 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUncertainty-Guided Checkpoint Selection for Reinforcement Finetuning of Large Language Models
Nov 13, 2025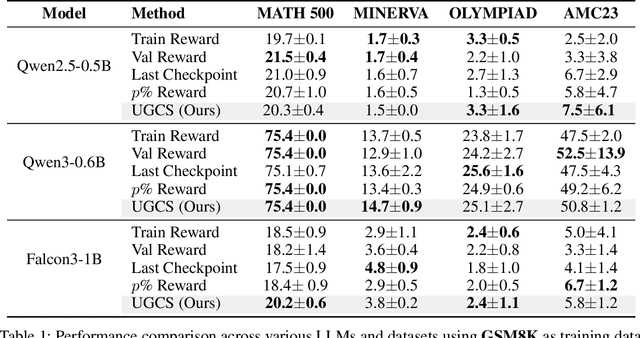
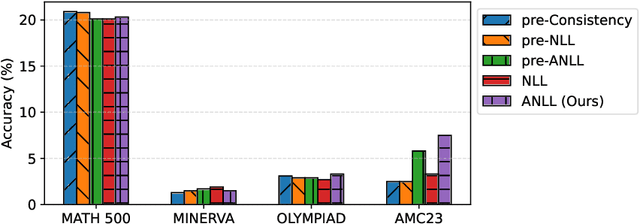
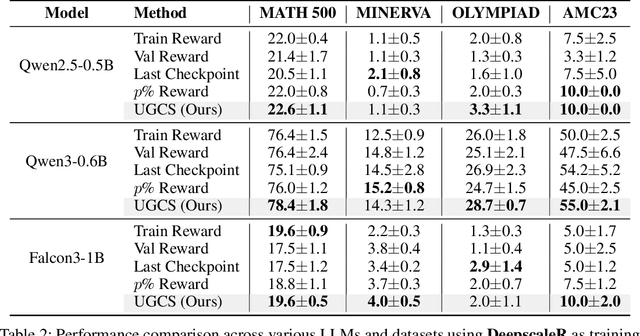
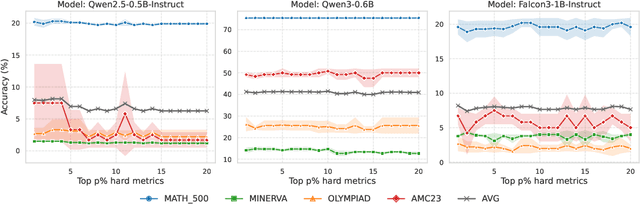
Reinforcement learning (RL) finetuning is crucial to aligning large language models (LLMs), but the process is notoriously unstable and exhibits high variance across model checkpoints. In practice, selecting the best checkpoint is challenging: evaluating checkpoints on the validation set during training is computationally expensive and requires a good validation set, while relying on the final checkpoint provides no guarantee of good performance. We introduce an uncertainty-guided approach for checkpoint selection (UGCS) that avoids these pitfalls. Our method identifies hard question-answer pairs using per-sample uncertainty and ranks checkpoints by how well they handle these challenging cases. By averaging the rewards of the top-uncertain samples over a short training window, our method produces a stable and discriminative signal without additional forward passes or significant computation overhead. Experiments across three datasets and three LLMs demonstrate that it consistently identifies checkpoints with stronger generalization, outperforming traditional strategies such as relying on training or validation performance. These results highlight that models solving their hardest tasks with low uncertainty are the most reliable overall.
GRAD: Graph-Retrieved Adaptive Decoding for Hallucination Mitigation
Nov 05, 2025Hallucination mitigation remains a persistent challenge for large language models (LLMs), even as model scales grow. Existing approaches often rely on external knowledge sources, such as structured databases or knowledge graphs, accessed through prompting or retrieval. However, prompt-based grounding is fragile and domain-sensitive, while symbolic knowledge integration incurs heavy retrieval and formatting costs. Motivated by knowledge graphs, we introduce Graph-Retrieved Adaptive Decoding (GRAD), a decoding-time method that grounds generation in corpus-derived evidence without retraining. GRAD constructs a sparse token transition graph by accumulating next-token logits across a small retrieved corpus in a single forward pass. During decoding, graph-retrieved logits are max-normalized and adaptively fused with model logits to favor high-evidence continuations while preserving fluency. Across three models and a range of question-answering benchmarks spanning intrinsic, extrinsic hallucination, and factuality tasks, GRAD consistently surpasses baselines, achieving up to 9.7$\%$ higher intrinsic accuracy, 8.6$\%$ lower hallucination rates, and 6.9$\%$ greater correctness compared to greedy decoding, while attaining the highest truth--informativeness product score among all methods. GRAD offers a lightweight, plug-and-play alternative to contrastive decoding and knowledge graph augmentation, demonstrating that statistical evidence from corpus-level token transitions can effectively steer generation toward more truthful and verifiable outputs.
SPaRFT: Self-Paced Reinforcement Fine-Tuning for Large Language Models
Aug 07, 2025Large language models (LLMs) have shown strong reasoning capabilities when fine-tuned with reinforcement learning (RL). However, such methods require extensive data and compute, making them impractical for smaller models. Current approaches to curriculum learning or data selection are largely heuristic-driven or demand extensive computational resources, limiting their scalability and generalizability. We propose \textbf{SPaRFT}, a self-paced learning framework that enables efficient learning based on the capability of the model being trained through optimizing which data to use and when. First, we apply \emph{cluster-based data reduction} to partition training data by semantics and difficulty, extracting a compact yet diverse subset that reduces redundancy. Then, a \emph{multi-armed bandit} treats data clusters as arms, optimized to allocate training samples based on model current performance. Experiments across multiple reasoning benchmarks show that SPaRFT achieves comparable or better accuracy than state-of-the-art baselines while using up to \(100\times\) fewer samples. Ablation studies and analyses further highlight the importance of both data clustering and adaptive selection. Our results demonstrate that carefully curated, performance-driven training curricula can unlock strong reasoning abilities in LLMs with minimal resources.
Reasoning Under 1 Billion: Memory-Augmented Reinforcement Learning for Large Language Models
Apr 03, 2025Recent advances in fine-tuning large language models (LLMs) with reinforcement learning (RL) have shown promising improvements in complex reasoning tasks, particularly when paired with chain-of-thought (CoT) prompting. However, these successes have been largely demonstrated on large-scale models with billions of parameters, where a strong pretraining foundation ensures effective initial exploration. In contrast, RL remains challenging for tiny LLMs with 1 billion parameters or fewer because they lack the necessary pretraining strength to explore effectively, often leading to suboptimal reasoning patterns. This work introduces a novel intrinsic motivation approach that leverages episodic memory to address this challenge, improving tiny LLMs in CoT reasoning tasks. Inspired by human memory-driven learning, our method leverages successful reasoning patterns stored in memory while allowing for controlled exploration to generate novel responses. Intrinsic rewards are computed efficiently using a kNN-based episodic memory, allowing the model to discover new reasoning strategies while quickly adapting to effective past solutions. Experiments on fine-tuning GSM8K and AI-MO datasets demonstrate that our approach significantly enhances smaller LLMs' sample efficiency and generalization capability, making RL-based reasoning improvements more accessible in low-resource settings.
Large Language Models Prompting With Episodic Memory
Aug 14, 2024Prompt optimization is essential for enhancing the performance of Large Language Models (LLMs) in a range of Natural Language Processing (NLP) tasks, particularly in scenarios of few-shot learning where training examples are incorporated directly into the prompt. Despite the growing interest in optimizing prompts with few-shot examples, existing methods for prompt optimization are often resource-intensive or perform inadequately. In this work, we propose PrOmpting with Episodic Memory (POEM), a novel prompt optimization technique that is simple, efficient, and demonstrates strong generalization capabilities. We approach prompt optimization as a Reinforcement Learning (RL) challenge, using episodic memory to archive combinations of input data, permutations of few-shot examples, and the rewards observed during training. In the testing phase, we optimize the sequence of examples for each test query by selecting the sequence that yields the highest total rewards from the top-k most similar training examples in the episodic memory. Our results show that POEM outperforms recent techniques like TEMPERA and RLPrompt by over 5.3% in various text classification tasks. Furthermore, our approach adapts well to broader language understanding tasks, consistently outperforming conventional heuristic methods for ordering examples.