 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Hierarchical Any-Angle Path Planning on Multi-Resolution 3D Grids
Feb 24, 2026Hierarchical, multi-resolution volumetric mapping approaches are widely used to represent large and complex environments as they can efficiently capture their occupancy and connectivity information. Yet widely used path planning methods such as sampling and trajectory optimization do not exploit this explicit connectivity information, and search-based methods such as A* suffer from scalability issues in large-scale high-resolution maps. In many applications, Euclidean shortest paths form the underpinning of the navigation system. For such applications, any-angle planning methods, which find optimal paths by connecting corners of obstacles with straight-line segments, provide a simple and efficient solution. In this paper, we present a method that has the optimality and completeness properties of any-angle planners while overcoming computational tractability issues common to search-based methods by exploiting multi-resolution representations. Extensive experiments on real and synthetic environments demonstrate the proposed approach's solution quality and speed, outperforming even sampling-based methods. The framework is open-sourced to allow the robotics and planning community to build on our research.
* 12 pages, 9 figures, 4 tables, accepted to RSS 2025, code is open-source: https://github.com/ethz-asl/wavestar
Learning Affordances from Interactive Exploration using an Object-level Map
Jan 10, 2025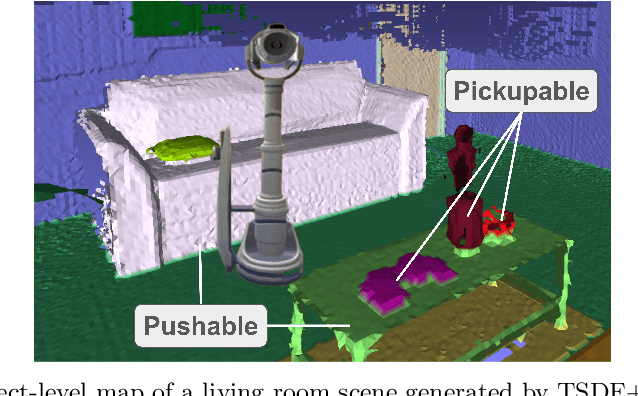
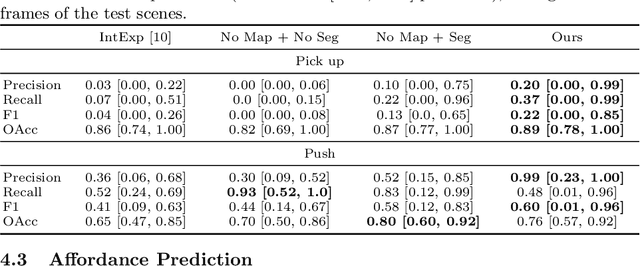
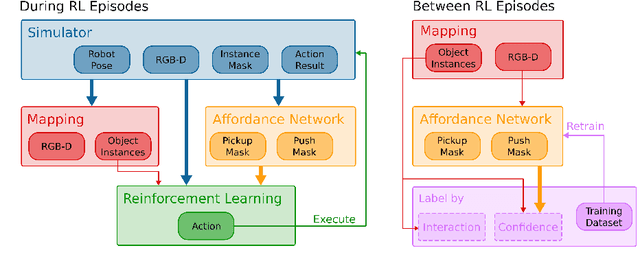
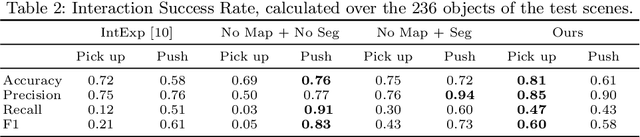
Many robotic tasks in real-world environments require physical interactions with an object such as pick up or push. For successful interactions, the robot needs to know the object's affordances, which are defined as the potential actions the robot can perform with the object. In order to learn a robot-specific affordance predictor, we propose an interactive exploration pipeline which allows the robot to collect interaction experiences while exploring an unknown environment. We integrate an object-level map in the exploration pipeline such that the robot can identify different object instances and track objects across diverse viewpoints. This results in denser and more accurate affordance annotations compared to state-of-the-art methods, which do not incorporate a map. We show that our affordance exploration approach makes exploration more efficient and results in more accurate affordance prediction models compared to baseline methods.
NeuSurfEmb: A Complete Pipeline for Dense Correspondence-based 6D Object Pose Estimation without CAD Models
Jul 16, 2024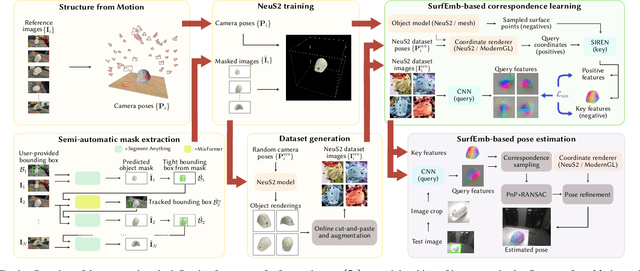



State-of-the-art approaches for 6D object pose estimation assume the availability of CAD models and require the user to manually set up physically-based rendering (PBR) pipelines for synthetic training data generation. Both factors limit the application of these methods in real-world scenarios. In this work, we present a pipeline that does not require CAD models and allows training a state-of-the-art pose estimator requiring only a small set of real images as input. Our method is based on a NeuS2 object representation, that we learn through a semi-automated procedure based on Structure-from-Motion (SfM) and object-agnostic segmentation. We exploit the novel-view synthesis ability of NeuS2 and simple cut-and-paste augmentation to automatically generate photorealistic object renderings, which we use to train the correspondence-based SurfEmb pose estimator. We evaluate our method on the LINEMOD-Occlusion dataset, extensively studying the impact of its individual components and showing competitive performance with respect to approaches based on CAD models and PBR data. We additionally demonstrate the ease of use and effectiveness of our pipeline on self-collected real-world objects, showing that our method outperforms state-of-the-art CAD-model-free approaches, with better accuracy and robustness to mild occlusions. To allow the robotics community to benefit from this system, we will publicly release it at https://www.github.com/ethz-asl/neusurfemb.
Task Adaptation in Industrial Human-Robot Interaction: Leveraging Riemannian Motion Policies
Jun 25, 2024
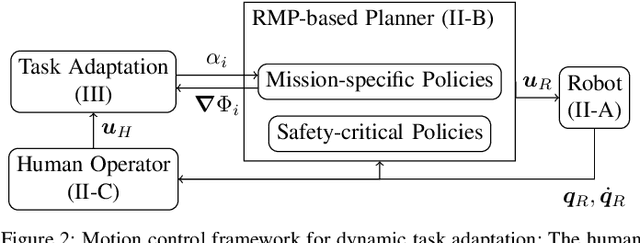
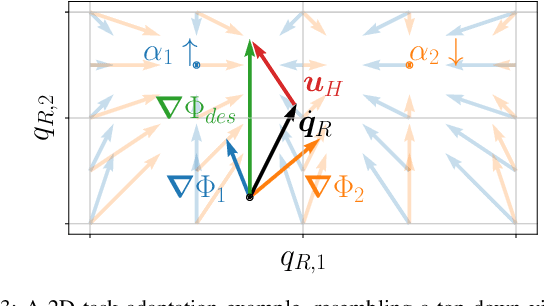

In real-world industrial environments, modern robots often rely on human operators for crucial decision-making and mission synthesis from individual tasks. Effective and safe collaboration between humans and robots requires systems that can adjust their motion based on human intentions, enabling dynamic task planning and adaptation. Addressing the needs of industrial applications, we propose a motion control framework that (i) removes the need for manual control of the robot's movement; (ii) facilitates the formulation and combination of complex tasks; and (iii) allows the seamless integration of human intent recognition and robot motion planning. For this purpose, we leverage a modular and purely reactive approach for task parametrization and motion generation, embodied by Riemannian Motion Policies. The effectiveness of our method is demonstrated, evaluated, and compared to \remove{state-of-the-art approaches}\add{a representative state-of-the-art approach} in experimental scenarios inspired by realistic industrial Human-Robot Interaction settings.
* 9 pages; Robotics, Science and Systems (RSS) 2024
Waverider: Leveraging Hierarchical, Multi-Resolution Maps for Efficient and Reactive Obstacle Avoidance
May 22, 2024



Fast and reliable obstacle avoidance is an important task for mobile robots. In this work, we propose an efficient reactive system that provides high-quality obstacle avoidance while running at hundreds of hertz with minimal resource usage. Our approach combines wavemap, a hierarchical volumetric map representation, with a novel hierarchical and parallelizable obstacle avoidance algorithm formulated through Riemannian Motion Policies (RMP). Leveraging multi-resolution obstacle avoidance policies, the proposed navigation system facilitates precise, low-latency (36ms), and extremely efficient obstacle avoidance with a very large perceptive radius (30m). We perform extensive statistical evaluations on indoor and outdoor maps, verifying that the proposed system compares favorably to fixed-resolution RMP variants and CHOMP. Finally, the RMP formulation allows the seamless fusion of obstacle avoidance with additional objectives, such as goal-seeking, to obtain a fully-fledged navigation system that is versatile and robust. We deploy the system on a Micro Aerial Vehicle and show how it navigates through an indoor obstacle course. Our complete implementation, called waverider, is made available as open source.
Zero123-6D: Zero-shot Novel View Synthesis for RGB Category-level 6D Pose Estimation
Mar 21, 2024



Estimating the pose of objects through vision is essential to make robotic platforms interact with the environment. Yet, it presents many challenges, often related to the lack of flexibility and generalizability of state-of-the-art solutions. Diffusion models are a cutting-edge neural architecture transforming 2D and 3D computer vision, outlining remarkable performances in zero-shot novel-view synthesis. Such a use case is particularly intriguing for reconstructing 3D objects. However, localizing objects in unstructured environments is rather unexplored. To this end, this work presents Zero123-6D to demonstrate the utility of Diffusion Model-based novel-view-synthesizers in enhancing RGB 6D pose estimation at category-level by integrating them with feature extraction techniques. The outlined method exploits such a novel view synthesizer to expand a sparse set of RGB-only reference views for the zero-shot 6D pose estimation task. Experiments are quantitatively analyzed on the CO3D dataset, showcasing increased performance over baselines, a substantial reduction in data requirements, and the removal of the necessity of depth information.
To Fuse or Not to Fuse: Measuring Consistency in Multi-Sensor Fusion for Aerial Robots
Dec 22, 2023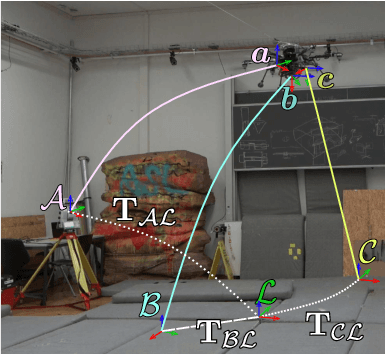
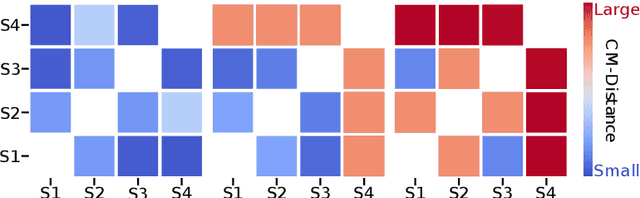
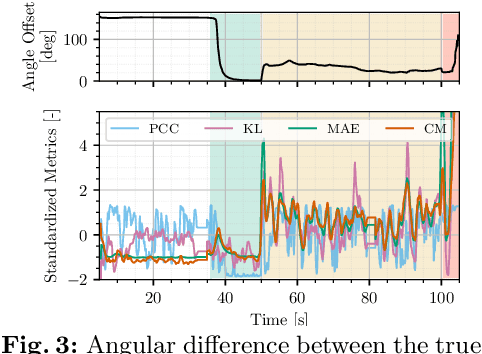
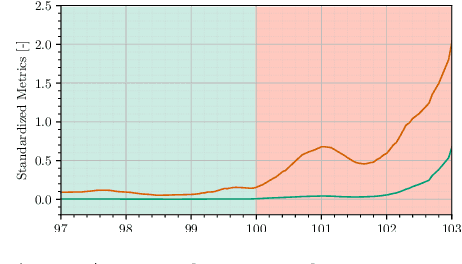
Aerial vehicles are no longer limited to flying in open space: recent work has focused on aerial manipulation and up-close inspection. Such applications place stringent requirements on state estimation: the robot must combine state information from many sources, including onboard odometry and global positioning sensors. However, flying close to or in contact with structures is a degenerate case for many sensing modalities, and the robot's state estimation framework must intelligently choose which sensors are currently trustworthy. We evaluate a number of metrics to judge the reliability of sensing modalities in a multi-sensor fusion framework, then introduce a consensus-finding scheme that uses this metric to choose which sensors to fuse or not to fuse. Finally, we show that such a fusion framework is more robust and accurate than fusing all sensors all the time and demonstrate how such metrics can be informative in real-world experiments in indoor-outdoor flight and bridge inspection.
Soliro -- a hybrid dynamic tilt-wing aerial manipulator with minimal actuators
Dec 08, 2023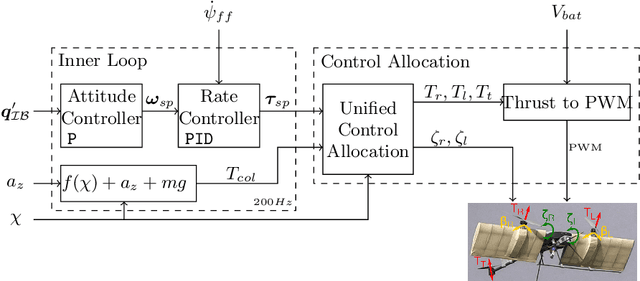
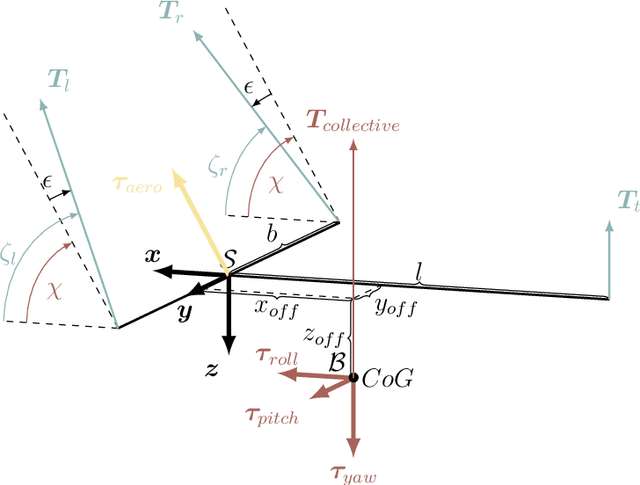

The ability to enter in contact with and manipulate physical objects with a flying robot enables many novel applications, such as contact inspection, painting, drilling, and sample collection. Generally, these aerial robots need more degrees of freedom than a standard quadrotor. While there is active research of over-actuated, omnidirectional MAVs and aerial manipulators as well as VTOL and hybrid platforms, the two concepts have not been combined. We address the problem of conceptualization, characterization, control, and testing of a 5DOF rotary-/fixed-wing hybrid, tilt-rotor, split tilt-wing, nearly omnidirectional aerial robot. We present an elegant solution with a minimal set of actuators and that does not need any classical control surfaces or flaps. The concept is validated in a wind tunnel study and in multiple flights with forward and backward transitions. Fixed-wing flight speeds up to 10 m/s were reached, with a power reduction of 30% as compared to rotary wing flight.
Open X-Embodiment: Robotic Learning Datasets and RT-X Models
Oct 17, 2023



Large, high-capacity models trained on diverse datasets have shown remarkable successes on efficiently tackling downstream applications. In domains from NLP to Computer Vision, this has led to a consolidation of pretrained models, with general pretrained backbones serving as a starting point for many applications. Can such a consolidation happen in robotics? Conventionally, robotic learning methods train a separate model for every application, every robot, and even every environment. Can we instead train generalist X-robot policy that can be adapted efficiently to new robots, tasks, and environments? In this paper, we provide datasets in standardized data formats and models to make it possible to explore this possibility in the context of robotic manipulation, alongside experimental results that provide an example of effective X-robot policies. We assemble a dataset from 22 different robots collected through a collaboration between 21 institutions, demonstrating 527 skills (160266 tasks). We show that a high-capacity model trained on this data, which we call RT-X, exhibits positive transfer and improves the capabilities of multiple robots by leveraging experience from other platforms. More details can be found on the project website $\href{https://robotics-transformer-x.github.io}{\text{robotics-transformer-x.github.io}}$.
Self-Supervised Learning for Interactive Perception of Surgical Thread for Autonomous Suture Tail-Shortening
Jul 13, 2023



Accurate 3D sensing of suturing thread is a challenging problem in automated surgical suturing because of the high state-space complexity, thinness and deformability of the thread, and possibility of occlusion by the grippers and tissue. In this work we present a method for tracking surgical thread in 3D which is robust to occlusions and complex thread configurations, and apply it to autonomously perform the surgical suture "tail-shortening" task: pulling thread through tissue until a desired "tail" length remains exposed. The method utilizes a learned 2D surgical thread detection network to segment suturing thread in RGB images. It then identifies the thread path in 2D and reconstructs the thread in 3D as a NURBS spline by triangulating the detections from two stereo cameras. Once a 3D thread model is initialized, the method tracks the thread across subsequent frames. Experiments suggest the method achieves a 1.33 pixel average reprojection error on challenging single-frame 3D thread reconstructions, and an 0.84 pixel average reprojection error on two tracking sequences. On the tail-shortening task, it accomplishes a 90% success rate across 20 trials. Supplemental materials are available at https://sites.google.com/berkeley.edu/autolab-surgical-thread/ .