 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTrajectory Planning and Control for Robotic Magnetic Manipulation
Nov 22, 2024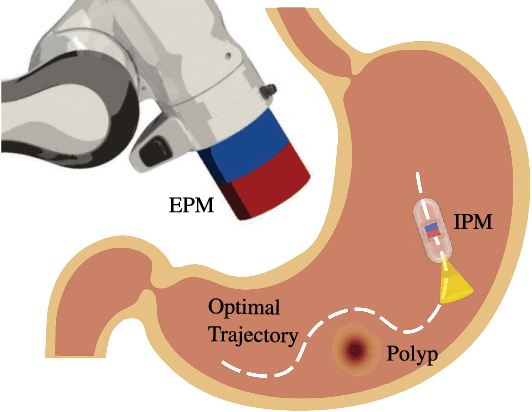
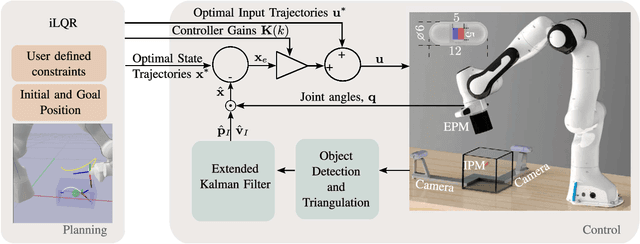
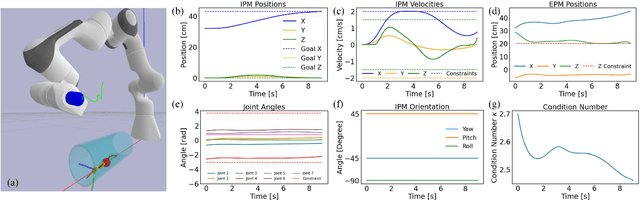
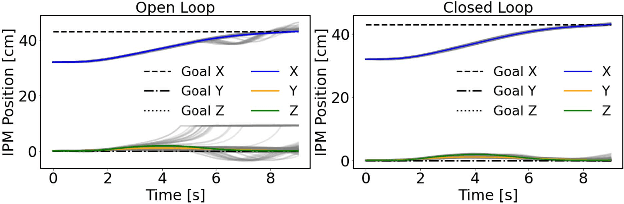
Robotic magnetic manipulation offers a minimally invasive approach to gastrointestinal examinations through capsule endoscopy. However, controlling such systems using external permanent magnets (EPM) is challenging due to nonlinear magnetic interactions, especially when there are complex navigation requirements such as avoidance of sensitive tissues. In this work, we present a novel trajectory planning and control method incorporating dynamics and navigation requirements, using a single EPM fixed to a robotic arm to manipulate an internal permanent magnet (IPM). Our approach employs a constrained iterative linear quadratic regulator that considers the dynamics of the IPM to generate optimal trajectories for both the EPM and IPM. Extensive simulations and real-world experiments, motivated by capsule endoscopy operations, demonstrate the robustness of the method, showcasing resilience to external disturbances and precise control under varying conditions. The experimental results show that the IPM reaches the goal position with a maximum mean error of 0.18 cm and a standard deviation of 0.21 cm. This work introduces a unified framework for constrained trajectory optimization in magnetic manipulation, directly incorporating both the IPM's dynamics and the EPM's manipulability.
Learning Transparent Reward Models via Unsupervised Feature Selection
Oct 24, 2024In complex real-world tasks such as robotic manipulation and autonomous driving, collecting expert demonstrations is often more straightforward than specifying precise learning objectives and task descriptions. Learning from expert data can be achieved through behavioral cloning or by learning a reward function, i.e., inverse reinforcement learning. The latter allows for training with additional data outside the training distribution, guided by the inferred reward function. We propose a novel approach to construct compact and transparent reward models from automatically selected state features. These inferred rewards have an explicit form and enable the learning of policies that closely match expert behavior by training standard reinforcement learning algorithms from scratch. We validate our method's performance in various robotic environments with continuous and high-dimensional state spaces. Webpage: \url{https://sites.google.com/view/transparent-reward}.
Data-driven Diffusion Models for Enhancing Safety in Autonomous Vehicle Traffic Simulations
Oct 07, 2024Safety-critical traffic scenarios are integral to the development and validation of autonomous driving systems. These scenarios provide crucial insights into vehicle responses under high-risk conditions rarely encountered in real-world settings. Recent advancements in critical scenario generation have demonstrated the superiority of diffusion-based approaches over traditional generative models in terms of effectiveness and realism. However, current diffusion-based methods fail to adequately address the complexity of driver behavior and traffic density information, both of which significantly influence driver decision-making processes. In this work, we present a novel approach to overcome these limitations by introducing adversarial guidance functions for diffusion models that incorporate behavior complexity and traffic density, thereby enhancing the generation of more effective and realistic safety-critical traffic scenarios. The proposed method is evaluated on two evaluation metrics: effectiveness and realism.The proposed method is evaluated on two evaluation metrics: effectiveness and realism, demonstrating better efficacy as compared to other state-of-the-art methods.
Automated Feature Selection for Inverse Reinforcement Learning
Mar 22, 2024Inverse reinforcement learning (IRL) is an imitation learning approach to learning reward functions from expert demonstrations. Its use avoids the difficult and tedious procedure of manual reward specification while retaining the generalization power of reinforcement learning. In IRL, the reward is usually represented as a linear combination of features. In continuous state spaces, the state variables alone are not sufficiently rich to be used as features, but which features are good is not known in general. To address this issue, we propose a method that employs polynomial basis functions to form a candidate set of features, which are shown to allow the matching of statistical moments of state distributions. Feature selection is then performed for the candidates by leveraging the correlation between trajectory probabilities and feature expectations. We demonstrate the approach's effectiveness by recovering reward functions that capture expert policies across non-linear control tasks of increasing complexity. Code, data, and videos are available at https://sites.google.com/view/feature4irl.
The Role of Higher-Order Cognitive Models in Active Learning
Jan 09, 2024Building machines capable of efficiently collaborating with humans has been a longstanding goal in artificial intelligence. Especially in the presence of uncertainties, optimal cooperation often requires that humans and artificial agents model each other's behavior and use these models to infer underlying goals, beliefs or intentions, potentially involving multiple levels of recursion. Empirical evidence for such higher-order cognition in human behavior is also provided by previous works in cognitive science, linguistics, and robotics. We advocate for a new paradigm for active learning for human feedback that utilises humans as active data sources while accounting for their higher levels of agency. In particular, we discuss how increasing level of agency results in qualitatively different forms of rational communication between an active learning system and a teacher. Additionally, we provide a practical example of active learning using a higher-order cognitive model. This is accompanied by a computational study that underscores the unique behaviors that this model produces.
Challenges of Data-Driven Simulation of Diverse and Consistent Human Driving Behaviors
Jan 06, 2024Building simulation environments for developing and testing autonomous vehicles necessitates that the simulators accurately model the statistical realism of the real-world environment, including the interaction with other vehicles driven by human drivers. To address this requirement, an accurate human behavior model is essential to incorporate the diversity and consistency of human driving behavior. We propose a mathematical framework for designing a data-driven simulation model that simulates human driving behavior more realistically than the currently used physics-based simulation models. Experiments conducted using the NGSIM dataset validate our hypothesis regarding the necessity of considering the complexity, diversity, and consistency of human driving behavior when aiming to develop realistic simulators.
Benchmarking the Sim-to-Real Gap in Cloth Manipulation
Oct 14, 2023Realistic physics engines play a crucial role for learning to manipulate deformable objects such as garments in simulation. By doing so, researchers can circumvent challenges such as sensing the deformation of the object in the real-world. In spite of the extensive use of simulations for this task, few works have evaluated the reality gap between deformable object simulators and real-world data. We present a benchmark dataset to evaluate the sim-to-real gap in cloth manipulation. The dataset is collected by performing a dynamic cloth manipulation task involving contact with a rigid table. We use the dataset to evaluate the reality gap, computational time, and simulation stability of four popular deformable object simulators: MuJoCo, Bullet, Flex, and SOFA. Additionally, we discuss the benefits and drawbacks of each simulator. The benchmark dataset is open-source. Supplementary material, videos, and code, can be found at https://sites.google.com/view/cloth-sim2real-benchmark.
Integrating Expert Guidance for Efficient Learning of Safe Overtaking in Autonomous Driving Using Deep Reinforcement Learning
Aug 18, 2023



Overtaking on two-lane roads is a great challenge for autonomous vehicles, as oncoming traffic appearing on the opposite lane may require the vehicle to change its decision and abort the overtaking. Deep reinforcement learning (DRL) has shown promise for difficult decision problems such as this, but it requires massive number of data, especially if the action space is continuous. This paper proposes to incorporate guidance from an expert system into DRL to increase its sample efficiency in the autonomous overtaking setting. The guidance system developed in this study is composed of constrained iterative LQR and PID controllers. The novelty lies in the incorporation of a fading guidance function, which gradually decreases the effect of the expert system, allowing the agent to initially learn an appropriate action swiftly and then improve beyond the performance of the expert system. This approach thus combines the strengths of traditional control engineering with the flexibility of learning systems, expanding the capabilities of the autonomous system. The proposed methodology for autonomous vehicle overtaking does not depend on a particular DRL algorithm and three state-of-the-art algorithms are used as baselines for evaluation. Simulation results show that incorporating expert system guidance improves state-of-the-art DRL algorithms greatly in both sample efficiency and driving safety.
QDP: Learning to Sequentially Optimise Quasi-Static and Dynamic Manipulation Primitives for Robotic Cloth Manipulation
Mar 23, 2023Pre-defined manipulation primitives are widely used for cloth manipulation. However, cloth properties such as its stiffness or density can highly impact the performance of these primitives. Although existing solutions have tackled the parameterisation of pick and place locations, the effect of factors such as the velocity or trajectory of quasi-static and dynamic manipulation primitives has been neglected. Choosing appropriate values for these parameters is crucial to cope with the range of materials present in house-hold cloth objects. To address this challenge, we introduce the Quasi-Dynamic Parameterisable (QDP) method, which optimises parameters such as the motion velocity in addition to the pick and place positions of quasi-static and dynamic manipulation primitives. In this work, we leverage the framework of Sequential Reinforcement Learning to decouple sequentially the parameters that compose the primitives. To evaluate the effectiveness of the method we focus on the task of cloth unfolding with a robotic arm in simulation and real-world experiments. Our results in simulation show that by deciding the optimal parameters for the primitives the performance can improve by 20% compared to sub-optimal ones. Real-world results demonstrate the advantage of modifying the velocity and height of manipulation primitives for cloths with different mass, stiffness, shape and size. Supplementary material, videos, and code, can be found at https://sites.google.com/view/qdp-srl.
Trajectory Optimization on Matrix Lie Groups with Differential Dynamic Programming and Nonlinear Constraints
Jan 05, 2023



Matrix Lie groups are an important class of manifolds commonly used in control and robotics, and the optimization of control policies on these manifolds is a fundamental problem. In this work, we propose a novel approach for trajectory optimization on matrix Lie groups using an augmented Lagrangian based constrained discrete Differential Dynamic Programming (DDP) algorithm. Our method involves lifting the optimization problem to the Lie algebra in the backward pass and retracting back to the manifold in the forward pass. In contrast to previous approaches which only addressed constraint handling for specific classes of matrix Lie groups, our method provides a general approach for nonlinear constraint handling for a generic matrix Lie groups. We also demonstrate the effectiveness of our method in handling external disturbances through its application as a Lie-algebraic feedback control policy on SE(3). The results show that our approach is able to effectively handle configuration, velocity and input constraints and maintain stability in the presence of external disturbances.