 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Role of Higher-Order Cognitive Models in Active Learning
Jan 09, 2024Building machines capable of efficiently collaborating with humans has been a longstanding goal in artificial intelligence. Especially in the presence of uncertainties, optimal cooperation often requires that humans and artificial agents model each other's behavior and use these models to infer underlying goals, beliefs or intentions, potentially involving multiple levels of recursion. Empirical evidence for such higher-order cognition in human behavior is also provided by previous works in cognitive science, linguistics, and robotics. We advocate for a new paradigm for active learning for human feedback that utilises humans as active data sources while accounting for their higher levels of agency. In particular, we discuss how increasing level of agency results in qualitatively different forms of rational communication between an active learning system and a teacher. Additionally, we provide a practical example of active learning using a higher-order cognitive model. This is accompanied by a computational study that underscores the unique behaviors that this model produces.
Amortised Design Optimization for Item Response Theory
Jul 19, 2023Item Response Theory (IRT) is a well known method for assessing responses from humans in education and psychology. In education, IRT is used to infer student abilities and characteristics of test items from student responses. Interactions with students are expensive, calling for methods that efficiently gather information for inferring student abilities. Methods based on Optimal Experimental Design (OED) are computationally costly, making them inapplicable for interactive applications. In response, we propose incorporating amortised experimental design into IRT. Here, the computational cost is shifted to a precomputing phase by training a Deep Reinforcement Learning (DRL) agent with synthetic data. The agent is trained to select optimally informative test items for the distribution of students, and to conduct amortised inference conditioned on the experiment outcomes. During deployment the agent estimates parameters from data, and suggests the next test item for the student, in close to real-time, by taking into account the history of experiments and outcomes.
Amortised Experimental Design and Parameter Estimation for User Models of Pointing
Jul 19, 2023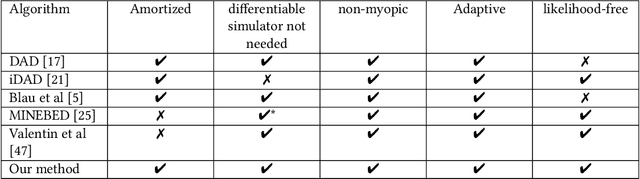
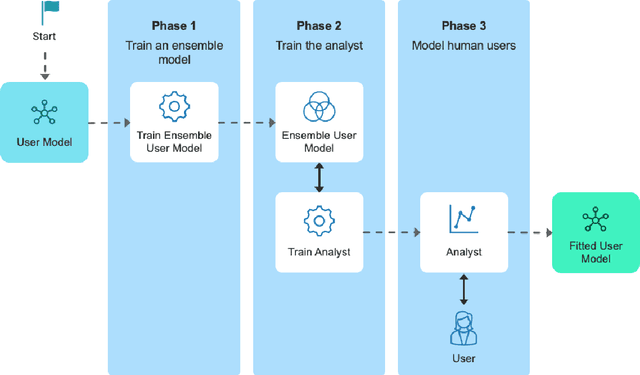
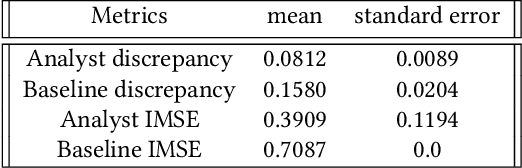
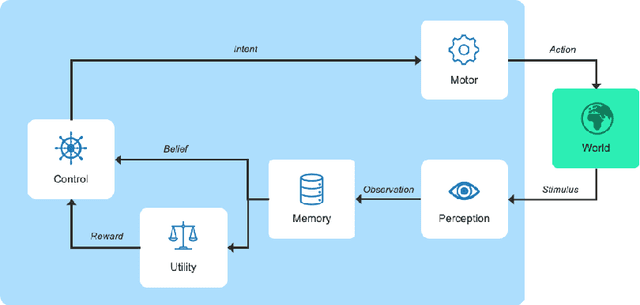
User models play an important role in interaction design, supporting automation of interaction design choices. In order to do so, model parameters must be estimated from user data. While very large amounts of user data are sometimes required, recent research has shown how experiments can be designed so as to gather data and infer parameters as efficiently as possible, thereby minimising the data requirement. In the current article, we investigate a variant of these methods that amortises the computational cost of designing experiments by training a policy for choosing experimental designs with simulated participants. Our solution learns which experiments provide the most useful data for parameter estimation by interacting with in-silico agents sampled from the model space thereby using synthetic data rather than vast amounts of human data. The approach is demonstrated for three progressively complex models of pointing.