 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFinding the Trigger: Causal Abductive Reasoning on Video Events
Jan 16, 2025This paper introduces a new problem, Causal Abductive Reasoning on Video Events (CARVE), which involves identifying causal relationships between events in a video and generating hypotheses about causal chains that account for the occurrence of a target event. To facilitate research in this direction, we create two new benchmark datasets with both synthetic and realistic videos, accompanied by trigger-target labels generated through a novel counterfactual synthesis approach. To explore the challenge of solving CARVE, we present a Causal Event Relation Network (CERN) that examines the relationships between video events in temporal and semantic spaces to efficiently determine the root-cause trigger events. Through extensive experiments, we demonstrate the critical roles of event relational representation learning and interaction modeling in solving video causal reasoning challenges. The introduction of the CARVE task, along with the accompanying datasets and the CERN framework, will advance future research on video causal reasoning and significantly facilitate various applications, including video surveillance, root-cause analysis and movie content management.
SADL: An Effective In-Context Learning Method for Compositional Visual QA
Jul 02, 2024


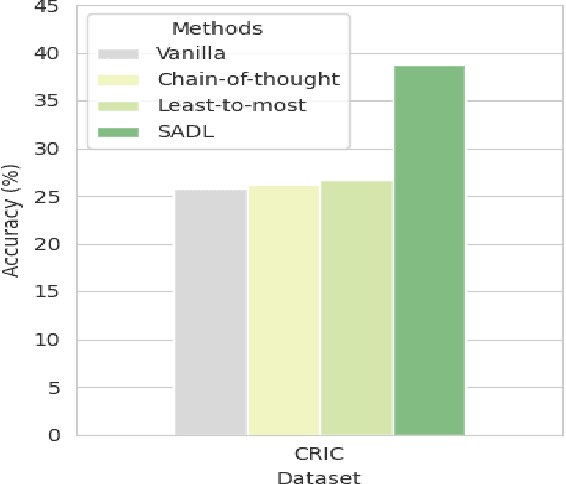
Large vision-language models (LVLMs) offer a novel capability for performing in-context learning (ICL) in Visual QA. When prompted with a few demonstrations of image-question-answer triplets, LVLMs have demonstrated the ability to discern underlying patterns and transfer this latent knowledge to answer new questions about unseen images without the need for expensive supervised fine-tuning. However, designing effective vision-language prompts, especially for compositional questions, remains poorly understood. Adapting language-only ICL techniques may not necessarily work because we need to bridge the visual-linguistic semantic gap: Symbolic concepts must be grounded in visual content, which does not share the syntactic linguistic structures. This paper introduces SADL, a new visual-linguistic prompting framework for the task. SADL revolves around three key components: SAmpling, Deliberation, and Pseudo-Labeling of image-question pairs. Given an image-question query, we sample image-question pairs from the training data that are in semantic proximity to the query. To address the compositional nature of questions, the deliberation step decomposes complex questions into a sequence of subquestions. Finally, the sequence is progressively annotated one subquestion at a time to generate a sequence of pseudo-labels. We investigate the behaviors of SADL under OpenFlamingo on large-scale Visual QA datasets, namely GQA, GQA-OOD, CLEVR, and CRIC. The evaluation demonstrates the critical roles of sampling in the neighborhood of the image, the decomposition of complex questions, and the accurate pairing of the subquestions and labels. These findings do not always align with those found in language-only ICL, suggesting fresh insights in vision-language settings.
Persistent-Transient Duality: A Multi-mechanism Approach for Modeling Human-Object Interaction
Jul 24, 2023Humans are highly adaptable, swiftly switching between different modes to progressively handle different tasks, situations and contexts. In Human-object interaction (HOI) activities, these modes can be attributed to two mechanisms: (1) the large-scale consistent plan for the whole activity and (2) the small-scale children interactive actions that start and end along the timeline. While neuroscience and cognitive science have confirmed this multi-mechanism nature of human behavior, machine modeling approaches for human motion are trailing behind. While attempted to use gradually morphing structures (e.g., graph attention networks) to model the dynamic HOI patterns, they miss the expeditious and discrete mode-switching nature of the human motion. To bridge that gap, this work proposes to model two concurrent mechanisms that jointly control human motion: the Persistent process that runs continually on the global scale, and the Transient sub-processes that operate intermittently on the local context of the human while interacting with objects. These two mechanisms form an interactive Persistent-Transient Duality that synergistically governs the activity sequences. We model this conceptual duality by a parent-child neural network of Persistent and Transient channels with a dedicated neural module for dynamic mechanism switching. The framework is trialed on HOI motion forecasting. On two rich datasets and a wide variety of settings, the model consistently delivers superior performances, proving its suitability for the challenge.
Video Dialog as Conversation about Objects Living in Space-Time
Jul 08, 2022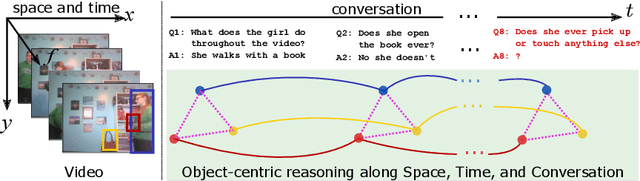

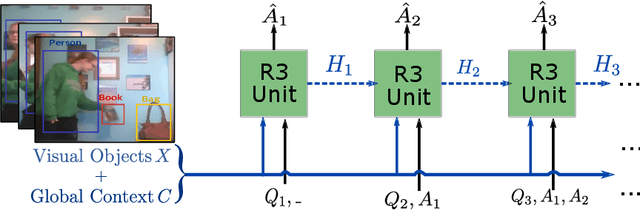
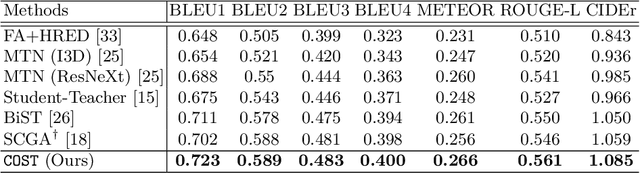
It would be a technological feat to be able to create a system that can hold a meaningful conversation with humans about what they watch. A setup toward that goal is presented as a video dialog task, where the system is asked to generate natural utterances in response to a question in an ongoing dialog. The task poses great visual, linguistic, and reasoning challenges that cannot be easily overcome without an appropriate representation scheme over video and dialog that supports high-level reasoning. To tackle these challenges we present a new object-centric framework for video dialog that supports neural reasoning dubbed COST - which stands for Conversation about Objects in Space-Time. Here dynamic space-time visual content in videos is first parsed into object trajectories. Given this video abstraction, COST maintains and tracks object-associated dialog states, which are updated upon receiving new questions. Object interactions are dynamically and conditionally inferred for each question, and these serve as the basis for relational reasoning among them. COST also maintains a history of previous answers, and this allows retrieval of relevant object-centric information to enrich the answer forming process. Language production then proceeds in a step-wise manner, taking into the context of the current utterance, the existing dialog, the current question. We evaluate COST on the DSTC7 and DSTC8 benchmarks, demonstrating its competitiveness against state-of-the-arts.
Guiding Visual Question Answering with Attention Priors
May 25, 2022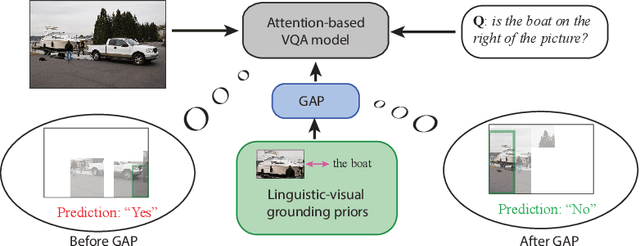
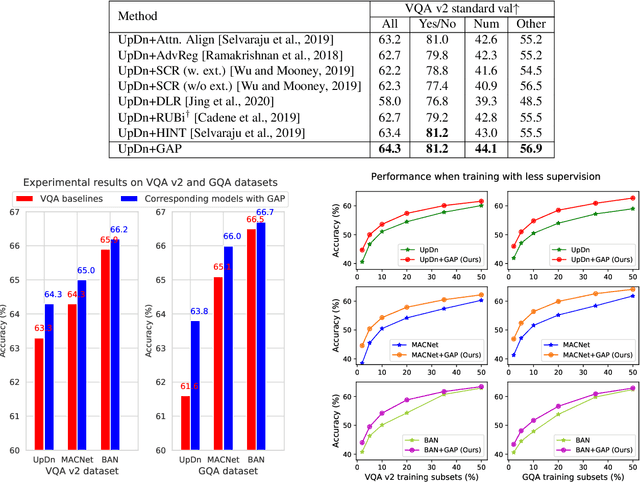
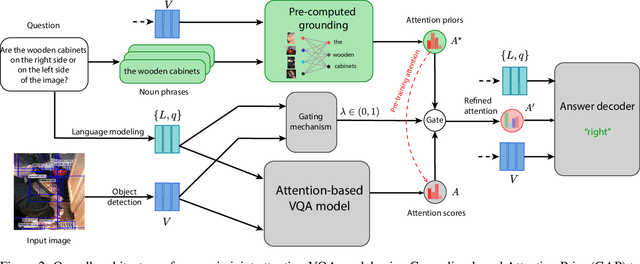

The current success of modern visual reasoning systems is arguably attributed to cross-modality attention mechanisms. However, in deliberative reasoning such as in VQA, attention is unconstrained at each step, and thus may serve as a statistical pooling mechanism rather than a semantic operation intended to select information relevant to inference. This is because at training time, attention is only guided by a very sparse signal (i.e. the answer label) at the end of the inference chain. This causes the cross-modality attention weights to deviate from the desired visual-language bindings. To rectify this deviation, we propose to guide the attention mechanism using explicit linguistic-visual grounding. This grounding is derived by connecting structured linguistic concepts in the query to their referents among the visual objects. Here we learn the grounding from the pairing of questions and images alone, without the need for answer annotation or external grounding supervision. This grounding guides the attention mechanism inside VQA models through a duality of mechanisms: pre-training attention weight calculation and directly guiding the weights at inference time on a case-by-case basis. The resultant algorithm is capable of probing attention-based reasoning models, injecting relevant associative knowledge, and regulating the core reasoning process. This scalable enhancement improves the performance of VQA models, fortifies their robustness to limited access to supervised data, and increases interpretability.
Persistent-Transient Duality in Human Behavior Modeling
Apr 21, 2022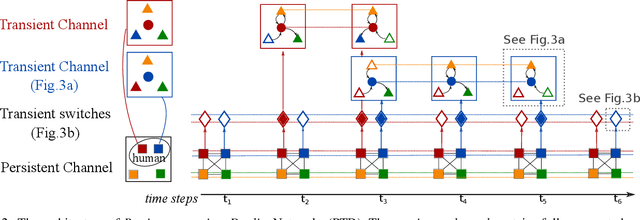
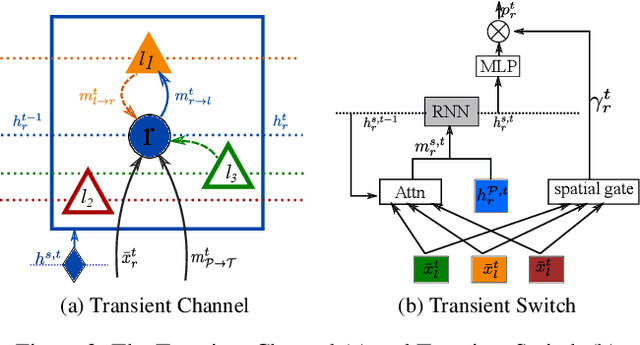
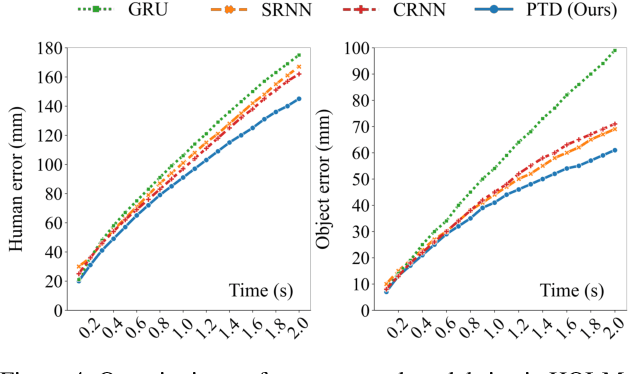
We propose to model the persistent-transient duality in human behavior using a parent-child multi-channel neural network, which features a parent persistent channel that manages the global dynamics and children transient channels that are initiated and terminated on-demand to handle detailed interactive actions. The short-lived transient sessions are managed by a proposed Transient Switch. The neural framework is trained to discover the structure of the duality automatically. Our model shows superior performances in human-object interaction motion prediction.
A Field Guide to Scientific XAI: Transparent and Interpretable Deep Learning for Bioinformatics Research
Oct 13, 2021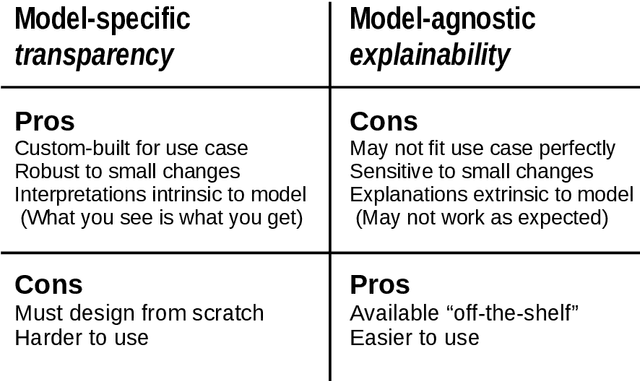
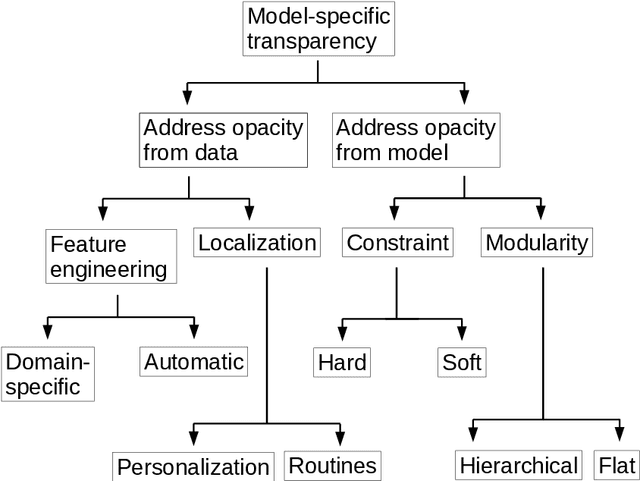


Deep learning has become popular because of its potential to achieve high accuracy in prediction tasks. However, accuracy is not always the only goal of statistical modelling, especially for models developed as part of scientific research. Rather, many scientific models are developed to facilitate scientific discovery, by which we mean to abstract a human-understandable representation of the natural world. Unfortunately, the opacity of deep neural networks limit their role in scientific discovery, creating a new demand for models that are transparently interpretable. This article is a field guide to transparent model design. It provides a taxonomy of transparent model design concepts, a practical workflow for putting design concepts into practice, and a general template for reporting design choices. We hope this field guide will help researchers more effectively design transparently interpretable models, and thus enable them to use deep learning for scientific discovery.
Hierarchical Object-oriented Spatio-Temporal Reasoning for Video Question Answering
Jun 25, 2021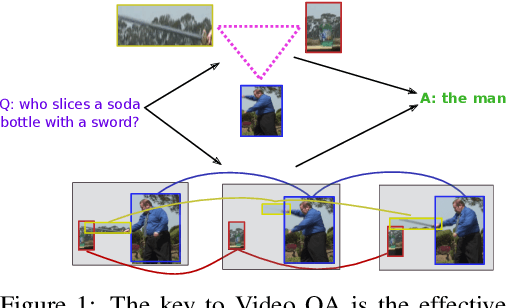
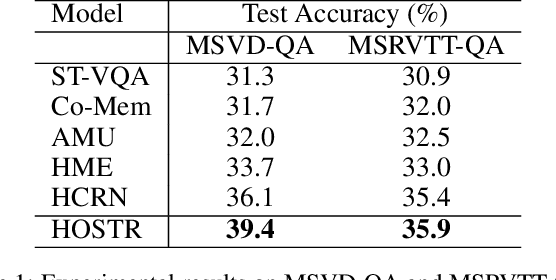

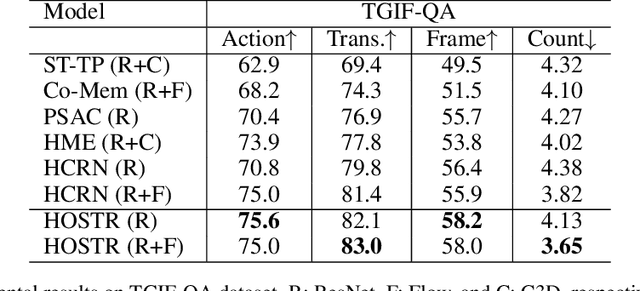
Video Question Answering (Video QA) is a powerful testbed to develop new AI capabilities. This task necessitates learning to reason about objects, relations, and events across visual and linguistic domains in space-time. High-level reasoning demands lifting from associative visual pattern recognition to symbol-like manipulation over objects, their behavior and interactions. Toward reaching this goal we propose an object-oriented reasoning approach in that video is abstracted as a dynamic stream of interacting objects. At each stage of the video event flow, these objects interact with each other, and their interactions are reasoned about with respect to the query and under the overall context of a video. This mechanism is materialized into a family of general-purpose neural units and their multi-level architecture called Hierarchical Object-oriented Spatio-Temporal Reasoning (HOSTR) networks. This neural model maintains the objects' consistent lifelines in the form of a hierarchically nested spatio-temporal graph. Within this graph, the dynamic interactive object-oriented representations are built up along the video sequence, hierarchically abstracted in a bottom-up manner, and converge toward the key information for the correct answer. The method is evaluated on multiple major Video QA datasets and establishes new state-of-the-arts in these tasks. Analysis into the model's behavior indicates that object-oriented reasoning is a reliable, interpretable and efficient approach to Video QA.
A Spatio-temporal Attention-based Model for Infant Movement Assessment from Videos
May 20, 2021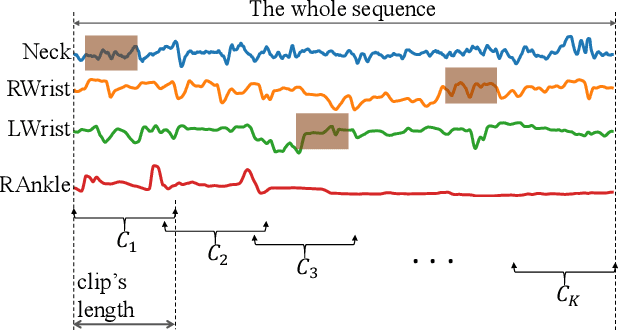
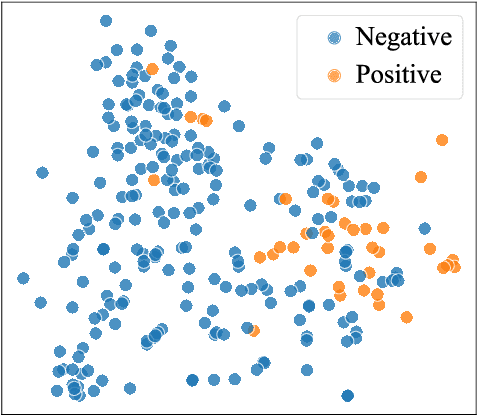
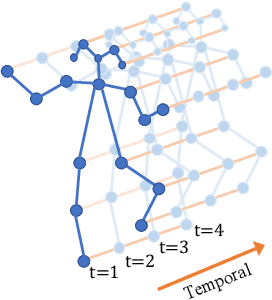

The absence or abnormality of fidgety movements of joints or limbs is strongly indicative of cerebral palsy in infants. Developing computer-based methods for assessing infant movements in videos is pivotal for improved cerebral palsy screening. Most existing methods use appearance-based features and are thus sensitive to strong but irrelevant signals caused by background clutter or a moving camera. Moreover, these features are computed over the whole frame, thus they measure gross whole body movements rather than specific joint/limb motion. Addressing these challenges, we develop and validate a new method for fidgety movement assessment from consumer-grade videos using human poses extracted from short clips. Human poses capture only relevant motion profiles of joints and limbs and are thus free from irrelevant appearance artifacts. The dynamics and coordination between joints are modeled using spatio-temporal graph convolutional networks. Frames and body parts that contain discriminative information about fidgety movements are selected through a spatio-temporal attention mechanism. We validate the proposed model on the cerebral palsy screening task using a real-life consumer-grade video dataset collected at an Australian hospital through the Cerebral Palsy Alliance, Australia. Our experiments show that the proposed method achieves the ROC-AUC score of 81.87%, significantly outperforming existing competing methods with better interpretability.
Object-Centric Representation Learning for Video Question Answering
Apr 13, 2021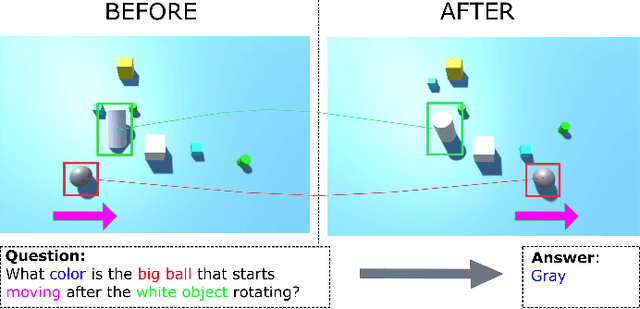
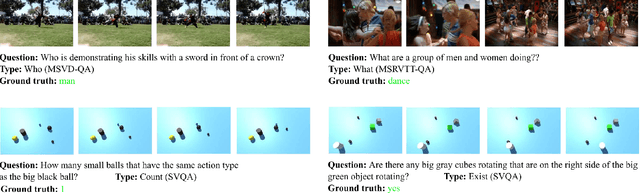
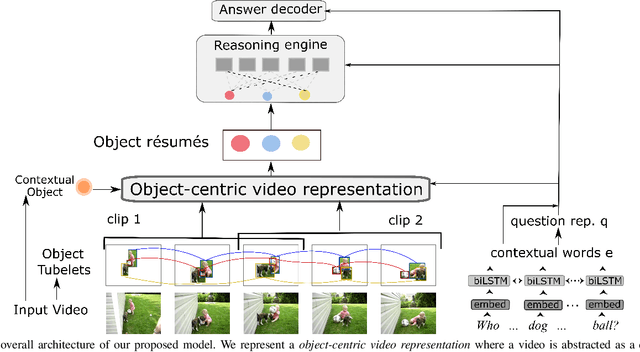
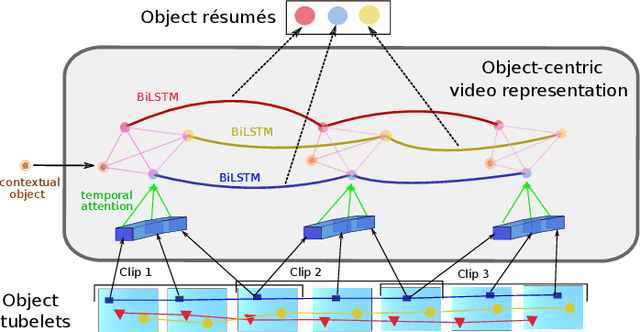
Video question answering (Video QA) presents a powerful testbed for human-like intelligent behaviors. The task demands new capabilities to integrate video processing, language understanding, binding abstract linguistic concepts to concrete visual artifacts, and deliberative reasoning over spacetime. Neural networks offer a promising approach to reach this potential through learning from examples rather than handcrafting features and rules. However, neural networks are predominantly feature-based - they map data to unstructured vectorial representation and thus can fall into the trap of exploiting shortcuts through surface statistics instead of true systematic reasoning seen in symbolic systems. To tackle this issue, we advocate for object-centric representation as a basis for constructing spatio-temporal structures from videos, essentially bridging the semantic gap between low-level pattern recognition and high-level symbolic algebra. To this end, we propose a new query-guided representation framework to turn a video into an evolving relational graph of objects, whose features and interactions are dynamically and conditionally inferred. The object lives are then summarized into resumes, lending naturally for deliberative relational reasoning that produces an answer to the query. The framework is evaluated on major Video QA datasets, demonstrating clear benefits of the object-centric approach to video reasoning.