 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge3D Annotation Of Arbitrary Objects In The Wild
Sep 15, 2021



Recent years have produced a variety of learning based methods in the context of computer vision and robotics. Most of the recently proposed methods are based on deep learning, which require very large amounts of data compared to traditional methods. The performance of the deep learning methods are largely dependent on the data distribution they were trained on, and it is important to use data from the robot's actual operating domain during training. Therefore, it is not possible to rely on pre-built, generic datasets when deploying robots in real environments, creating a need for efficient data collection and annotation in the specific operating conditions the robots will operate in. The challenge is then: how do we reduce the cost of obtaining such datasets to a point where we can easily deploy our robots in new conditions, environments and to support new sensors? As an answer to this question, we propose a data annotation pipeline based on SLAM, 3D reconstruction, and 3D-to-2D geometry. The pipeline allows creating 3D and 2D bounding boxes, along with per-pixel annotations of arbitrary objects without needing accurate 3D models of the objects prior to data collection and annotation. Our results showcase almost 90% Intersection-over-Union (IoU) agreement on both semantic segmentation and 2D bounding box detection across a variety of objects and scenes, while speeding up the annotation process by several orders of magnitude compared to traditional manual annotation.
Closing the Sim2Real Gap in Dynamic Cloth Manipulation
Sep 10, 2021
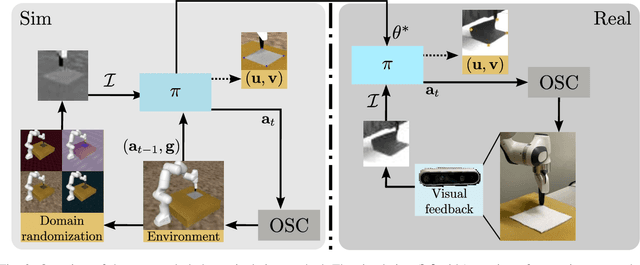
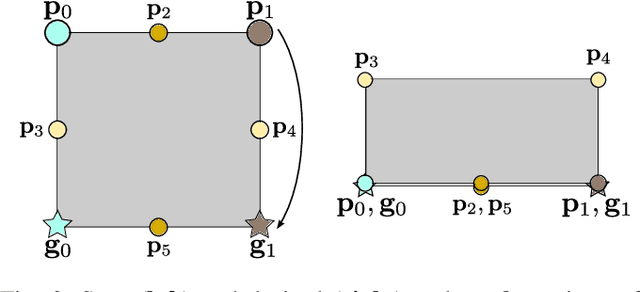
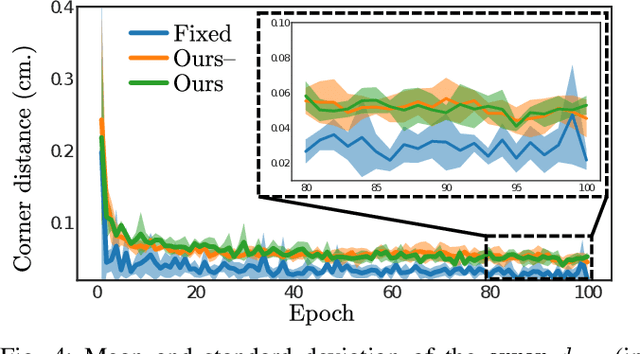
Cloth manipulation is a challenging task due to the many degrees of freedom and properties of the material affecting the dynamics of the cloth. The nonlinear dynamics of the cloth have particularly strong significance in dynamic cloth manipulation, where some parts of the cloth are not directly controllable. In this paper, we present a novel approach for solving dynamic cloth manipulation by training policies using reinforcement learning (RL) in simulation and transferring the learned policies to the real world in a zero-shot manner. The proposed method uses visual feedback and material property randomization in a physics simulator to achieve generalization in the real world. Experimental results show that using only visual feedback is enough for the policies to learn the dynamic manipulation task in a way that transfers from simulation to the real world. In addition, the randomization of the dynamics in simulation enables capturing the behavior of a variety of cloths in the real world.