 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDo Domain-specific Experts exist in MoE-based LLMs?
Apr 07, 2026In the era of Large Language Models (LLMs), the Mixture of Experts (MoE) architecture has emerged as an effective approach for training extremely large models with improved computational efficiency. This success builds upon extensive prior research aimed at enhancing expert specialization in MoE-based LLMs. However, the nature of such specializations and how they can be systematically interpreted remain open research challenges. In this work, we investigate this gap by posing a fundamental question: \textit{Do domain-specific experts exist in MoE-based LLMs?} To answer the question, we evaluate ten advanced MoE-based LLMs ranging from 3.8B to 120B parameters and provide empirical evidence for the existence of domain-specific experts. Building on this finding, we propose \textbf{Domain Steering Mixture of Experts (DSMoE)}, a training-free framework that introduces zero additional inference cost and outperforms both well-trained MoE-based LLMs and strong baselines, including Supervised Fine-Tuning (SFT). Experiments on four advanced open-source MoE-based LLMs across both target and non-target domains demonstrate that our method achieves strong performance and robust generalization without increasing inference cost or requiring additional retraining. Our implementation is publicly available at https://github.com/giangdip2410/Domain-specific-Experts.
Hear Both Sides: Efficient Multi-Agent Debate via Diversity-Aware Message Retention
Mar 21, 2026Multi-Agent Debate has emerged as a promising framework for improving the reasoning quality of large language models through iterative inter-agent communication. However, broadcasting all agent messages at every round introduces noise and redundancy that can degrade debate quality and waste computational resources. Current approaches rely on uncertainty estimation to filter low-confidence responses before broadcasting, but this approach is unreliable due to miscalibrated confidence scores and sensitivity to threshold selection. To address this, we propose Diversity-Aware Retention (DAR), a lightweight debate framework that, at each debate round, selects the subset of agent responses that maximally disagree with each other and with the majority vote before broadcasting. Through an explicit index-based retention mechanism, DAR preserves the original messages without modification, ensuring that retained disagreements remain authentic. Experiments on diverse reasoning and question answering benchmarks demonstrate that our selective message propagation consistently improves debate performance, particularly as the number of agents scales, where noise accumulation is most severe. Our results highlight that what agents hear is as important as what agents say in multi-agent reasoning systems.
Spectral Text Fusion: A Frequency-Aware Approach to Multimodal Time-Series Forecasting
Feb 03, 2026Multimodal time series forecasting is crucial in real-world applications, where decisions depend on both numerical data and contextual signals. The core challenge is to effectively combine temporal numerical patterns with the context embedded in other modalities, such as text. While most existing methods align textual features with time-series patterns one step at a time, they neglect the multiscale temporal influences of contextual information such as time-series cycles and dynamic shifts. This mismatch between local alignment and global textual context can be addressed by spectral decomposition, which separates time series into frequency components capturing both short-term changes and long-term trends. In this paper, we propose SpecTF, a simple yet effective framework that integrates the effect of textual data on time series in the frequency domain. Our method extracts textual embeddings, projects them into the frequency domain, and fuses them with the time series' spectral components using a lightweight cross-attention mechanism. This adaptively reweights frequency bands based on textual relevance before mapping the results back to the temporal domain for predictions. Experimental results demonstrate that SpecTF significantly outperforms state-of-the-art models across diverse multi-modal time series datasets while utilizing considerably fewer parameters. Code is available at https://github.com/hiepnh137/SpecTF.
Federated Domain Generalization with Latent Space Inversion
Dec 11, 2025Federated domain generalization (FedDG) addresses distribution shifts among clients in a federated learning framework. FedDG methods aggregate the parameters of locally trained client models to form a global model that generalizes to unseen clients while preserving data privacy. While improving the generalization capability of the global model, many existing approaches in FedDG jeopardize privacy by sharing statistics of client data between themselves. Our solution addresses this problem by contributing new ways to perform local client training and model aggregation. To improve local client training, we enforce (domain) invariance across local models with the help of a novel technique, \textbf{latent space inversion}, which enables better client privacy. When clients are not \emph{i.i.d}, aggregating their local models may discard certain local adaptations. To overcome this, we propose an \textbf{important weight} aggregation strategy to prioritize parameters that significantly influence predictions of local models during aggregation. Our extensive experiments show that our approach achieves superior results over state-of-the-art methods with less communication overhead.
Empowering Multi-Turn Tool-Integrated Reasoning with Group Turn Policy Optimization
Nov 18, 2025
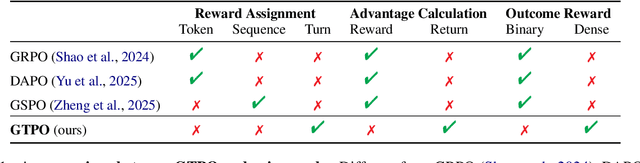
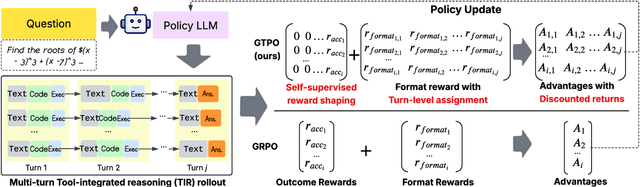
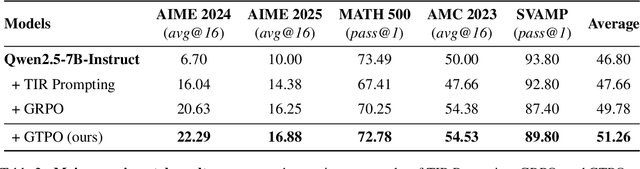
Training Large Language Models (LLMs) for multi-turn Tool-Integrated Reasoning (TIR) - where models iteratively reason, generate code, and verify through execution - remains challenging for existing reinforcement learning (RL) approaches. Current RL methods, exemplified by Group Relative Policy Optimization (GRPO), suffer from coarse-grained, trajectory-level rewards that provide insufficient learning signals for complex multi-turn interactions, leading to training stagnation. To address this issue, we propose Group Turn Policy Optimization (GTPO), a novel RL algorithm specifically designed for training LLMs on multi-turn TIR tasks. GTPO introduces three key innovations: (1) turn-level reward assignment that provides fine-grained feedback for individual turns, (2) return-based advantage estimation where normalized discounted returns are calculated as advantages, and (3) self-supervised reward shaping that exploits self-supervision signals from generated code to densify sparse binary outcome-based rewards. Our comprehensive evaluation demonstrates that GTPO outperforms GRPO by 3.0% on average across diverse reasoning benchmarks, establishing its effectiveness for advancing complex mathematical reasoning in the real world.
Uncertainty-Guided Checkpoint Selection for Reinforcement Finetuning of Large Language Models
Nov 13, 2025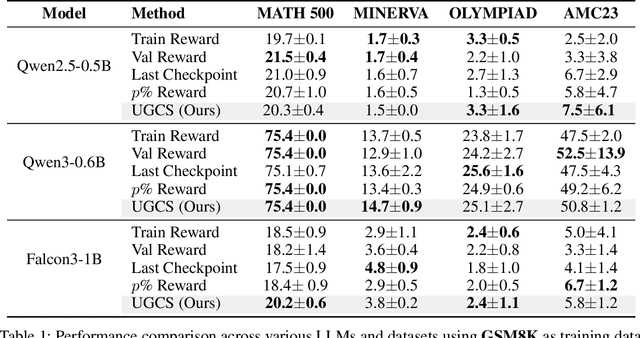
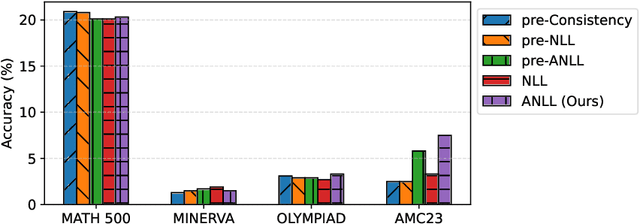
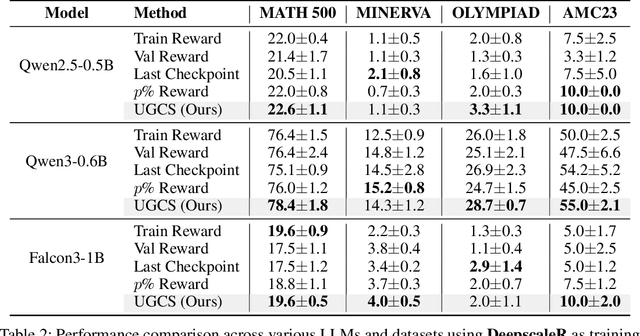
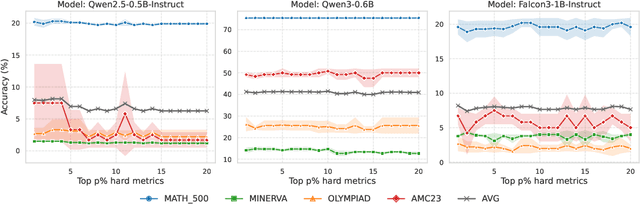
Reinforcement learning (RL) finetuning is crucial to aligning large language models (LLMs), but the process is notoriously unstable and exhibits high variance across model checkpoints. In practice, selecting the best checkpoint is challenging: evaluating checkpoints on the validation set during training is computationally expensive and requires a good validation set, while relying on the final checkpoint provides no guarantee of good performance. We introduce an uncertainty-guided approach for checkpoint selection (UGCS) that avoids these pitfalls. Our method identifies hard question-answer pairs using per-sample uncertainty and ranks checkpoints by how well they handle these challenging cases. By averaging the rewards of the top-uncertain samples over a short training window, our method produces a stable and discriminative signal without additional forward passes or significant computation overhead. Experiments across three datasets and three LLMs demonstrate that it consistently identifies checkpoints with stronger generalization, outperforming traditional strategies such as relying on training or validation performance. These results highlight that models solving their hardest tasks with low uncertainty are the most reliable overall.
Probabilities Are All You Need: A Probability-Only Approach to Uncertainty Estimation in Large Language Models
Nov 10, 2025



Large Language Models (LLMs) exhibit strong performance across various natural language processing (NLP) tasks but remain vulnerable to hallucinations, generating factually incorrect or misleading outputs. Uncertainty estimation, often using predictive entropy estimation, is key to addressing this issue. However, existing methods often require multiple samples or extra computation to assess semantic entropy. This paper proposes an efficient, training-free uncertainty estimation method that approximates predictive entropy using the responses' top-$K$ probabilities. Moreover, we employ an adaptive mechanism to determine $K$ to enhance flexibility and filter out low-confidence probabilities. Experimental results on three free-form question-answering datasets across several LLMs demonstrate that our method outperforms expensive state-of-the-art baselines, contributing to the broader goal of enhancing LLM trustworthiness.
GRAD: Graph-Retrieved Adaptive Decoding for Hallucination Mitigation
Nov 05, 2025Hallucination mitigation remains a persistent challenge for large language models (LLMs), even as model scales grow. Existing approaches often rely on external knowledge sources, such as structured databases or knowledge graphs, accessed through prompting or retrieval. However, prompt-based grounding is fragile and domain-sensitive, while symbolic knowledge integration incurs heavy retrieval and formatting costs. Motivated by knowledge graphs, we introduce Graph-Retrieved Adaptive Decoding (GRAD), a decoding-time method that grounds generation in corpus-derived evidence without retraining. GRAD constructs a sparse token transition graph by accumulating next-token logits across a small retrieved corpus in a single forward pass. During decoding, graph-retrieved logits are max-normalized and adaptively fused with model logits to favor high-evidence continuations while preserving fluency. Across three models and a range of question-answering benchmarks spanning intrinsic, extrinsic hallucination, and factuality tasks, GRAD consistently surpasses baselines, achieving up to 9.7$\%$ higher intrinsic accuracy, 8.6$\%$ lower hallucination rates, and 6.9$\%$ greater correctness compared to greedy decoding, while attaining the highest truth--informativeness product score among all methods. GRAD offers a lightweight, plug-and-play alternative to contrastive decoding and knowledge graph augmentation, demonstrating that statistical evidence from corpus-level token transitions can effectively steer generation toward more truthful and verifiable outputs.
SPaRFT: Self-Paced Reinforcement Fine-Tuning for Large Language Models
Aug 07, 2025Large language models (LLMs) have shown strong reasoning capabilities when fine-tuned with reinforcement learning (RL). However, such methods require extensive data and compute, making them impractical for smaller models. Current approaches to curriculum learning or data selection are largely heuristic-driven or demand extensive computational resources, limiting their scalability and generalizability. We propose \textbf{SPaRFT}, a self-paced learning framework that enables efficient learning based on the capability of the model being trained through optimizing which data to use and when. First, we apply \emph{cluster-based data reduction} to partition training data by semantics and difficulty, extracting a compact yet diverse subset that reduces redundancy. Then, a \emph{multi-armed bandit} treats data clusters as arms, optimized to allocate training samples based on model current performance. Experiments across multiple reasoning benchmarks show that SPaRFT achieves comparable or better accuracy than state-of-the-art baselines while using up to \(100\times\) fewer samples. Ablation studies and analyses further highlight the importance of both data clustering and adaptive selection. Our results demonstrate that carefully curated, performance-driven training curricula can unlock strong reasoning abilities in LLMs with minimal resources.
DmC: Nearest Neighbor Guidance Diffusion Model for Offline Cross-domain Reinforcement Learning
Jul 28, 2025Cross-domain offline reinforcement learning (RL) seeks to enhance sample efficiency in offline RL by utilizing additional offline source datasets. A key challenge is to identify and utilize source samples that are most relevant to the target domain. Existing approaches address this challenge by measuring domain gaps through domain classifiers, target transition dynamics modeling, or mutual information estimation using contrastive loss. However, these methods often require large target datasets, which is impractical in many real-world scenarios. In this work, we address cross-domain offline RL under a limited target data setting, identifying two primary challenges: (1) Dataset imbalance, which is caused by large source and small target datasets and leads to overfitting in neural network-based domain gap estimators, resulting in uninformative measurements; and (2) Partial domain overlap, where only a subset of the source data is closely aligned with the target domain. To overcome these issues, we propose DmC, a novel framework for cross-domain offline RL with limited target samples. Specifically, DmC utilizes $k$-nearest neighbor ($k$-NN) based estimation to measure domain proximity without neural network training, effectively mitigating overfitting. Then, by utilizing this domain proximity, we introduce a nearest-neighbor-guided diffusion model to generate additional source samples that are better aligned with the target domain, thus enhancing policy learning with more effective source samples. Through theoretical analysis and extensive experiments in diverse MuJoCo environments, we demonstrate that DmC significantly outperforms state-of-the-art cross-domain offline RL methods, achieving substantial performance gains.