 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScore-based Integrated Gradient for Root Cause Explanations of Outliers
Jan 29, 2026Identifying the root causes of outliers is a fundamental problem in causal inference and anomaly detection. Traditional approaches based on heuristics or counterfactual reasoning often struggle under uncertainty and high-dimensional dependencies. We introduce SIREN, a novel and scalable method that attributes the root causes of outliers by estimating the score functions of the data likelihood. Attribution is computed via integrated gradients that accumulate score contributions along paths from the outlier toward the normal data distribution. Our method satisfies three of the four classic Shapley value axioms - dummy, efficiency, and linearity - as well as an asymmetry axiom derived from the underlying causal structure. Unlike prior work, SIREN operates directly on the score function, enabling tractable and uncertainty-aware root cause attribution in nonlinear, high-dimensional, and heteroscedastic causal models. Extensive experiments on synthetic random graphs and real-world cloud service and supply chain datasets show that SIREN outperforms state-of-the-art baselines in both attribution accuracy and computational efficiency.
Robust SDE Parameter Estimation Under Missing Time Information Setting
Jan 28, 2026Recent advances in stochastic differential equations (SDEs) have enabled robust modeling of real-world dynamical processes across diverse domains, such as finance, health, and systems biology. However, parameter estimation for SDEs typically relies on accurately timestamped observational sequences. When temporal ordering information is corrupted, missing, or deliberately hidden (e.g., for privacy), existing estimation methods often fail. In this paper, we investigate the conditions under which temporal order can be recovered and introduce a novel framework that simultaneously reconstructs temporal information and estimates SDE parameters. Our approach exploits asymmetries between forward and backward processes, deriving a score-matching criterion to infer the correct temporal order between pairs of observations. We then recover the total order via a sorting procedure and estimate SDE parameters from the reconstructed sequence using maximum likelihood. Finally, we conduct extensive experiments on synthetic and real-world datasets to demonstrate the effectiveness of our method, extending parameter estimation to settings with missing temporal order and broadening applicability in sensitive domains.
Identifying Causal Direction via Variational Bayesian Compression
May 12, 2025Telling apart the cause and effect between two random variables with purely observational data is a challenging problem that finds applications in various scientific disciplines. A key principle utilized in this task is the algorithmic Markov condition, which postulates that the joint distribution, when factorized according to the causal direction, yields a more succinct codelength compared to the anti-causal direction. Previous approaches approximate these codelengths by relying on simple functions or Gaussian processes (GPs) with easily evaluable complexity, compromising between model fitness and computational complexity. To overcome these limitations, we propose leveraging the variational Bayesian learning of neural networks as an interpretation of the codelengths. Consequently, we can enhance the model fitness while promoting the succinctness of the codelengths, while avoiding the significant computational complexity of the GP-based approaches. Extensive experiments on both synthetic and real-world benchmarks in cause-effect identification demonstrate the effectiveness of our proposed method, surpassing the overall performance of related complexity-based and structural causal model regression-based approaches.
REACT: Real-time Efficient Attribute Clustering and Transfer for Updatable 3D Scene Graph
Mar 05, 2025Modern-day autonomous robots need high-level map representations to perform sophisticated tasks. Recently, 3D scene graphs (3DSGs) have emerged as a promising alternative to traditional grid maps, blending efficient memory use and rich feature representation. However, most efforts to apply them have been limited to static worlds. This work introduces REACT, a framework that efficiently performs real-time attribute clustering and transfer to relocalize object nodes in a 3DSG. REACT employs a novel method for comparing object instances using an embedding model trained on triplet loss, facilitating instance clustering and matching. Experimental results demonstrate that REACT is able to relocalize objects while maintaining computational efficiency. The REACT framework's source code will be available as an open-source project, promoting further advancements in reusable and updatable 3DSGs.
Evaluating Text Summaries Generated by Large Language Models Using OpenAI's GPT
May 07, 2024This research examines the effectiveness of OpenAI's GPT models as independent evaluators of text summaries generated by six transformer-based models from Hugging Face: DistilBART, BERT, ProphetNet, T5, BART, and PEGASUS. We evaluated these summaries based on essential properties of high-quality summary - conciseness, relevance, coherence, and readability - using traditional metrics such as ROUGE and Latent Semantic Analysis (LSA). Uniquely, we also employed GPT not as a summarizer but as an evaluator, allowing it to independently assess summary quality without predefined metrics. Our analysis revealed significant correlations between GPT evaluations and traditional metrics, particularly in assessing relevance and coherence. The results demonstrate GPT's potential as a robust tool for evaluating text summaries, offering insights that complement established metrics and providing a basis for comparative analysis of transformer-based models in natural language processing tasks.
Root Cause Explanation of Outliers under Noisy Mechanisms
Dec 19, 2023Identifying root causes of anomalies in causal processes is vital across disciplines. Once identified, one can isolate the root causes and implement necessary measures to restore the normal operation. Causal processes are often modelled as graphs with entities being nodes and their paths/interconnections as edge. Existing work only consider the contribution of nodes in the generative process, thus can not attribute the outlier score to the edges of the mechanism if the anomaly occurs in the connections. In this paper, we consider both individual edge and node of each mechanism when identifying the root causes. We introduce a noisy functional causal model to account for this purpose. Then, we employ Bayesian learning and inference methods to infer the noises of the nodes and edges. We then represent the functional form of a target outlier leaf as a function of the node and edge noises. Finally, we propose an efficient gradient-based attribution method to compute the anomaly attribution scores which scales linearly with the number of nodes and edges. Experiments on simulated datasets and two real-world scenario datasets show better anomaly attribution performance of the proposed method compared to the baselines. Our method scales to larger graphs with more nodes and edges.
Robust Estimation of Causal Heteroscedastic Noise Models
Dec 15, 2023Distinguishing the cause and effect from bivariate observational data is the foundational problem that finds applications in many scientific disciplines. One solution to this problem is assuming that cause and effect are generated from a structural causal model, enabling identification of the causal direction after estimating the model in each direction. The heteroscedastic noise model is a type of structural causal model where the cause can contribute to both the mean and variance of the noise. Current methods for estimating heteroscedastic noise models choose the Gaussian likelihood as the optimization objective which can be suboptimal and unstable when the data has a non-Gaussian distribution. To address this limitation, we propose a novel approach to estimating this model with Student's $t$-distribution, which is known for its robustness in accounting for sampling variability with smaller sample sizes and extreme values without significantly altering the overall distribution shape. This adaptability is beneficial for capturing the parameters of the noise distribution in heteroscedastic noise models. Our empirical evaluations demonstrate that our estimators are more robust and achieve better overall performance across synthetic and real benchmarks.
Differentiable Bayesian Structure Learning with Acyclicity Assurance
Sep 06, 2023Score-based approaches in the structure learning task are thriving because of their scalability. Continuous relaxation has been the key reason for this advancement. Despite achieving promising outcomes, most of these methods are still struggling to ensure that the graphs generated from the latent space are acyclic by minimizing a defined score. There has also been another trend of permutation-based approaches, which concern the search for the topological ordering of the variables in the directed acyclic graph in order to limit the search space of the graph. In this study, we propose an alternative approach for strictly constraining the acyclicty of the graphs with an integration of the knowledge from the topological orderings. Our approach can reduce inference complexity while ensuring the structures of the generated graphs to be acyclic. Our empirical experiments with simulated and real-world data show that our approach can outperform related Bayesian score-based approaches.
Memory-Augmented Theory of Mind Network
Jan 17, 2023

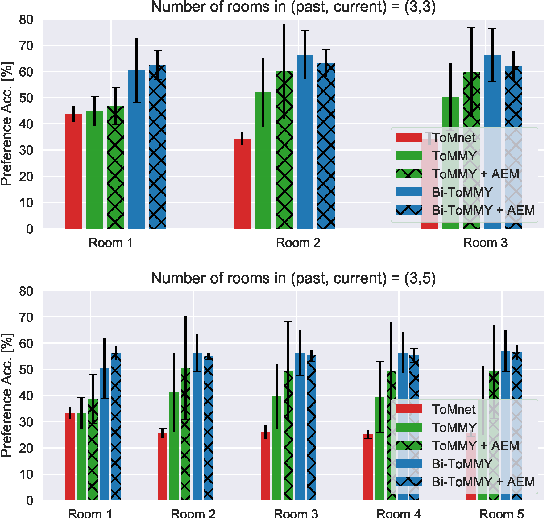

Social reasoning necessitates the capacity of theory of mind (ToM), the ability to contextualise and attribute mental states to others without having access to their internal cognitive structure. Recent machine learning approaches to ToM have demonstrated that we can train the observer to read the past and present behaviours of other agents and infer their beliefs (including false beliefs about things that no longer exist), goals, intentions and future actions. The challenges arise when the behavioural space is complex, demanding skilful space navigation for rapidly changing contexts for an extended period. We tackle the challenges by equipping the observer with novel neural memory mechanisms to encode, and hierarchical attention to selectively retrieve information about others. The memories allow rapid, selective querying of distal related past behaviours of others to deliberatively reason about their current mental state, beliefs and future behaviours. This results in ToMMY, a theory of mind model that learns to reason while making little assumptions about the underlying mental processes. We also construct a new suite of experiments to demonstrate that memories facilitate the learning process and achieve better theory of mind performance, especially for high-demand false-belief tasks that require inferring through multiple steps of changes.
Fast Conditional Network Compression Using Bayesian HyperNetworks
May 13, 2022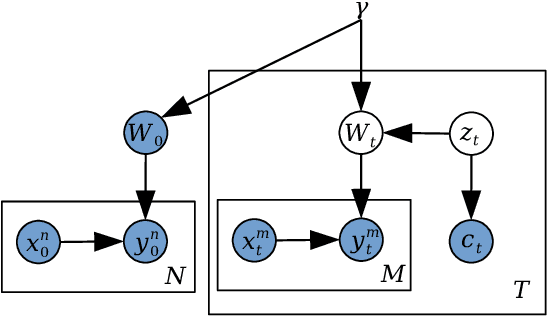
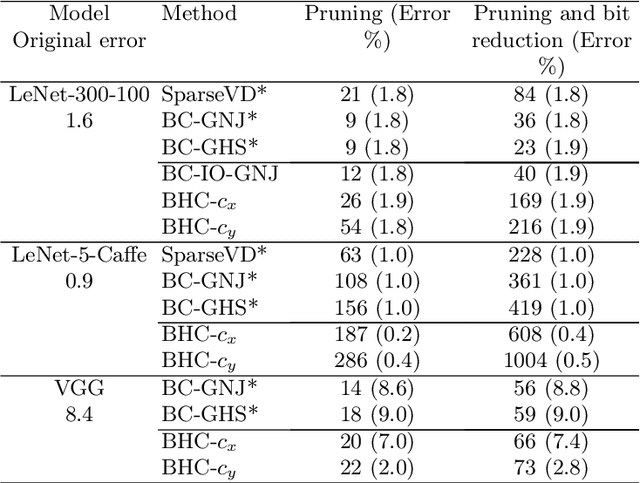
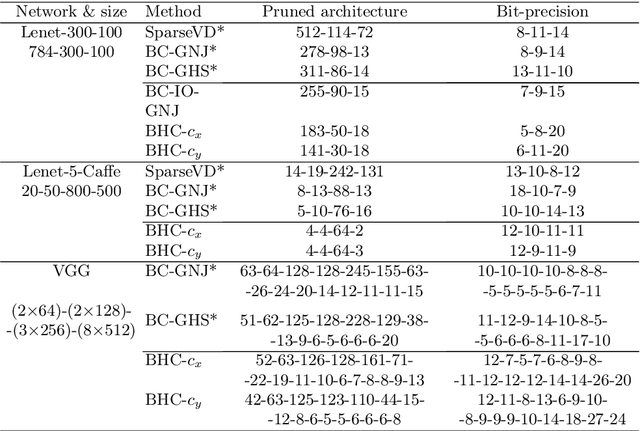
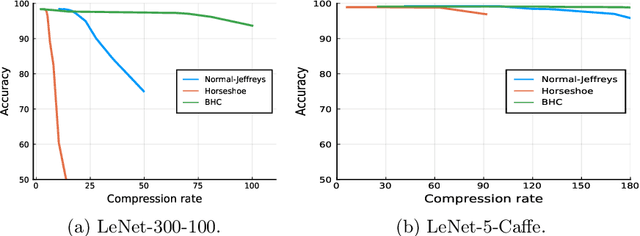
We introduce a conditional compression problem and propose a fast framework for tackling it. The problem is how to quickly compress a pretrained large neural network into optimal smaller networks given target contexts, e.g. a context involving only a subset of classes or a context where only limited compute resource is available. To solve this, we propose an efficient Bayesian framework to compress a given large network into much smaller size tailored to meet each contextual requirement. We employ a hypernetwork to parameterize the posterior distribution of weights given conditional inputs and minimize a variational objective of this Bayesian neural network. To further reduce the network sizes, we propose a new input-output group sparsity factorization of weights to encourage more sparseness in the generated weights. Our methods can quickly generate compressed networks with significantly smaller sizes than baseline methods.