed in the EU's recently adopted AI Regulation. The currently emerging foundation models in the field of text, speech and image processing offer completely new possibilities for developing AI applications. This whitepaper shows how the trustworthiness of an AI application developed with foundation models can be evaluated and ensured. For this purpose, the application-specific, risk-based approach for testing and ensuring the trustworthiness of AI applications, as developed in the 'AI Assessment Catalog - Guideline for Trustworthy Artificial Intelligence' by Fraunhofer IAIS, is transferred to the context of foundation models. Special consideration is given to the fact that specific risks of foundation models can have an impact on the AI application and must also be taken into account when checking trustworthiness. Chapter 1 of the white paper explains the fundamental relationship between foundation models and AI applications based on them in terms of trustworthiness. Chapter 2 provides an introduction to the technical construction of foundation models and Chapter 3 shows how AI applications can be developed based on them. Chapter 4 provides an overview of the resulting risks regarding trustworthiness. Chapter 5 shows which requirements for AI applications and foundation models are to be expected according to the draft of the European Union's AI Regulation and Chapter 6 finally shows the system and procedure for meeting trustworthiness requirements.
Detecting Generated Native Ads in Conversational Search
Feb 07, 2024
Conversational search engines such as YouChat and Microsoft Copilot use large language models (LLMs) to generate answers to queries. It is only a small step to also use this technology to generate and integrate advertising within these answers - instead of placing ads separately from the organic search results. This type of advertising is reminiscent of native advertising and product placement, both of which are very effective forms of subtle and manipulative advertising. It is likely that information seekers will be confronted with such use of LLM technology in the near future, especially when considering the high computational costs associated with LLMs, for which providers need to develop sustainable business models. This paper investigates whether LLMs can also be used as a countermeasure against generated native ads, i.e., to block them. For this purpose we compile a large dataset of ad-prone queries and of generated answers with automatically integrated ads to experiment with fine-tuned sentence transformers and state-of-the-art LLMs on the task of recognizing the ads. In our experiments sentence transformers achieve detection precision and recall values above 0.9, while the investigated LLMs struggle with the task.