 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGrasp Synthesis Matching From Rigid To Soft Robot Grippers Using Conditional Flow Matching
Feb 19, 2026A representation gap exists between grasp synthesis for rigid and soft grippers. Anygrasp [1] and many other grasp synthesis methods are designed for rigid parallel grippers, and adapting them to soft grippers often fails to capture their unique compliant behaviors, resulting in data-intensive and inaccurate models. To bridge this gap, this paper proposes a novel framework to map grasp poses from a rigid gripper model to a soft Fin-ray gripper. We utilize Conditional Flow Matching (CFM), a generative model, to learn this complex transformation. Our methodology includes a data collection pipeline to generate paired rigid-soft grasp poses. A U-Net autoencoder conditions the CFM model on the object's geometry from a depth image, allowing it to learn a continuous mapping from an initial Anygrasp pose to a stable Fin-ray gripper pose. We validate our approach on a 7-DOF robot, demonstrating that our CFM-generated poses achieve a higher overall success rate for seen and unseen objects (34% and 46% respectively) compared to the baseline rigid poses (6% and 25% respectively) when executed by the soft gripper. The model shows significant improvements, particularly for cylindrical (50% and 100% success for seen and unseen objects) and spherical objects (25% and 31% success for seen and unseen objects), and successfully generalizes to unseen objects. This work presents CFM as a data-efficient and effective method for transferring grasp strategies, offering a scalable methodology for other soft robotic systems.
Adaptive Reinforcement and Model Predictive Control Switching for Safe Human-Robot Cooperative Navigation
Jan 23, 2026This paper addresses the challenge of human-guided navigation for mobile collaborative robots under simultaneous proximity regulation and safety constraints. We introduce Adaptive Reinforcement and Model Predictive Control Switching (ARMS), a hybrid learning-control framework that integrates a reinforcement learning follower trained with Proximal Policy Optimization (PPO) and an analytical one-step Model Predictive Control (MPC) formulated as a quadratic program safety filter. To enable robust perception under partial observability and non-stationary human motion, ARMS employs a decoupled sensing architecture with a Long Short-Term Memory (LSTM) temporal encoder for the human-robot relative state and a spatial encoder for 360-degree LiDAR scans. The core contribution is a learned adaptive neural switcher that performs context-aware soft action fusion between the two controllers, favoring conservative, constraint-aware QP-based control in low-risk regions while progressively shifting control authority to the learned follower in highly cluttered or constrained scenarios where maneuverability is critical, and reverting to the follower action when the QP becomes infeasible. Extensive evaluations against Pure Pursuit, Dynamic Window Approach (DWA), and an RL-only baseline demonstrate that ARMS achieves an 82.5 percent success rate in highly cluttered environments, outperforming DWA and RL-only approaches by 7.1 percent and 3.1 percent, respectively, while reducing average computational latency by 33 percent to 5.2 milliseconds compared to a multi-step MPC baseline. Additional simulation transfer in Gazebo and initial real-world deployment results further indicate the practicality and robustness of ARMS for safe and efficient human-robot collaboration. Source code and a demonstration video are available at https://github.com/21ning/ARMS.git.
Learning Affordances from Interactive Exploration using an Object-level Map
Jan 10, 2025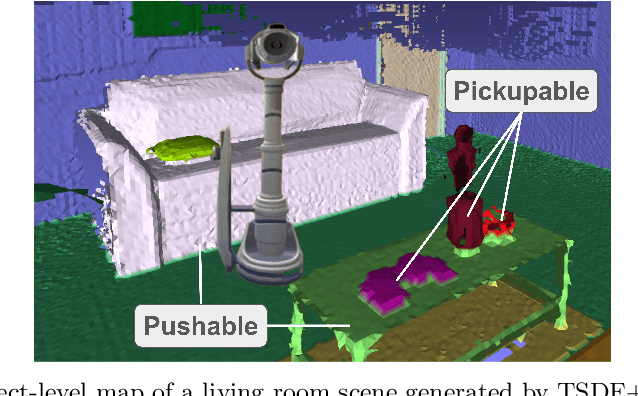
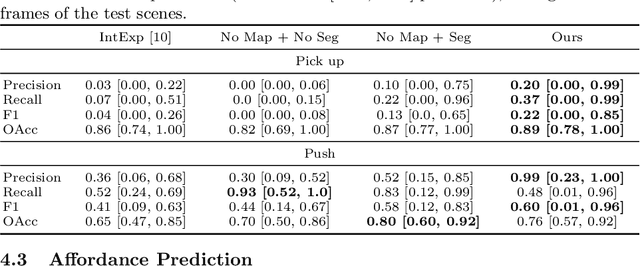
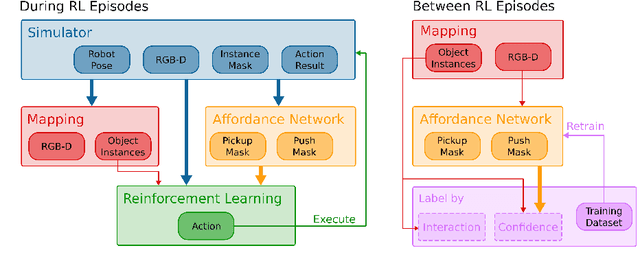
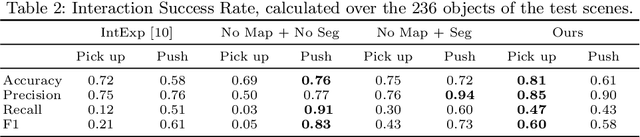
Many robotic tasks in real-world environments require physical interactions with an object such as pick up or push. For successful interactions, the robot needs to know the object's affordances, which are defined as the potential actions the robot can perform with the object. In order to learn a robot-specific affordance predictor, we propose an interactive exploration pipeline which allows the robot to collect interaction experiences while exploring an unknown environment. We integrate an object-level map in the exploration pipeline such that the robot can identify different object instances and track objects across diverse viewpoints. This results in denser and more accurate affordance annotations compared to state-of-the-art methods, which do not incorporate a map. We show that our affordance exploration approach makes exploration more efficient and results in more accurate affordance prediction models compared to baseline methods.
SoGraB: A Visual Method for Soft Grasping Benchmarking and Evaluation
Nov 28, 2024Recent years have seen soft robotic grippers gain increasing attention due to their ability to robustly grasp soft and fragile objects. However, a commonly available standardised evaluation protocol has not yet been developed to assess the performance of varying soft robotic gripper designs. This work introduces a novel protocol, the Soft Grasping Benchmarking and Evaluation (SoGraB) method, to evaluate grasping quality, which quantifies object deformation by using the Density-Aware Chamfer Distance (DCD) between point clouds of soft objects before and after grasping. We validated our protocol in extensive experiments, which involved ranking three Fin-Ray gripper designs with a subset of the EGAD object dataset. The protocol appropriately ranked grippers based on object deformation information, validating the method's ability to select soft grippers for complex grasping tasks and benchmark them for comparison against future designs.
DexGrip: Multi-modal Soft Gripper with Dexterous Grasping and In-hand Manipulation Capacity
Nov 26, 2024



The ability of robotic grippers to not only grasp but also re-position and re-orient objects in-hand is crucial for achieving versatile, general-purpose manipulation. While recent advances in soft robotic grasping has greatly improved grasp quality and stability, their manipulation capabilities remain under-explored. This paper presents the DexGrip, a multi-modal soft robotic gripper for in-hand grasping, re-orientation and manipulation. DexGrip features a 3 Degrees of Freedom (DoFs) active suction palm and 3 active (rotating) grasping surfaces, enabling soft, stable, and dexterous grasping and manipulation without ever needing to re-grasp an object. Uniquely, these features enable complete 360 degree rotation in all three principal axes. We experimentally demonstrate these capabilities across a diverse set of objects and tasks. DexGrip successfully grasped, re-positioned, and re-oriented objects with widely varying stiffnesses, sizes, weights, and surface textures; and effectively manipulated objects that presented significant challenges for existing robotic grippers.
NeuSurfEmb: A Complete Pipeline for Dense Correspondence-based 6D Object Pose Estimation without CAD Models
Jul 16, 2024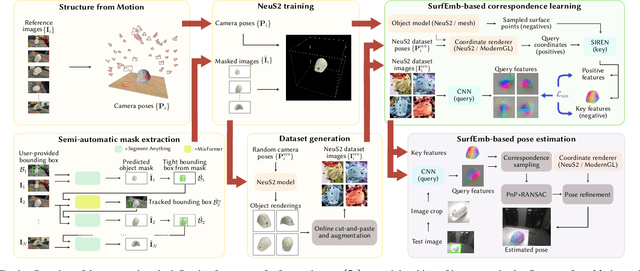



State-of-the-art approaches for 6D object pose estimation assume the availability of CAD models and require the user to manually set up physically-based rendering (PBR) pipelines for synthetic training data generation. Both factors limit the application of these methods in real-world scenarios. In this work, we present a pipeline that does not require CAD models and allows training a state-of-the-art pose estimator requiring only a small set of real images as input. Our method is based on a NeuS2 object representation, that we learn through a semi-automated procedure based on Structure-from-Motion (SfM) and object-agnostic segmentation. We exploit the novel-view synthesis ability of NeuS2 and simple cut-and-paste augmentation to automatically generate photorealistic object renderings, which we use to train the correspondence-based SurfEmb pose estimator. We evaluate our method on the LINEMOD-Occlusion dataset, extensively studying the impact of its individual components and showing competitive performance with respect to approaches based on CAD models and PBR data. We additionally demonstrate the ease of use and effectiveness of our pipeline on self-collected real-world objects, showing that our method outperforms state-of-the-art CAD-model-free approaches, with better accuracy and robustness to mild occlusions. To allow the robotics community to benefit from this system, we will publicly release it at https://www.github.com/ethz-asl/neusurfemb.
Comparison between Behavior Trees and Finite State Machines
May 25, 2024



Behavior Trees (BTs) were first conceived in the computer games industry as a tool to model agent behavior, but they received interest also in the robotics community as an alternative policy design to Finite State Machines (FSMs). The advantages of BTs over FSMs had been highlighted in many works, but there is no thorough practical comparison of the two designs. Such a comparison is particularly relevant in the robotic industry, where FSMs have been the state-of-the-art policy representation for robot control for many years. In this work we shed light on this matter by comparing how BTs and FSMs behave when controlling a robot in a mobile manipulation task. The comparison is made in terms of reactivity, modularity, readability, and design. We propose metrics for each of these properties, being aware that while some are tangible and objective, others are more subjective and implementation dependent. The practical comparison is performed in a simulation environment with validation on a real robot. We find that although the robot's behavior during task solving is independent on the policy representation, maintaining a BT rather than an FSM becomes easier as the task increases in complexity.
WindSeer: Real-time volumetric wind prediction over complex terrain aboard a small UAV
Jan 18, 2024


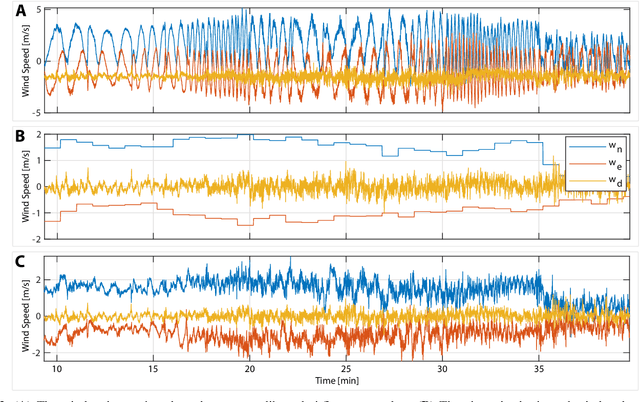
Real-time high-resolution wind predictions are beneficial for various applications including safe manned and unmanned aviation. Current weather models require too much compute and lack the necessary predictive capabilities as they are valid only at the scale of multiple kilometers and hours - much lower spatial and temporal resolutions than these applications require. Our work, for the first time, demonstrates the ability to predict low-altitude wind in real-time on limited-compute devices, from only sparse measurement data. We train a neural network, WindSeer, using only synthetic data from computational fluid dynamics simulations and show that it can successfully predict real wind fields over terrain with known topography from just a few noisy and spatially clustered wind measurements. WindSeer can generate accurate predictions at different resolutions and domain sizes on previously unseen topography without retraining. We demonstrate that the model successfully predicts historical wind data collected by weather stations and wind measured onboard drones.
Neural Implicit Vision-Language Feature Fields
Mar 20, 2023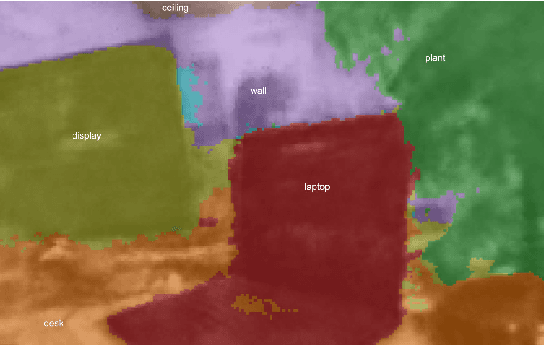
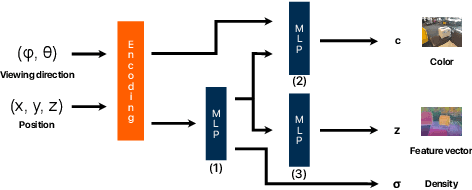


Recently, groundbreaking results have been presented on open-vocabulary semantic image segmentation. Such methods segment each pixel in an image into arbitrary categories provided at run-time in the form of text prompts, as opposed to a fixed set of classes defined at training time. In this work, we present a zero-shot volumetric open-vocabulary semantic scene segmentation method. Our method builds on the insight that we can fuse image features from a vision-language model into a neural implicit representation. We show that the resulting feature field can be segmented into different classes by assigning points to natural language text prompts. The implicit volumetric representation enables us to segment the scene both in 3D and 2D by rendering feature maps from any given viewpoint of the scene. We show that our method works on noisy real-world data and can run in real-time on live sensor data dynamically adjusting to text prompts. We also present quantitative comparisons on the ScanNet dataset.
Multi-Agent Path Integral Control for Interaction-Aware Motion Planning in Urban Canals
Feb 13, 2023



Autonomous vehicles that operate in urban environments shall comply with existing rules and reason about the interactions with other decision-making agents. In this paper, we introduce a decentralized and communication-free interaction-aware motion planner and apply it to Autonomous Surface Vessels (ASVs) in urban canals. We build upon a sampling-based method, namely Model Predictive Path Integral control (MPPI), and employ it to, in each time instance, compute both a collision-free trajectory for the vehicle and a prediction of other agents' trajectories, thus modeling interactions. To improve the method's efficiency in multi-agent scenarios, we introduce a two-stage sample evaluation strategy and define an appropriate cost function to achieve rule compliance. We evaluate this decentralized approach in simulations with multiple vessels in real scenarios extracted from Amsterdam's canals, showing superior performance than a state-of-the-art trajectory optimization framework and robustness when encountering different types of agents.