 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeveloping trustworthy AI applications with foundation models
May 08, 2024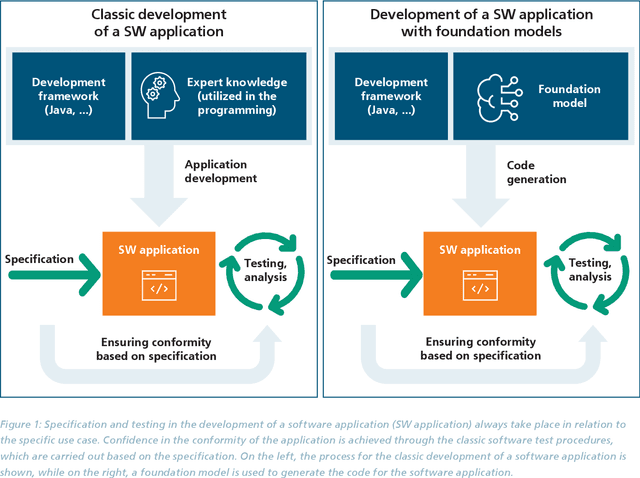
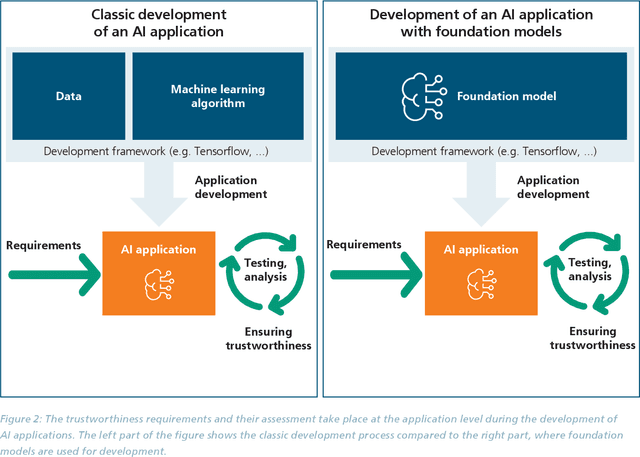

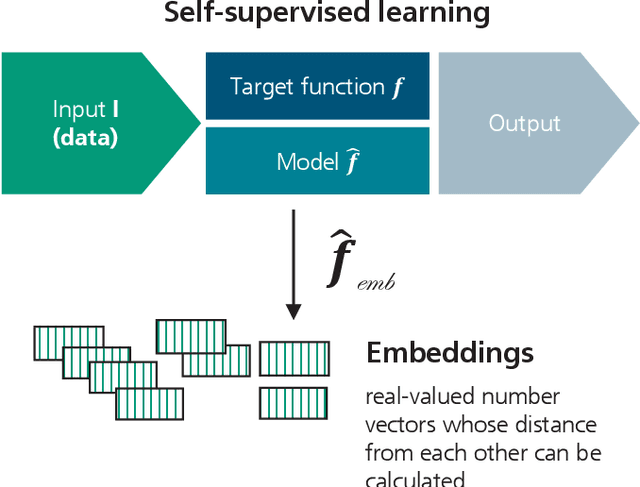
The trustworthiness of AI applications has been the subject of recent research and is also addressed in the EU's recently adopted AI Regulation. The currently emerging foundation models in the field of text, speech and image processing offer completely new possibilities for developing AI applications. This whitepaper shows how the trustworthiness of an AI application developed with foundation models can be evaluated and ensured. For this purpose, the application-specific, risk-based approach for testing and ensuring the trustworthiness of AI applications, as developed in the 'AI Assessment Catalog - Guideline for Trustworthy Artificial Intelligence' by Fraunhofer IAIS, is transferred to the context of foundation models. Special consideration is given to the fact that specific risks of foundation models can have an impact on the AI application and must also be taken into account when checking trustworthiness. Chapter 1 of the white paper explains the fundamental relationship between foundation models and AI applications based on them in terms of trustworthiness. Chapter 2 provides an introduction to the technical construction of foundation models and Chapter 3 shows how AI applications can be developed based on them. Chapter 4 provides an overview of the resulting risks regarding trustworthiness. Chapter 5 shows which requirements for AI applications and foundation models are to be expected according to the draft of the European Union's AI Regulation and Chapter 6 finally shows the system and procedure for meeting trustworthiness requirements.
Using ScrutinAI for Visual Inspection of DNN Performance in a Medical Use Case
Aug 02, 2023Our Visual Analytics (VA) tool ScrutinAI supports human analysts to investigate interactively model performanceand data sets. Model performance depends on labeling quality to a large extent. In particular in medical settings, generation of high quality labels requires in depth expert knowledge and is very costly. Often, data sets are labeled by collecting opinions of groups of experts. We use our VA tool to analyse the influence of label variations between different experts on the model performance. ScrutinAI facilitates to perform a root cause analysis that distinguishes weaknesses of deep neural network (DNN) models caused by varying or missing labeling quality from true weaknesses. We scrutinize the overall detection of intracranial hemorrhages and the more subtle differentiation between subtypes in a publicly available data set.