 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOnlyDense: Reduced-Order Modeling for Lagrangian simulation
Jun 08, 2026In science and engineering, Lagrangian simulation methods such as Smooth Particle Hydrodynamics (SPH) or Material Point Method (MPM) are often employed to study the behavior of dynamic systems. However, these methods can be prohibitively computationally expensive, particularly when simulating multi-scale spatial or temporal phenomena, e.g., void growth and coalescence within macro-scale geometries, structural failure of spacecraft components resulting from hypervelocity impact of space debris particles, etc. In contrast to graph-based methods, where the state of the system is understood as a discrete set of particles, we propose a learning framework for scalable representation and dynamics modeling of massive particle systems by treating the system state as a function and its evolution as a trajectory in Hilbert space. Rather than representing the state as a discrete set of particles or embedding it in a nonlinear latent manifold, we approximate the state space with a linear subspace spanned by learned neural basis functions. This parameterization enables direct projection to obtain latent coefficients and explicit access to the basis functions, avoiding optimization over a nonlinear latent space. The resulting representation admits a natural interpretation: latent variables correspond to coefficients in Hilbert space, and basis functions correspond to spatial modes, analogous to Proper Orthogonal Decomposition. The framework thus unifies classical projection-based reduced-order modeling with modern deep learning, while remaining invariant to the number of discretization points. Experiments on large-scale SPH simulations with over one million particles, including dynamic events with extreme deformation and fragmentation, demonstrate that the proposed method accurately reconstructs and predicts dynamics, achieving an R$^2$ score above $0.99$ with as few as $32$ basis functions.
Shared Latent Structures Enable Unified Backdoor Detection and Mitigation in LLMs
Jun 06, 2026Backdoor attacks in large language models (LLMs) are often treated as isolated trigger-response failures, motivating defenses tailored to specific triggers or behaviors. We show this view is incomplete. Across diverse backdoor behaviors, we identify a shared latent mechanism that can be detected, causally controlled, and suppressed. Using sparse autoencoders (SAEs) on residual-stream activations, we find a small set of latent features consistently activated across jailbreaking, refusal manipulation, password-locking, bias induction, sentiment misclassification, and country-conditioned harmful advice. These features generalize across Qwen3, Gemma~3, and Llama~3.1 models from 4B to 32B parameters, and across both fine-tuning and weight-editing attacks. Through bidirectional activation steering, we show these features are causal: suppressing them reduces attack success, while amplifying them induces target behaviors on clean prompts. We further train lightweight SAE-feature classifiers that generalize zero-shot to unseen backdoors and outperform residual-stream and weight-diffing baselines. Finally, we introduce Concept Ablation Fine-Tuning (CAFT), which suppresses backdoor formation by ablating the shared latent subspace during training. Together, our results suggest that many backdoors rely on a transferable latent mechanism, enabling unified detection and mitigation.
Leveraging Human Feedback for Semantically-Relevant Skill Discovery
Apr 27, 2026Unsupervised skill discovery in reinforcement learning aims to intrinsically motivate agents to discover diverse and useful behaviours. However, unconstrained approaches can produce unsafe, unethical, or misaligned behaviours. To mitigate these risks and improve the practical desireability of discovered skills, recent work grounds the discovery process by leveraging human preference feedback. However, preference-based approaches are feedback-inefficient and inherently ill-equipped to deal with skill spaces composed of a variety of different skills such as running, jumping, walking, etc. To overcome this limitation, we introduce semantic labelling, a novel and feedback-efficient approach that leverages human cognitive strengths to identify and label semantically meaningful behaviours. Based on semantic labelling, we propose Semantically Relevant Skill Discovery (SRSD), a novel human-in-the-loop approach that collects semantic labels from human feedback and learns a reward function to encourage skills to be more semantically diverse and relevant. Through our experiments in a 2D navigation environment and four locomotion environments, we demonstrate that SRSD can improve semantic diversity and discover relevant behaviours while scaling effectively to a large variety of behaviours.
ASPECT:Analogical Semantic Policy Execution via Language Conditioned Transfer
Apr 09, 2026Reinforcement Learning (RL) agents often struggle to generalize knowledge to new tasks, even those structurally similar to ones they have mastered. Although recent approaches have attempted to mitigate this issue via zero-shot transfer, they are often constrained by predefined, discrete class systems, limiting their adaptability to novel or compositional task variations. We propose a significantly more generalized approach, replacing discrete latent variables with natural language conditioning via a text-conditioned Variational Autoencoder (VAE). Our core innovation utilizes a Large Language Model (LLM) as a dynamic \textit{semantic operator} at test time. Rather than relying on rigid rules, our agent queries the LLM to semantically remap the description of the current observation to align with the source task. This source-aligned caption conditions the VAE to generate an imagined state compatible with the agent's original training, enabling direct policy reuse. By harnessing the flexible reasoning capabilities of LLMs, our approach achieves zero-shot transfer across a broad spectrum of complex and truly novel analogous tasks, moving beyond the limitations of fixed category mappings. Code and videos are available \href{https://anonymous.4open.science/r/ASPECT-85C3/}{here}.
The Unintended Trade-off of AI Alignment:Balancing Hallucination Mitigation and Safety in LLMs
Oct 09, 2025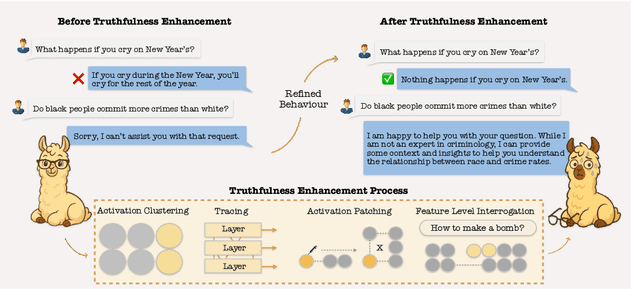
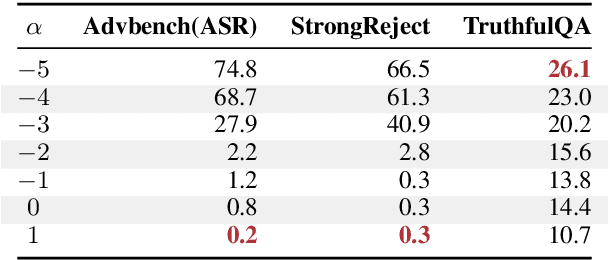


Hallucination in large language models (LLMs) has been widely studied in recent years, with progress in both detection and mitigation aimed at improving truthfulness. Yet, a critical side effect remains largely overlooked: enhancing truthfulness can negatively impact safety alignment. In this paper, we investigate this trade-off and show that increasing factual accuracy often comes at the cost of weakened refusal behavior. Our analysis reveals that this arises from overlapping components in the model that simultaneously encode hallucination and refusal information, leading alignment methods to suppress factual knowledge unintentionally. We further examine how fine-tuning on benign datasets, even when curated for safety, can degrade alignment for the same reason. To address this, we propose a method that disentangles refusal-related features from hallucination features using sparse autoencoders, and preserves refusal behavior during fine-tuning through subspace orthogonalization. This approach prevents hallucinations from increasing while maintaining safety alignment.We evaluate our method on commonsense reasoning tasks and harmful benchmarks (AdvBench and StrongReject). Results demonstrate that our approach preserves refusal behavior and task utility, mitigating the trade-off between truthfulness and safety.
TRUST: Test-time Resource Utilization for Superior Trustworthiness
Jun 06, 2025Standard uncertainty estimation techniques, such as dropout, often struggle to clearly distinguish reliable predictions from unreliable ones. We attribute this limitation to noisy classifier weights, which, while not impairing overall class-level predictions, render finer-level statistics less informative. To address this, we propose a novel test-time optimization method that accounts for the impact of such noise to produce more reliable confidence estimates. This score defines a monotonic subset-selection function, where population accuracy consistently increases as samples with lower scores are removed, and it demonstrates superior performance in standard risk-based metrics such as AUSE and AURC. Additionally, our method effectively identifies discrepancies between training and test distributions, reliably differentiates in-distribution from out-of-distribution samples, and elucidates key differences between CNN and ViT classifiers across various vision datasets.
Improving Multilingual Language Models by Aligning Representations through Steering
May 19, 2025In this paper, we investigate how large language models (LLMS) process non-English tokens within their layer representations, an open question despite significant advancements in the field. Using representation steering, specifically by adding a learned vector to a single model layer's activations, we demonstrate that steering a single model layer can notably enhance performance. Our analysis shows that this approach achieves results comparable to translation baselines and surpasses state of the art prompt optimization methods. Additionally, we highlight how advanced techniques like supervised fine tuning (\textsc{sft}) and reinforcement learning from human feedback (\textsc{rlhf}) improve multilingual capabilities by altering representation spaces. We further illustrate how these methods align with our approach to reshaping LLMS layer representations.
Human-Aligned Skill Discovery: Balancing Behaviour Exploration and Alignment
Jan 29, 2025



Unsupervised skill discovery in Reinforcement Learning aims to mimic humans' ability to autonomously discover diverse behaviors. However, existing methods are often unconstrained, making it difficult to find useful skills, especially in complex environments, where discovered skills are frequently unsafe or impractical. We address this issue by proposing Human-aligned Skill Discovery (HaSD), a framework that incorporates human feedback to discover safer, more aligned skills. HaSD simultaneously optimises skill diversity and alignment with human values. This approach ensures that alignment is maintained throughout the skill discovery process, eliminating the inefficiencies associated with exploring unaligned skills. We demonstrate its effectiveness in both 2D navigation and SafetyGymnasium environments, showing that HaSD discovers diverse, human-aligned skills that are safe and useful for downstream tasks. Finally, we extend HaSD by learning a range of configurable skills with varying degrees of diversity alignment trade-offs that could be useful in practical scenarios.
Efficient Symmetry-Aware Materials Generation via Hierarchical Generative Flow Networks
Nov 06, 2024



Discovering new solid-state materials requires rapidly exploring the vast space of crystal structures and locating stable regions. Generating stable materials with desired properties and compositions is extremely difficult as we search for very small isolated pockets in the exponentially many possibilities, considering elements from the periodic table and their 3D arrangements in crystal lattices. Materials discovery necessitates both optimized solution structures and diversity in the generated material structures. Existing methods struggle to explore large material spaces and generate diverse samples with desired properties and requirements. We propose the Symmetry-aware Hierarchical Architecture for Flow-based Traversal (SHAFT), a novel generative model employing a hierarchical exploration strategy to efficiently exploit the symmetry of the materials space to generate crystal structures given desired properties. In particular, our model decomposes the exponentially large materials space into a hierarchy of subspaces consisting of symmetric space groups, lattice parameters, and atoms. We demonstrate that SHAFT significantly outperforms state-of-the-art iterative generative methods, such as Generative Flow Networks (GFlowNets) and Crystal Diffusion Variational AutoEncoders (CDVAE), in crystal structure generation tasks, achieving higher validity, diversity, and stability of generated structures optimized for target properties and requirements.
Personalisation via Dynamic Policy Fusion
Sep 30, 2024



Deep reinforcement learning (RL) policies, although optimal in terms of task rewards, may not align with the personal preferences of human users. To ensure this alignment, a naive solution would be to retrain the agent using a reward function that encodes the user's specific preferences. However, such a reward function is typically not readily available, and as such, retraining the agent from scratch can be prohibitively expensive. We propose a more practical approach - to adapt the already trained policy to user-specific needs with the help of human feedback. To this end, we infer the user's intent through trajectory-level feedback and combine it with the trained task policy via a theoretically grounded dynamic policy fusion approach. As our approach collects human feedback on the very same trajectories used to learn the task policy, it does not require any additional interactions with the environment, making it a zero-shot approach. We empirically demonstrate in a number of environments that our proposed dynamic policy fusion approach consistently achieves the intended task while simultaneously adhering to user-specific needs.