 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContinual Fine-Tuning of Large Language Models via Program Memory
May 13, 2026Parameter-Efficient Fine-Tuning (PEFT), particularly Low-Rank Adaptation (LoRA), has become a standard approach for adapting Large Language Models (LLMs) under limited compute. However, in continual settings where models are updated sequentially with small datasets, conventional LoRA updates struggle to balance rapid adaptation and knowledge retention. Existing methods typically treat the low-rank space as a homogeneous update region, lacking mechanisms to regulate how short-term updates are consolidated over time. We propose a continual LoRA framework with \textbf{Pro}gram memory, inspired by \textbf{C}omplementary \textbf{L}earning Systems in neuroscience. Our approach, dubbed \textbf{ProCL}, organizes LoRA adapters into structured program memory slots that are dynamically retrieved through input-conditioned attention. This enables rapid and localized adaptation, encouraging similar inputs to reuse shared adapter regions while reserving unused capacity for future data. The slots are then combined with the underlying adapter, which maintains a distributed representation that gradually accumulates knowledge across tasks to balance plasticity and stability. Our method operates entirely within the LoRA parameterization and incurs no additional inference cost. Experiments on diverse benchmarks demonstrate improved retention and reduced catastrophic forgetting over other continual LoRA strategies.
ChargeFlow: Flow-Matching Refinement of Charge-Conditioned Electron Densities
Mar 25, 2026Accurate charge densities are central to electronic-structure theory, but computing charge-state-dependent densities with density functional theory remains too expensive for large-scale screening and defect workflows. We present ChargeFlow, a flow-matching refinement model that transforms a charge-conditioned superposition of atomic densities into the corresponding DFT electron density on the native periodic real-space grid using a 3D U-Net velocity field. Trained on 9,502 charged Materials Project-derived calculations and evaluated on an external 1,671-structure benchmark spanning perovskites, charged defects, diamond defects, metal-organic frameworks, and organic crystals, ChargeFlow is not uniformly best on every in-distribution class but is strongest on problems dominated by nonlocal charge redistribution and charge-state extrapolation, improving deformation-density error from 3.62% to 3.21% and charge- response cosine similarity from 0.571 to 0.655 relative to a ResNet baseline. The predicted densities remain chemically useful under downstream analysis, yielding successful Bader partitioning on all 1,671 benchmark structures and high-fidelity electrostatic potentials, which positions flow matching as a practical density-refinement strategy for charged materials.
Hear Both Sides: Efficient Multi-Agent Debate via Diversity-Aware Message Retention
Mar 21, 2026Multi-Agent Debate has emerged as a promising framework for improving the reasoning quality of large language models through iterative inter-agent communication. However, broadcasting all agent messages at every round introduces noise and redundancy that can degrade debate quality and waste computational resources. Current approaches rely on uncertainty estimation to filter low-confidence responses before broadcasting, but this approach is unreliable due to miscalibrated confidence scores and sensitivity to threshold selection. To address this, we propose Diversity-Aware Retention (DAR), a lightweight debate framework that, at each debate round, selects the subset of agent responses that maximally disagree with each other and with the majority vote before broadcasting. Through an explicit index-based retention mechanism, DAR preserves the original messages without modification, ensuring that retained disagreements remain authentic. Experiments on diverse reasoning and question answering benchmarks demonstrate that our selective message propagation consistently improves debate performance, particularly as the number of agents scales, where noise accumulation is most severe. Our results highlight that what agents hear is as important as what agents say in multi-agent reasoning systems.
Adaptive Acquisition Selection for Bayesian Optimization with Large Language Models
Feb 08, 2026Bayesian Optimization critically depends on the choice of acquisition function, but no single strategy is universally optimal; the best choice is non-stationary and problem-dependent. Existing adaptive portfolio methods often base their decisions on past function values while ignoring richer information like remaining budget or surrogate model characteristics. To address this, we introduce LMABO, a novel framework that casts a pre-trained Large Language Model (LLM) as a zero-shot, online strategist for the BO process. At each iteration, LMABO uses a structured state representation to prompt the LLM to select the most suitable acquisition function from a diverse portfolio. In an evaluation across 50 benchmark problems, LMABO demonstrates a significant performance improvement over strong static, adaptive portfolio, and other LLM-based baselines. We show that the LLM's behavior is a comprehensive strategy that adapts to real-time progress, proving its advantage stems from its ability to process and synthesize the complete optimization state into an effective, adaptive policy.
Score-based Integrated Gradient for Root Cause Explanations of Outliers
Jan 29, 2026Identifying the root causes of outliers is a fundamental problem in causal inference and anomaly detection. Traditional approaches based on heuristics or counterfactual reasoning often struggle under uncertainty and high-dimensional dependencies. We introduce SIREN, a novel and scalable method that attributes the root causes of outliers by estimating the score functions of the data likelihood. Attribution is computed via integrated gradients that accumulate score contributions along paths from the outlier toward the normal data distribution. Our method satisfies three of the four classic Shapley value axioms - dummy, efficiency, and linearity - as well as an asymmetry axiom derived from the underlying causal structure. Unlike prior work, SIREN operates directly on the score function, enabling tractable and uncertainty-aware root cause attribution in nonlinear, high-dimensional, and heteroscedastic causal models. Extensive experiments on synthetic random graphs and real-world cloud service and supply chain datasets show that SIREN outperforms state-of-the-art baselines in both attribution accuracy and computational efficiency.
Federated Domain Generalization with Latent Space Inversion
Dec 11, 2025Federated domain generalization (FedDG) addresses distribution shifts among clients in a federated learning framework. FedDG methods aggregate the parameters of locally trained client models to form a global model that generalizes to unseen clients while preserving data privacy. While improving the generalization capability of the global model, many existing approaches in FedDG jeopardize privacy by sharing statistics of client data between themselves. Our solution addresses this problem by contributing new ways to perform local client training and model aggregation. To improve local client training, we enforce (domain) invariance across local models with the help of a novel technique, \textbf{latent space inversion}, which enables better client privacy. When clients are not \emph{i.i.d}, aggregating their local models may discard certain local adaptations. To overcome this, we propose an \textbf{important weight} aggregation strategy to prioritize parameters that significantly influence predictions of local models during aggregation. Our extensive experiments show that our approach achieves superior results over state-of-the-art methods with less communication overhead.
Uncertainty-Guided Checkpoint Selection for Reinforcement Finetuning of Large Language Models
Nov 13, 2025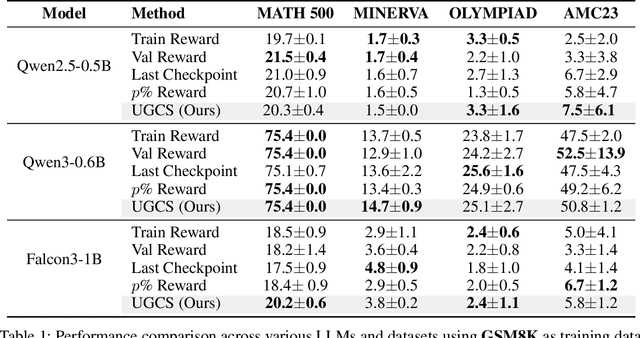
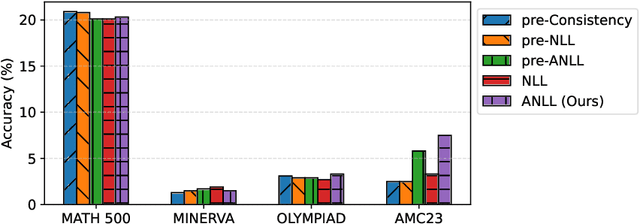
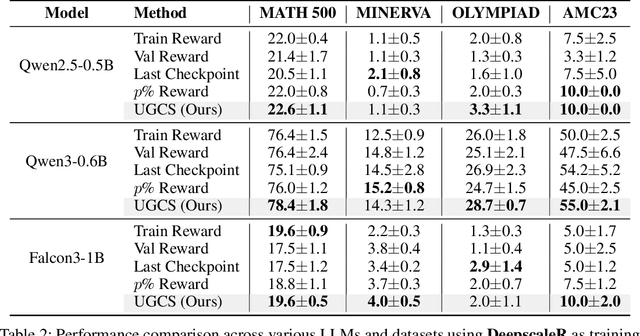
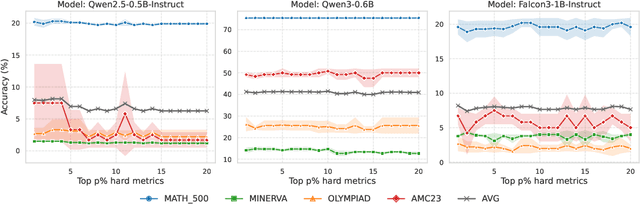
Reinforcement learning (RL) finetuning is crucial to aligning large language models (LLMs), but the process is notoriously unstable and exhibits high variance across model checkpoints. In practice, selecting the best checkpoint is challenging: evaluating checkpoints on the validation set during training is computationally expensive and requires a good validation set, while relying on the final checkpoint provides no guarantee of good performance. We introduce an uncertainty-guided approach for checkpoint selection (UGCS) that avoids these pitfalls. Our method identifies hard question-answer pairs using per-sample uncertainty and ranks checkpoints by how well they handle these challenging cases. By averaging the rewards of the top-uncertain samples over a short training window, our method produces a stable and discriminative signal without additional forward passes or significant computation overhead. Experiments across three datasets and three LLMs demonstrate that it consistently identifies checkpoints with stronger generalization, outperforming traditional strategies such as relying on training or validation performance. These results highlight that models solving their hardest tasks with low uncertainty are the most reliable overall.
SPaRFT: Self-Paced Reinforcement Fine-Tuning for Large Language Models
Aug 07, 2025Large language models (LLMs) have shown strong reasoning capabilities when fine-tuned with reinforcement learning (RL). However, such methods require extensive data and compute, making them impractical for smaller models. Current approaches to curriculum learning or data selection are largely heuristic-driven or demand extensive computational resources, limiting their scalability and generalizability. We propose \textbf{SPaRFT}, a self-paced learning framework that enables efficient learning based on the capability of the model being trained through optimizing which data to use and when. First, we apply \emph{cluster-based data reduction} to partition training data by semantics and difficulty, extracting a compact yet diverse subset that reduces redundancy. Then, a \emph{multi-armed bandit} treats data clusters as arms, optimized to allocate training samples based on model current performance. Experiments across multiple reasoning benchmarks show that SPaRFT achieves comparable or better accuracy than state-of-the-art baselines while using up to \(100\times\) fewer samples. Ablation studies and analyses further highlight the importance of both data clustering and adaptive selection. Our results demonstrate that carefully curated, performance-driven training curricula can unlock strong reasoning abilities in LLMs with minimal resources.
Reasoning Under 1 Billion: Memory-Augmented Reinforcement Learning for Large Language Models
Apr 03, 2025Recent advances in fine-tuning large language models (LLMs) with reinforcement learning (RL) have shown promising improvements in complex reasoning tasks, particularly when paired with chain-of-thought (CoT) prompting. However, these successes have been largely demonstrated on large-scale models with billions of parameters, where a strong pretraining foundation ensures effective initial exploration. In contrast, RL remains challenging for tiny LLMs with 1 billion parameters or fewer because they lack the necessary pretraining strength to explore effectively, often leading to suboptimal reasoning patterns. This work introduces a novel intrinsic motivation approach that leverages episodic memory to address this challenge, improving tiny LLMs in CoT reasoning tasks. Inspired by human memory-driven learning, our method leverages successful reasoning patterns stored in memory while allowing for controlled exploration to generate novel responses. Intrinsic rewards are computed efficiently using a kNN-based episodic memory, allowing the model to discover new reasoning strategies while quickly adapting to effective past solutions. Experiments on fine-tuning GSM8K and AI-MO datasets demonstrate that our approach significantly enhances smaller LLMs' sample efficiency and generalization capability, making RL-based reasoning improvements more accessible in low-resource settings.
Finding the Trigger: Causal Abductive Reasoning on Video Events
Jan 16, 2025This paper introduces a new problem, Causal Abductive Reasoning on Video Events (CARVE), which involves identifying causal relationships between events in a video and generating hypotheses about causal chains that account for the occurrence of a target event. To facilitate research in this direction, we create two new benchmark datasets with both synthetic and realistic videos, accompanied by trigger-target labels generated through a novel counterfactual synthesis approach. To explore the challenge of solving CARVE, we present a Causal Event Relation Network (CERN) that examines the relationships between video events in temporal and semantic spaces to efficiently determine the root-cause trigger events. Through extensive experiments, we demonstrate the critical roles of event relational representation learning and interaction modeling in solving video causal reasoning challenges. The introduction of the CARVE task, along with the accompanying datasets and the CERN framework, will advance future research on video causal reasoning and significantly facilitate various applications, including video surveillance, root-cause analysis and movie content management.