 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTRUST: Test-time Resource Utilization for Superior Trustworthiness
Jun 06, 2025Standard uncertainty estimation techniques, such as dropout, often struggle to clearly distinguish reliable predictions from unreliable ones. We attribute this limitation to noisy classifier weights, which, while not impairing overall class-level predictions, render finer-level statistics less informative. To address this, we propose a novel test-time optimization method that accounts for the impact of such noise to produce more reliable confidence estimates. This score defines a monotonic subset-selection function, where population accuracy consistently increases as samples with lower scores are removed, and it demonstrates superior performance in standard risk-based metrics such as AUSE and AURC. Additionally, our method effectively identifies discrepancies between training and test distributions, reliably differentiates in-distribution from out-of-distribution samples, and elucidates key differences between CNN and ViT classifiers across various vision datasets.
Composite Concept Extraction through Backdooring
Jun 19, 2024
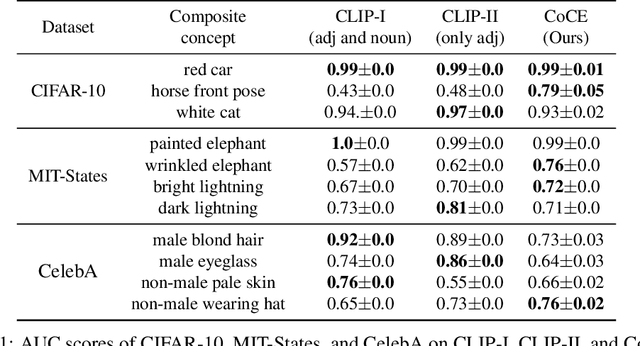

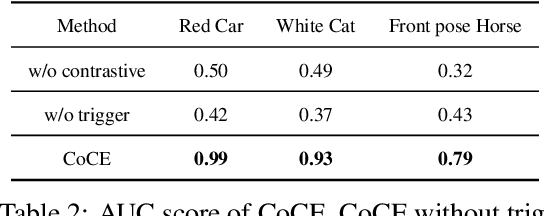
Learning composite concepts, such as \textquotedbl red car\textquotedbl , from individual examples -- like a white car representing the concept of \textquotedbl car\textquotedbl{} and a red strawberry representing the concept of \textquotedbl red\textquotedbl -- is inherently challenging. This paper introduces a novel method called Composite Concept Extractor (CoCE), which leverages techniques from traditional backdoor attacks to learn these composite concepts in a zero-shot setting, requiring only examples of individual concepts. By repurposing the trigger-based model backdooring mechanism, we create a strategic distortion in the manifold of the target object (e.g., \textquotedbl car\textquotedbl ) induced by example objects with the target property (e.g., \textquotedbl red\textquotedbl ) from objects \textquotedbl red strawberry\textquotedbl , ensuring the distortion selectively affects the target objects with the target property. Contrastive learning is then employed to further refine this distortion, and a method is formulated for detecting objects that are influenced by the distortion. Extensive experiments with in-depth analysis across different datasets demonstrate the utility and applicability of our proposed approach.
Revisiting the Dataset Bias Problem from a Statistical Perspective
Feb 05, 2024


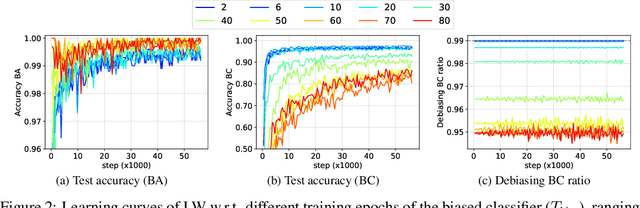
In this paper, we study the "dataset bias" problem from a statistical standpoint, and identify the main cause of the problem as the strong correlation between a class attribute u and a non-class attribute b in the input x, represented by p(u|b) differing significantly from p(u). Since p(u|b) appears as part of the sampling distributions in the standard maximum log-likelihood (MLL) objective, a model trained on a biased dataset via MLL inherently incorporates such correlation into its parameters, leading to poor generalization to unbiased test data. From this observation, we propose to mitigate dataset bias via either weighting the objective of each sample n by \frac{1}{p(u_{n}|b_{n})} or sampling that sample with a weight proportional to \frac{1}{p(u_{n}|b_{n})}. While both methods are statistically equivalent, the former proves more stable and effective in practice. Additionally, we establish a connection between our debiasing approach and causal reasoning, reinforcing our method's theoretical foundation. However, when the bias label is unavailable, computing p(u|b) exactly is difficult. To overcome this challenge, we propose to approximate \frac{1}{p(u|b)} using a biased classifier trained with "bias amplification" losses. Extensive experiments on various biased datasets demonstrate the superiority of our method over existing debiasing techniques in most settings, validating our theoretical analysis.
Momentum Adversarial Distillation: Handling Large Distribution Shifts in Data-Free Knowledge Distillation
Sep 21, 2022


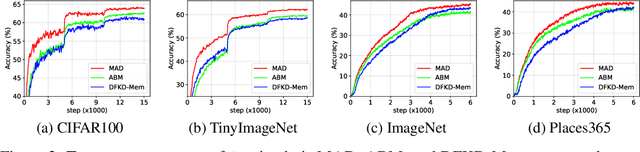
Data-free Knowledge Distillation (DFKD) has attracted attention recently thanks to its appealing capability of transferring knowledge from a teacher network to a student network without using training data. The main idea is to use a generator to synthesize data for training the student. As the generator gets updated, the distribution of synthetic data will change. Such distribution shift could be large if the generator and the student are trained adversarially, causing the student to forget the knowledge it acquired at previous steps. To alleviate this problem, we propose a simple yet effective method called Momentum Adversarial Distillation (MAD) which maintains an exponential moving average (EMA) copy of the generator and uses synthetic samples from both the generator and the EMA generator to train the student. Since the EMA generator can be considered as an ensemble of the generator's old versions and often undergoes a smaller change in updates compared to the generator, training on its synthetic samples can help the student recall the past knowledge and prevent the student from adapting too quickly to new updates of the generator. Our experiments on six benchmark datasets including big datasets like ImageNet and Places365 demonstrate the superior performance of MAD over competing methods for handling the large distribution shift problem. Our method also compares favorably to existing DFKD methods and even achieves state-of-the-art results in some cases.
Defense Against Multi-target Trojan Attacks
Jul 08, 2022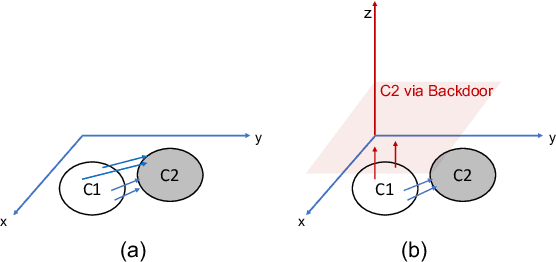
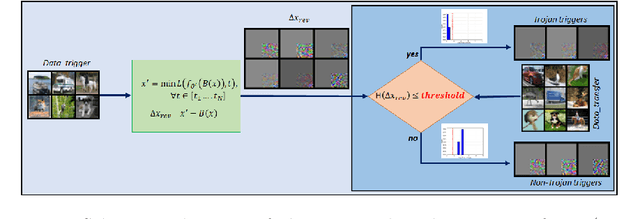

Adversarial attacks on deep learning-based models pose a significant threat to the current AI infrastructure. Among them, Trojan attacks are the hardest to defend against. In this paper, we first introduce a variation of the Badnet kind of attacks that introduces Trojan backdoors to multiple target classes and allows triggers to be placed anywhere in the image. The former makes it more potent and the latter makes it extremely easy to carry out the attack in the physical space. The state-of-the-art Trojan detection methods fail with this threat model. To defend against this attack, we first introduce a trigger reverse-engineering mechanism that uses multiple images to recover a variety of potential triggers. We then propose a detection mechanism by measuring the transferability of such recovered triggers. A Trojan trigger will have very high transferability i.e. they make other images also go to the same class. We study many practical advantages of our attack method and then demonstrate the detection performance using a variety of image datasets. The experimental results show the superior detection performance of our method over the state-of-the-arts.
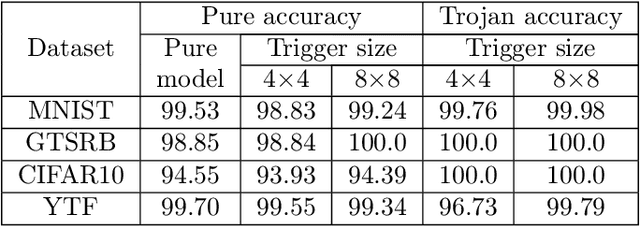
Towards Effective and Robust Neural Trojan Defenses via Input Filtering
Mar 08, 2022


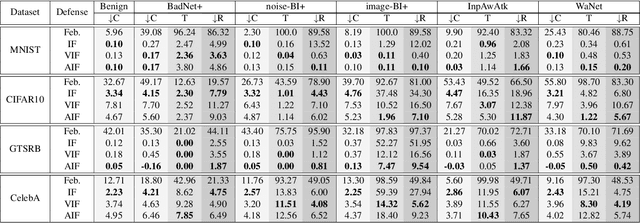
Trojan attacks on deep neural networks are both dangerous and surreptitious. Over the past few years, Trojan attacks have advanced from using only a single input-agnostic trigger and targeting only one class to using multiple, input-specific triggers and targeting multiple classes. However, Trojan defenses have not caught up with this development. Most defense methods still make out-of-date assumptions about Trojan triggers and target classes, thus, can be easily circumvented by modern Trojan attacks. To deal with this problem, we propose two novel "filtering" defenses called Variational Input Filtering (VIF) and Adversarial Input Filtering (AIF) which leverage lossy data compression and adversarial learning respectively to effectively purify all potential Trojan triggers in the input at run time without making assumptions about the number of triggers/target classes or the input dependence property of triggers. In addition, we introduce a new defense mechanism called "Filtering-then-Contrasting" (FtC) which helps avoid the drop in classification accuracy on clean data caused by "filtering", and combine it with VIF/AIF to derive new defenses of this kind. Extensive experimental results and ablation studies show that our proposed defenses significantly outperform well-known baseline defenses in mitigating five advanced Trojan attacks including two recent state-of-the-art while being quite robust to small amounts of training data and large-norm triggers.
Semantic Host-free Trojan Attack
Oct 26, 2021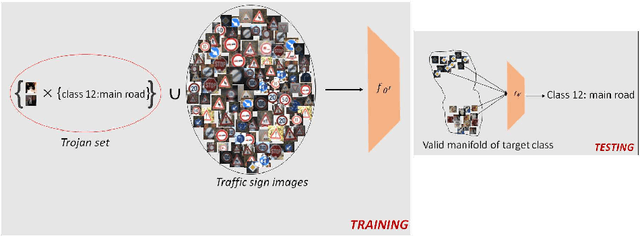



In this paper, we propose a novel host-free Trojan attack with triggers that are fixed in the semantic space but not necessarily in the pixel space. In contrast to existing Trojan attacks which use clean input images as hosts to carry small, meaningless trigger patterns, our attack considers triggers as full-sized images belonging to a semantically meaningful object class. Since in our attack, the backdoored classifier is encouraged to memorize the abstract semantics of the trigger images than any specific fixed pattern, it can be later triggered by semantically similar but different looking images. This makes our attack more practical to be applied in the real-world and harder to defend against. Extensive experimental results demonstrate that with only a small number of Trojan patterns for training, our attack can generalize well to new patterns of the same Trojan class and can bypass state-of-the-art defense methods.
Scalable Backdoor Detection in Neural Networks
Jun 10, 2020
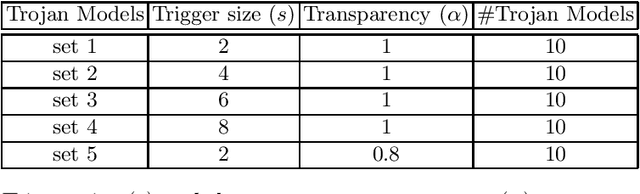


Recently, it has been shown that deep learning models are vulnerable to Trojan attacks, where an attacker can install a backdoor during training time to make the resultant model misidentify samples contaminated with a small trigger patch. Current backdoor detection methods fail to achieve good detection performance and are computationally expensive. In this paper, we propose a novel trigger reverse-engineering based approach whose computational complexity does not scale with the number of labels, and is based on a measure that is both interpretable and universal across different network and patch types. In experiments, we observe that our method achieves a perfect score in separating Trojaned models from pure models, which is an improvement over the current state-of-the art method.