 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnder pressure: learning-based analog gauge reading in the wild
Apr 12, 2024We propose an interpretable framework for reading analog gauges that is deployable on real world robotic systems. Our framework splits the reading task into distinct steps, such that we can detect potential failures at each step. Our system needs no prior knowledge of the type of gauge or the range of the scale and is able to extract the units used. We show that our gauge reading algorithm is able to extract readings with a relative reading error of less than 2%.
ISAR: A Benchmark for Single- and Few-Shot Object Instance Segmentation and Re-Identification
Nov 05, 2023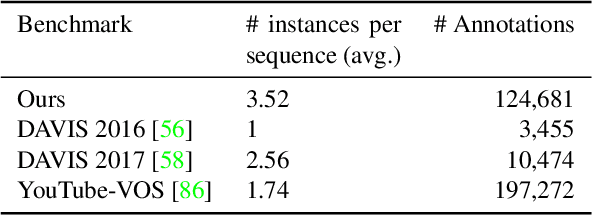

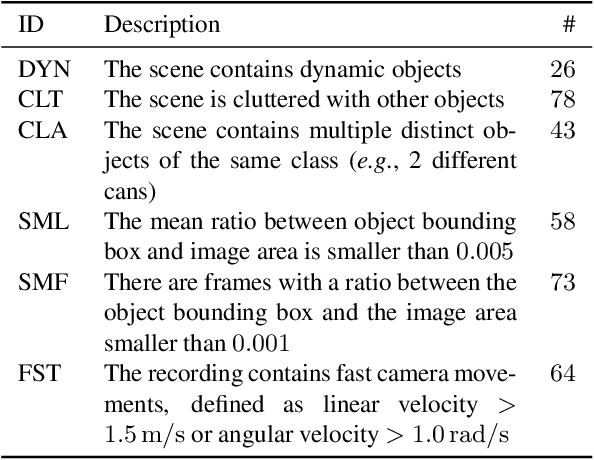
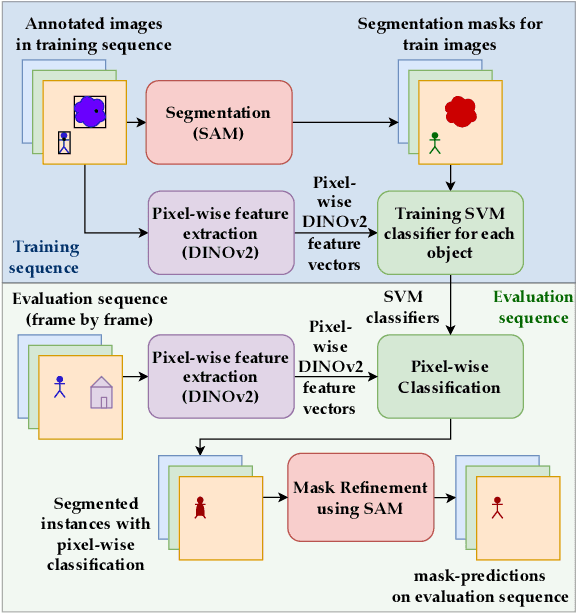
Most object-level mapping systems in use today make use of an upstream learned object instance segmentation model. If we want to teach them about a new object or segmentation class, we need to build a large dataset and retrain the system. To build spatial AI systems that can quickly be taught about new objects, we need to effectively solve the problem of single-shot object detection, instance segmentation and re-identification. So far there is neither a method fulfilling all of these requirements in unison nor a benchmark that could be used to test such a method. Addressing this, we propose ISAR, a benchmark and baseline method for single- and few-shot object Instance Segmentation And Re-identification, in an effort to accelerate the development of algorithms that can robustly detect, segment, and re-identify objects from a single or a few sparse training examples. We provide a semi-synthetic dataset of video sequences with ground-truth semantic annotations, a standardized evaluation pipeline, and a baseline method. Our benchmark aligns with the emerging research trend of unifying Multi-Object Tracking, Video Object Segmentation, and Re-identification.
Panoptic Vision-Language Feature Fields
Sep 11, 2023Recently, methods have been proposed for 3D open-vocabulary semantic segmentation. Such methods are able to segment scenes into arbitrary classes given at run-time using their text description. In this paper, we propose to our knowledge the first algorithm for open-vocabulary panoptic segmentation, simultaneously performing both semantic and instance segmentation. Our algorithm, Panoptic Vision-Language Feature Fields (PVLFF) learns a feature field of the scene, jointly learning vision-language features and hierarchical instance features through a contrastive loss function from 2D instance segment proposals on input frames. Our method achieves comparable performance against the state-of-the-art close-set 3D panoptic systems on the HyperSim, ScanNet and Replica dataset and outperforms current 3D open-vocabulary systems in terms of semantic segmentation. We additionally ablate our method to demonstrate the effectiveness of our model architecture. Our code will be available at https://github.com/ethz-asl/autolabel.
Neural Implicit Vision-Language Feature Fields
Mar 20, 2023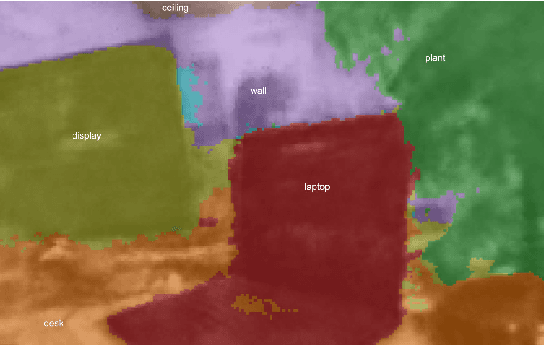
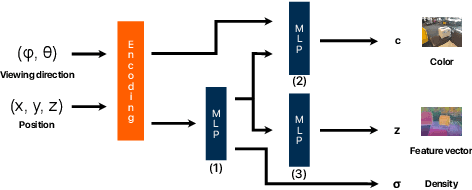


Recently, groundbreaking results have been presented on open-vocabulary semantic image segmentation. Such methods segment each pixel in an image into arbitrary categories provided at run-time in the form of text prompts, as opposed to a fixed set of classes defined at training time. In this work, we present a zero-shot volumetric open-vocabulary semantic scene segmentation method. Our method builds on the insight that we can fuse image features from a vision-language model into a neural implicit representation. We show that the resulting feature field can be segmented into different classes by assigning points to natural language text prompts. The implicit volumetric representation enables us to segment the scene both in 3D and 2D by rendering feature maps from any given viewpoint of the scene. We show that our method works on noisy real-world data and can run in real-time on live sensor data dynamically adjusting to text prompts. We also present quantitative comparisons on the ScanNet dataset.
Baking in the Feature: Accelerating Volumetric Segmentation by Rendering Feature Maps
Sep 26, 2022
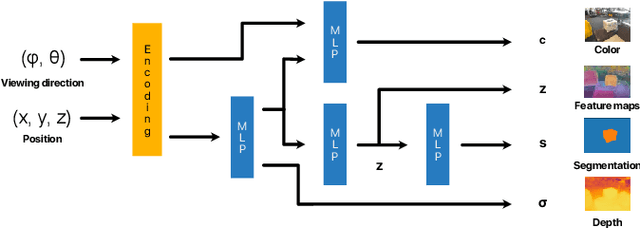


Methods have recently been proposed that densely segment 3D volumes into classes using only color images and expert supervision in the form of sparse semantically annotated pixels. While impressive, these methods still require a relatively large amount of supervision and segmenting an object can take several minutes in practice. Such systems typically only optimize their representation on the particular scene they are fitting, without leveraging any prior information from previously seen images. In this paper, we propose to use features extracted with models trained on large existing datasets to improve segmentation performance. We bake this feature representation into a Neural Radiance Field (NeRF) by volumetrically rendering feature maps and supervising on features extracted from each input image. We show that by baking this representation into the NeRF, we make the subsequent classification task much easier. Our experiments show that our method achieves higher segmentation accuracy with fewer semantic annotations than existing methods over a wide range of scenes.
Semi-automatic 3D Object Keypoint Annotation and Detection for the Masses
Jan 19, 2022
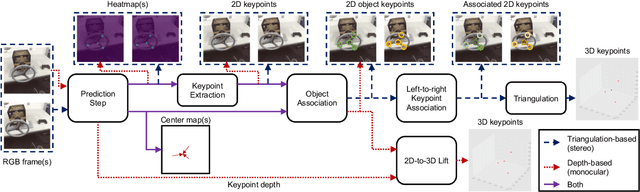


Creating computer vision datasets requires careful planning and lots of time and effort. In robotics research, we often have to use standardized objects, such as the YCB object set, for tasks such as object tracking, pose estimation, grasping and manipulation, as there are datasets and pre-learned methods available for these objects. This limits the impact of our research since learning-based computer vision methods can only be used in scenarios that are supported by existing datasets. In this work, we present a full object keypoint tracking toolkit, encompassing the entire process from data collection, labeling, model learning and evaluation. We present a semi-automatic way of collecting and labeling datasets using a wrist mounted camera on a standard robotic arm. Using our toolkit and method, we are able to obtain a working 3D object keypoint detector and go through the whole process of data collection, annotation and learning in just a couple hours of active time.
3D Annotation Of Arbitrary Objects In The Wild
Sep 15, 2021



Recent years have produced a variety of learning based methods in the context of computer vision and robotics. Most of the recently proposed methods are based on deep learning, which require very large amounts of data compared to traditional methods. The performance of the deep learning methods are largely dependent on the data distribution they were trained on, and it is important to use data from the robot's actual operating domain during training. Therefore, it is not possible to rely on pre-built, generic datasets when deploying robots in real environments, creating a need for efficient data collection and annotation in the specific operating conditions the robots will operate in. The challenge is then: how do we reduce the cost of obtaining such datasets to a point where we can easily deploy our robots in new conditions, environments and to support new sensors? As an answer to this question, we propose a data annotation pipeline based on SLAM, 3D reconstruction, and 3D-to-2D geometry. The pipeline allows creating 3D and 2D bounding boxes, along with per-pixel annotations of arbitrary objects without needing accurate 3D models of the objects prior to data collection and annotation. Our results showcase almost 90% Intersection-over-Union (IoU) agreement on both semantic segmentation and 2D bounding box detection across a variety of objects and scenes, while speeding up the annotation process by several orders of magnitude compared to traditional manual annotation.
Points2Vec: Unsupervised Object-level Feature Learning from Point Clouds
Feb 08, 2021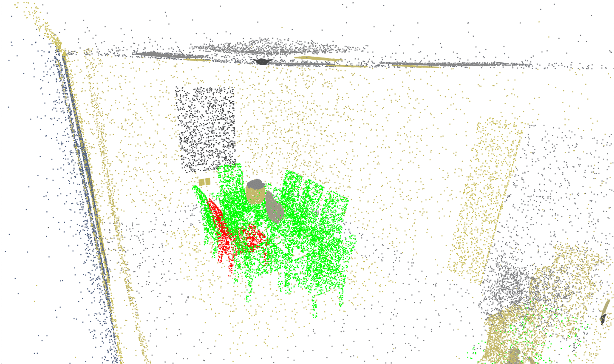
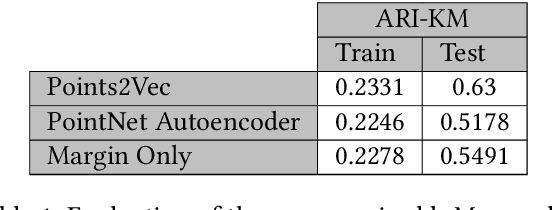
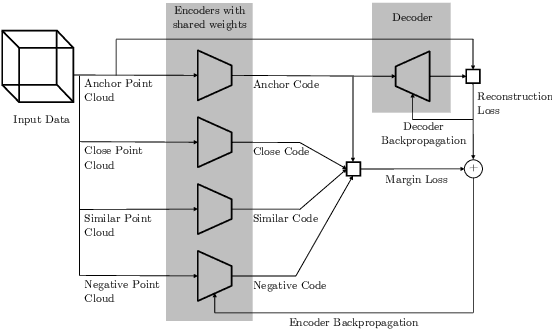
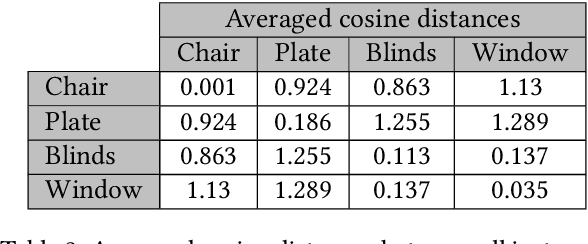
Unsupervised representation learning techniques, such as learning word embeddings, have had a significant impact on the field of natural language processing. Similar representation learning techniques have not yet become commonplace in the context of 3D vision. This, despite the fact that the physical 3D spaces have a similar semantic structure to bodies of text: words are surrounded by words that are semantically related, just like objects are surrounded by other objects that are similar in concept and usage. In this work, we exploit this structure in learning semantically meaningful low dimensional vector representations of objects. We learn these vector representations by mining a dataset of scanned 3D spaces using an unsupervised algorithm. We represent objects as point clouds, a flexible and general representation for 3D data, which we encode into a vector representation. We show that using our method to include context increases the ability of a clustering algorithm to distinguish different semantic classes from each other. Furthermore, we show that our algorithm produces continuous and meaningful object embeddings through interpolation experiments.
Go Fetch: Mobile Manipulation in Unstructured Environments
Apr 02, 2020
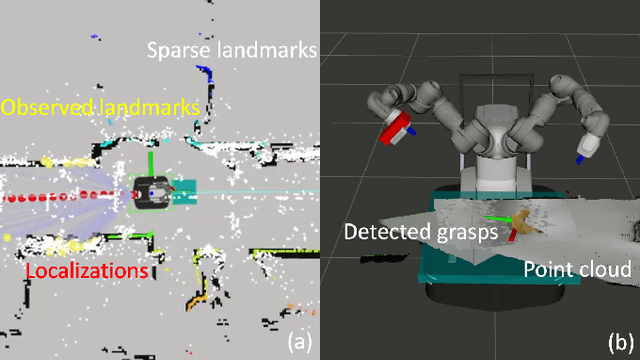
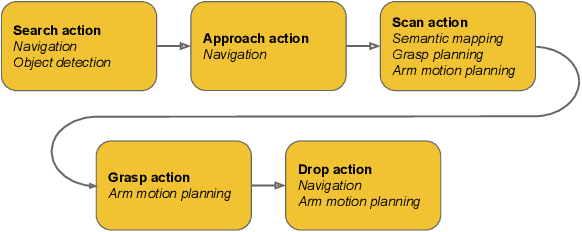
With humankind facing new and increasingly large-scale challenges in the medical and domestic spheres, automation of the service sector carries a tremendous potential for improved efficiency, quality, and safety of operations. Mobile robotics can offer solutions with a high degree of mobility and dexterity, however these complex systems require a multitude of heterogeneous components to be carefully integrated into one consistent framework. This work presents a mobile manipulation system that combines perception, localization, navigation, motion planning and grasping skills into one common workflow for fetch and carry applications in unstructured indoor environments. The tight integration across the various modules is experimentally demonstrated on the task of finding a commonly available object in an office environment, grasping it, and delivering it to a desired drop-off location. The accompanying video is available at https://youtu.be/e89_Xg1sLnY.
Deep convolutional Gaussian processes
Oct 06, 2018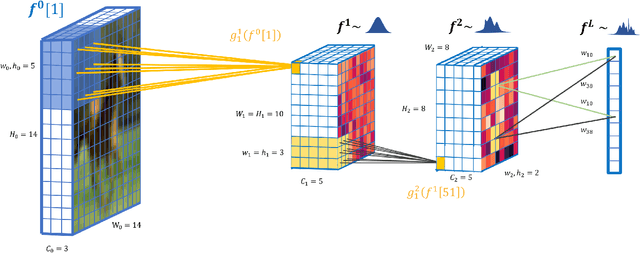
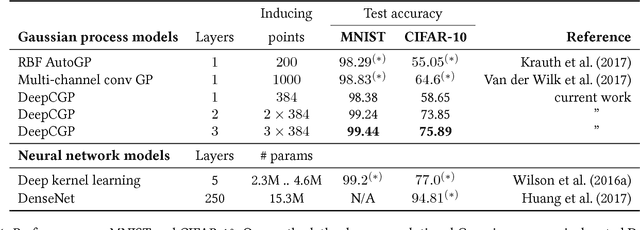
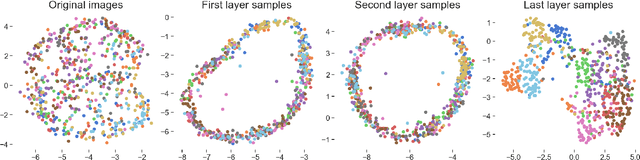
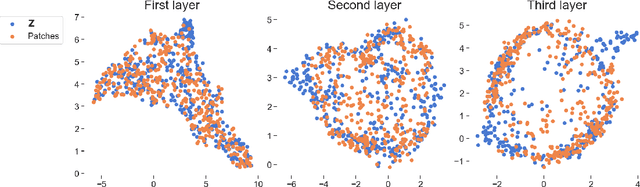
We propose deep convolutional Gaussian processes, a deep Gaussian process architecture with convolutional structure. The model is a principled Bayesian framework for detecting hierarchical combinations of local features for image classification. We demonstrate greatly improved image classification performance compared to current Gaussian process approaches on the MNIST and CIFAR-10 datasets. In particular, we improve CIFAR-10 accuracy by over 10 percentage points.