 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRelational Scene Graphs for Object Grounding of Natural Language Commands
Feb 04, 2026Robots are finding wider adoption in human environments, increasing the need for natural human-robot interaction. However, understanding a natural language command requires the robot to infer the intended task and how to decompose it into executable actions, and to ground those actions in the robot's knowledge of the environment, including relevant objects, agents, and locations. This challenge can be addressed by combining the capabilities of Large language models (LLMs) to understand natural language with 3D scene graphs (3DSGs) for grounding inferred actions in a semantic representation of the environment. However, many 3DSGs lack explicit spatial relations between objects, even though humans often rely on these relations to describe an environment. This paper investigates whether incorporating open- or closed-vocabulary spatial relations into 3DSGs can improve the ability of LLMs to interpret natural language commands. To address this, we propose an LLM-based pipeline for target object grounding from open-vocabulary language commands and a vision language model (VLM)-based pipeline to add open-vocabulary spatial edges to 3DSGs from images captured while mapping. Finally, two LLMs are evaluated in a study assessing their performance on the downstream task of target object grounding. Our study demonstrates that explicit spatial relations improve the ability of LLMs to ground objects. Moreover, open-vocabulary relation generation with VLMs proves feasible from robot-captured images, but their advantage over closed-vocabulary relations is found to be limited.
A Lightweight Crowd Model for Robot Social Navigation
Aug 27, 2025Robots operating in human-populated environments must navigate safely and efficiently while minimizing social disruption. Achieving this requires estimating crowd movement to avoid congested areas in real-time. Traditional microscopic models struggle to scale in dense crowds due to high computational cost, while existing macroscopic crowd prediction models tend to be either overly simplistic or computationally intensive. In this work, we propose a lightweight, real-time macroscopic crowd prediction model tailored for human motion, which balances prediction accuracy and computational efficiency. Our approach simplifies both spatial and temporal processing based on the inherent characteristics of pedestrian flow, enabling robust generalization without the overhead of complex architectures. We demonstrate a 3.6 times reduction in inference time, while improving prediction accuracy by 3.1 %. Integrated into a socially aware planning framework, the model enables efficient and socially compliant robot navigation in dynamic environments. This work highlights that efficient human crowd modeling enables robots to navigate dense environments without costly computations.
Efficient Human-Aware Task Allocation for Multi-Robot Systems in Shared Environments
Aug 27, 2025Multi-robot systems are increasingly deployed in applications, such as intralogistics or autonomous delivery, where multiple robots collaborate to complete tasks efficiently. One of the key factors enabling their efficient cooperation is Multi-Robot Task Allocation (MRTA). Algorithms solving this problem optimize task distribution among robots to minimize the overall execution time. In shared environments, apart from the relative distance between the robots and the tasks, the execution time is also significantly impacted by the delay caused by navigating around moving people. However, most existing MRTA approaches are dynamics-agnostic, relying on static maps and neglecting human motion patterns, leading to inefficiencies and delays. In this paper, we introduce \acrfull{method name}. This method leverages Maps of Dynamics (MoDs), spatio-temporal queryable models designed to capture historical human movement patterns, to estimate the impact of humans on the task execution time during deployment. \acrshort{method name} utilizes a stochastic cost function that includes MoDs. Experimental results show that integrating MoDs enhances task allocation performance, resulting in reduced mission completion times by up to $26\%$ compared to the dynamics-agnostic method and up to $19\%$ compared to the baseline. This work underscores the importance of considering human dynamics in MRTA within shared environments and presents an efficient framework for deploying multi-robot systems in environments populated by humans.
MoDeSuite: Robot Learning Task Suite for Benchmarking Mobile Manipulation with Deformable Objects
Jul 29, 2025Mobile manipulation is a critical capability for robots operating in diverse, real-world environments. However, manipulating deformable objects and materials remains a major challenge for existing robot learning algorithms. While various benchmarks have been proposed to evaluate manipulation strategies with rigid objects, there is still a notable lack of standardized benchmarks that address mobile manipulation tasks involving deformable objects. To address this gap, we introduce MoDeSuite, the first Mobile Manipulation Deformable Object task suite, designed specifically for robot learning. MoDeSuite consists of eight distinct mobile manipulation tasks covering both elastic objects and deformable objects, each presenting a unique challenge inspired by real-world robot applications. Success in these tasks requires effective collaboration between the robot's base and manipulator, as well as the ability to exploit the deformability of the objects. To evaluate and demonstrate the use of the proposed benchmark, we train two state-of-the-art reinforcement learning algorithms and two imitation learning algorithms, highlighting the difficulties encountered and showing their performance in simulation. Furthermore, we demonstrate the practical relevance of the suite by deploying the trained policies directly into the real world with the Spot robot, showcasing the potential for sim-to-real transfer. We expect that MoDeSuite will open a novel research domain in mobile manipulation involving deformable objects. Find more details, code, and videos at https://sites.google.com/view/modesuite/home.
MISC: Minimal Intervention Shared Control with Guaranteed Safety under Non-Convex Constraints
Jul 03, 2025Shared control combines human intention with autonomous decision-making, from low-level safety overrides to high-level task guidance, enabling systems that adapt to users while ensuring safety and performance. This enhances task effectiveness and user experience across domains such as assistive robotics, teleoperation, and autonomous driving. However, existing shared control methods, based on e.g. Model Predictive Control, Control Barrier Functions, or learning-based control, struggle with feasibility, scalability, or safety guarantees, particularly since the user input is unpredictable. To address these challenges, we propose an assistive controller framework based on Constrained Optimal Control Problem that incorporates an offline-computed Control Invariant Set, enabling online computation of control actions that ensure feasibility, strict constraint satisfaction, and minimal override of user intent. Moreover, the framework can accommodate structured class of non-convex constraints, which are common in real-world scenarios. We validate the approach through a large-scale user study with 66 participants--one of the most extensive in shared control research--using a computer game environment to assess task load, trust, and perceived control, in addition to performance. The results show consistent improvements across all these aspects without compromising safety and user intent.
Combining Bayesian Inference and Reinforcement Learning for Agent Decision Making: A Review
May 12, 2025Bayesian inference has many advantages in decision making of agents (e.g. robotics/simulative agent) over a regular data-driven black-box neural network: Data-efficiency, generalization, interpretability, and safety where these advantages benefit directly/indirectly from the uncertainty quantification of Bayesian inference. However, there are few comprehensive reviews to summarize the progress of Bayesian inference on reinforcement learning (RL) for decision making to give researchers a systematic understanding. This paper focuses on combining Bayesian inference with RL that nowadays is an important approach in agent decision making. To be exact, this paper discusses the following five topics: 1) Bayesian methods that have potential for agent decision making. First basic Bayesian methods and models (Bayesian rule, Bayesian learning, and Bayesian conjugate models) are discussed followed by variational inference, Bayesian optimization, Bayesian deep learning, Bayesian active learning, Bayesian generative models, Bayesian meta-learning, and lifelong Bayesian learning. 2) Classical combinations of Bayesian methods with model-based RL (with approximation methods), model-free RL, and inverse RL. 3) Latest combinations of potential Bayesian methods with RL. 4) Analytical comparisons of methods that combine Bayesian methods with RL with respect to data-efficiency, generalization, interpretability, and safety. 5) In-depth discussions in six complex problem variants of RL, including unknown reward, partial-observability, multi-agent, multi-task, non-linear non-Gaussian, and hierarchical RL problems and the summary of how Bayesian methods work in the data collection, data processing and policy learning stages of RL to pave the way for better agent decision-making strategies.
Discrete Contrastive Learning for Diffusion Policies in Autonomous Driving
Mar 07, 2025Learning to perform accurate and rich simulations of human driving behaviors from data for autonomous vehicle testing remains challenging due to human driving styles' high diversity and variance. We address this challenge by proposing a novel approach that leverages contrastive learning to extract a dictionary of driving styles from pre-existing human driving data. We discretize these styles with quantization, and the styles are used to learn a conditional diffusion policy for simulating human drivers. Our empirical evaluation confirms that the behaviors generated by our approach are both safer and more human-like than those of the machine-learning-based baseline methods. We believe this has the potential to enable higher realism and more effective techniques for evaluating and improving the performance of autonomous vehicles.
REACT: Real-time Efficient Attribute Clustering and Transfer for Updatable 3D Scene Graph
Mar 05, 2025Modern-day autonomous robots need high-level map representations to perform sophisticated tasks. Recently, 3D scene graphs (3DSGs) have emerged as a promising alternative to traditional grid maps, blending efficient memory use and rich feature representation. However, most efforts to apply them have been limited to static worlds. This work introduces REACT, a framework that efficiently performs real-time attribute clustering and transfer to relocalize object nodes in a 3DSG. REACT employs a novel method for comparing object instances using an embedding model trained on triplet loss, facilitating instance clustering and matching. Experimental results demonstrate that REACT is able to relocalize objects while maintaining computational efficiency. The REACT framework's source code will be available as an open-source project, promoting further advancements in reusable and updatable 3DSGs.
Transfer Learning in Latent Contextual Bandits with Covariate Shift Through Causal Transportability
Feb 27, 2025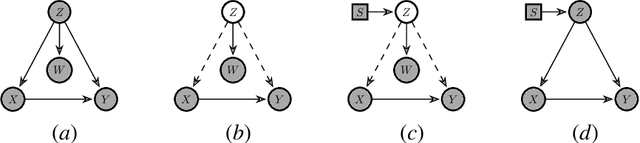
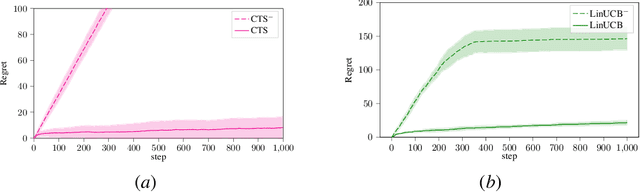
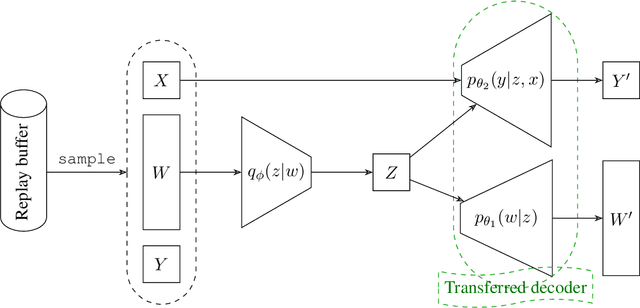
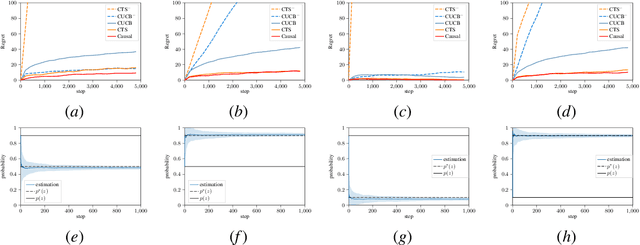
Transferring knowledge from one environment to another is an essential ability of intelligent systems. Nevertheless, when two environments are different, naively transferring all knowledge may deteriorate the performance, a phenomenon known as negative transfer. In this paper, we address this issue within the framework of multi-armed bandits from the perspective of causal inference. Specifically, we consider transfer learning in latent contextual bandits, where the actual context is hidden, but a potentially high-dimensional proxy is observable. We further consider a covariate shift in the context across environments. We show that naively transferring all knowledge for classical bandit algorithms in this setting led to negative transfer. We then leverage transportability theory from causal inference to develop algorithms that explicitly transfer effective knowledge for estimating the causal effects of interest in the target environment. Besides, we utilize variational autoencoders to approximate causal effects under the presence of a high-dimensional proxy. We test our algorithms on synthetic and semi-synthetic datasets, empirically demonstrating consistently improved learning efficiency across different proxies compared to baseline algorithms, showing the effectiveness of our causal framework in transferring knowledge.
Trajectory Planning and Control for Robotic Magnetic Manipulation
Nov 22, 2024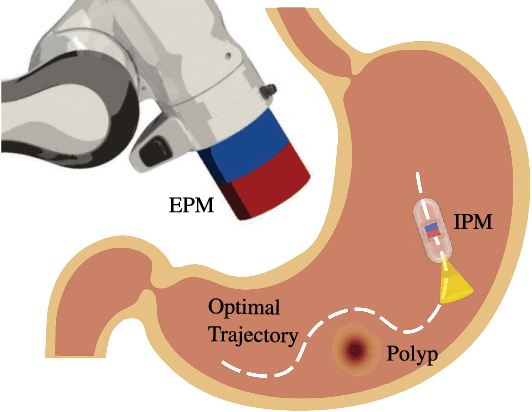
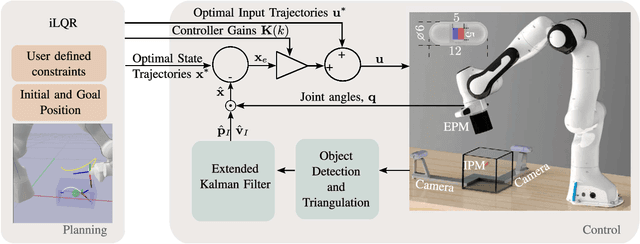
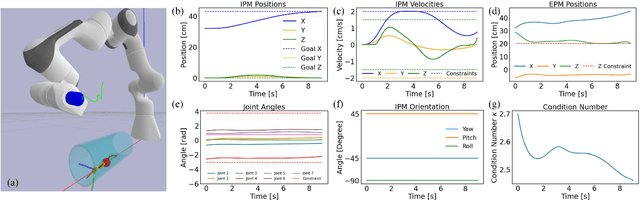
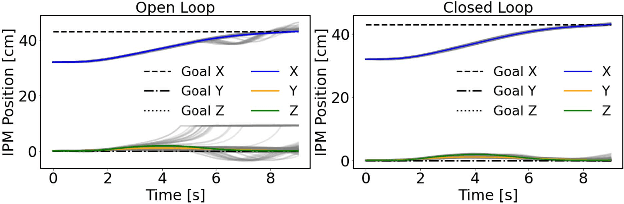
Robotic magnetic manipulation offers a minimally invasive approach to gastrointestinal examinations through capsule endoscopy. However, controlling such systems using external permanent magnets (EPM) is challenging due to nonlinear magnetic interactions, especially when there are complex navigation requirements such as avoidance of sensitive tissues. In this work, we present a novel trajectory planning and control method incorporating dynamics and navigation requirements, using a single EPM fixed to a robotic arm to manipulate an internal permanent magnet (IPM). Our approach employs a constrained iterative linear quadratic regulator that considers the dynamics of the IPM to generate optimal trajectories for both the EPM and IPM. Extensive simulations and real-world experiments, motivated by capsule endoscopy operations, demonstrate the robustness of the method, showcasing resilience to external disturbances and precise control under varying conditions. The experimental results show that the IPM reaches the goal position with a maximum mean error of 0.18 cm and a standard deviation of 0.21 cm. This work introduces a unified framework for constrained trajectory optimization in magnetic manipulation, directly incorporating both the IPM's dynamics and the EPM's manipulability.