 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRevisiting the Dataset Bias Problem from a Statistical Perspective
Paper and Code



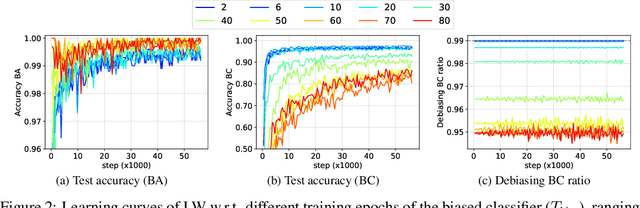
In this paper, we study the "dataset bias" problem from a statistical standpoint, and identify the main cause of the problem as the strong correlation between a class attribute u and a non-class attribute b in the input x, represented by p(u|b) differing significantly from p(u). Since p(u|b) appears as part of the sampling distributions in the standard maximum log-likelihood (MLL) objective, a model trained on a biased dataset via MLL inherently incorporates such correlation into its parameters, leading to poor generalization to unbiased test data. From this observation, we propose to mitigate dataset bias via either weighting the objective of each sample n by \frac{1}{p(u_{n}|b_{n})} or sampling that sample with a weight proportional to \frac{1}{p(u_{n}|b_{n})}. While both methods are statistically equivalent, the former proves more stable and effective in practice. Additionally, we establish a connection between our debiasing approach and causal reasoning, reinforcing our method's theoretical foundation. However, when the bias label is unavailable, computing p(u|b) exactly is difficult. To overcome this challenge, we propose to approximate \frac{1}{p(u|b)} using a biased classifier trained with "bias amplification" losses. Extensive experiments on various biased datasets demonstrate the superiority of our method over existing debiasing techniques in most settings, validating our theoretical analysis.