 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePoints2Vec: Unsupervised Object-level Feature Learning from Point Clouds
Paper and Code
Feb 08, 2021
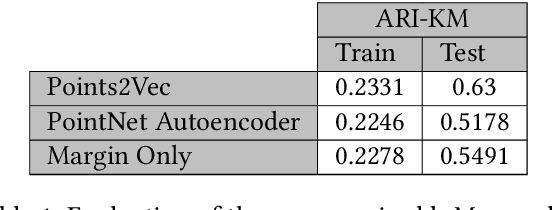
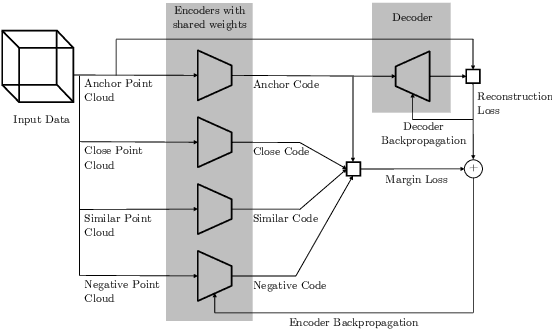
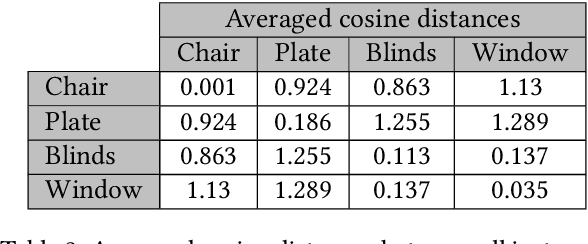
Unsupervised representation learning techniques, such as learning word embeddings, have had a significant impact on the field of natural language processing. Similar representation learning techniques have not yet become commonplace in the context of 3D vision. This, despite the fact that the physical 3D spaces have a similar semantic structure to bodies of text: words are surrounded by words that are semantically related, just like objects are surrounded by other objects that are similar in concept and usage. In this work, we exploit this structure in learning semantically meaningful low dimensional vector representations of objects. We learn these vector representations by mining a dataset of scanned 3D spaces using an unsupervised algorithm. We represent objects as point clouds, a flexible and general representation for 3D data, which we encode into a vector representation. We show that using our method to include context increases the ability of a clustering algorithm to distinguish different semantic classes from each other. Furthermore, we show that our algorithm produces continuous and meaningful object embeddings through interpolation experiments.