 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVibe Code Bench: Evaluating AI Models on End-to-End Web Application Development
Mar 04, 2026Code generation has emerged as one of AI's highest-impact use cases, yet existing benchmarks measure isolated tasks rather than the complete "zero-to-one" process of building a working application from scratch. We introduce Vibe Code Bench, a benchmark of 100 web application specifications (50 public validation, 50 held-out test) with 964 browser-based workflows comprising 10,131 substeps, evaluated against deployed applications by an autonomous browser agent. Across 16 frontier models, the best achieves only 58.0% accuracy on the test split, revealing that reliable end-to-end application development remains a frontier challenge. We identify self-testing during generation as a strong performance predictor (Pearson r=0.72), and show through a completed human alignment study that evaluator selection materially affects outcomes (31.8-93.6% pairwise step-level agreement). Our contributions include (1) a novel benchmark dataset and browser-based evaluation pipeline for end-to-end web application development, (2) a comprehensive evaluation of 16 frontier models with cost, latency, and error analysis, and (3) an evaluator alignment protocol with both cross-model and human annotation results.
The Enhanced Physics-Informed Kolmogorov-Arnold Networks: Applications of Newton's Laws in Financial Deep Reinforcement Learning (RL) Algorithms
Feb 01, 2026Deep Reinforcement Learning (DRL), a subset of machine learning focused on sequential decision-making, has emerged as a powerful approach for tackling financial trading problems. In finance, DRL is commonly used either to generate discrete trade signals or to determine continuous portfolio allocations. In this work, we propose a novel reinforcement learning framework for portfolio optimization that incorporates Physics-Informed Kolmogorov-Arnold Networks (PIKANs) into several DRL algorithms. The approach replaces conventional multilayer perceptrons with Kolmogorov-Arnold Networks (KANs) in both actor and critic components-utilizing learnable B-spline univariate functions to achieve parameter-efficient and more interpretable function approximation. During actor updates, we introduce a physics-informed regularization loss that promotes second-order temporal consistency between observed return dynamics and the action-induced portfolio adjustments. The proposed framework is evaluated across three equity markets-China, Vietnam, and the United States, covering both emerging and developed economies. Across all three markets, PIKAN-based agents consistently deliver higher cumulative and annualized returns, superior Sharpe and Calmar ratios, and more favorable drawdown characteristics compared to both standard DRL baselines and classical online portfolio-selection methods. This yields more stable training, higher Sharpe ratios, and superior performance compared to traditional DRL counterparts. The approach is particularly valuable in highly dynamic and noisy financial markets, where conventional DRL often suffers from instability and poor generalization.
UAV-Assisted Resilience in 6G and Beyond Network Energy Saving: A Multi-Agent DRL Approach
Nov 10, 2025This paper investigates the unmanned aerial vehicle (UAV)-assisted resilience perspective in the 6G network energy saving (NES) scenario. More specifically, we consider multiple ground base stations (GBSs) and each GBS has three different sectors/cells in the terrestrial networks, and multiple cells are turned off due to NES or incidents, e.g., disasters, hardware failures, or outages. To address this, we propose a Multi-Agent Deep Deterministic Policy Gradient (MADDPG) framework to enable UAV-assisted communication by jointly optimizing UAV trajectories, transmission power, and user-UAV association under a sleeping ground base station (GBS) strategy. This framework aims to ensure the resilience of active users in the network and the long-term operability of UAVs. Specifically, it maximizes service coverage for users during power outages or NES zones, while minimizing the energy consumption of UAVs. Simulation results demonstrate that the proposed MADDPG policy consistently achieves high coverage ratio across different testing episodes, outperforming other baselines. Moreover, the MADDPG framework attains the lowest total energy consumption, with a reduction of approximately 24\% compared to the conventional all GBS ON configuration, while maintaining a comparable user service rate. These results confirm the effectiveness of the proposed approach in achieving a superior trade-off between energy efficiency and service performance, supporting the development of sustainable and resilient UAV-assisted cellular networks.
Unified Framework with Consistency across Modalities for Human Activity Recognition
Sep 04, 2024



Recognizing human activities in videos is challenging due to the spatio-temporal complexity and context-dependence of human interactions. Prior studies often rely on single input modalities, such as RGB or skeletal data, limiting their ability to exploit the complementary advantages across modalities. Recent studies focus on combining these two modalities using simple feature fusion techniques. However, due to the inherent disparities in representation between these input modalities, designing a unified neural network architecture to effectively leverage their complementary information remains a significant challenge. To address this, we propose a comprehensive multimodal framework for robust video-based human activity recognition. Our key contribution is the introduction of a novel compositional query machine, called COMPUTER ($\textbf{COMP}ositional h\textbf{U}man-cen\textbf{T}ric qu\textbf{ER}y$ machine), a generic neural architecture that models the interactions between a human of interest and its surroundings in both space and time. Thanks to its versatile design, COMPUTER can be leveraged to distill distinctive representations for various input modalities. Additionally, we introduce a consistency loss that enforces agreement in prediction between modalities, exploiting the complementary information from multimodal inputs for robust human movement recognition. Through extensive experiments on action localization and group activity recognition tasks, our approach demonstrates superior performance when compared with state-of-the-art methods. Our code is available at: https://github.com/tranxuantuyen/COMPUTER.
Persistent-Transient Duality: A Multi-mechanism Approach for Modeling Human-Object Interaction
Jul 24, 2023Humans are highly adaptable, swiftly switching between different modes to progressively handle different tasks, situations and contexts. In Human-object interaction (HOI) activities, these modes can be attributed to two mechanisms: (1) the large-scale consistent plan for the whole activity and (2) the small-scale children interactive actions that start and end along the timeline. While neuroscience and cognitive science have confirmed this multi-mechanism nature of human behavior, machine modeling approaches for human motion are trailing behind. While attempted to use gradually morphing structures (e.g., graph attention networks) to model the dynamic HOI patterns, they miss the expeditious and discrete mode-switching nature of the human motion. To bridge that gap, this work proposes to model two concurrent mechanisms that jointly control human motion: the Persistent process that runs continually on the global scale, and the Transient sub-processes that operate intermittently on the local context of the human while interacting with objects. These two mechanisms form an interactive Persistent-Transient Duality that synergistically governs the activity sequences. We model this conceptual duality by a parent-child neural network of Persistent and Transient channels with a dedicated neural module for dynamic mechanism switching. The framework is trialed on HOI motion forecasting. On two rich datasets and a wide variety of settings, the model consistently delivers superior performances, proving its suitability for the challenge.
Machine Learning-Based Intrusion Detection: Feature Selection versus Feature Extraction
Jul 04, 2023



Internet of things (IoT) has been playing an important role in many sectors, such as smart cities, smart agriculture, smart healthcare, and smart manufacturing. However, IoT devices are highly vulnerable to cyber-attacks, which may result in security breaches and data leakages. To effectively prevent these attacks, a variety of machine learning-based network intrusion detection methods for IoT networks have been developed, which often rely on either feature extraction or feature selection techniques for reducing the dimension of input data before being fed into machine learning models. This aims to make the detection complexity low enough for real-time operations, which is particularly vital in any intrusion detection systems. This paper provides a comprehensive comparison between these two feature reduction methods of intrusion detection in terms of various performance metrics, namely, precision rate, recall rate, detection accuracy, as well as runtime complexity, in the presence of the modern UNSW-NB15 dataset as well as both binary and multiclass classification. For example, in general, the feature selection method not only provides better detection performance but also lower training and inference time compared to its feature extraction counterpart, especially when the number of reduced features K increases. However, the feature extraction method is much more reliable than its selection counterpart, particularly when K is very small, such as K = 4. Additionally, feature extraction is less sensitive to changing the number of reduced features K than feature selection, and this holds true for both binary and multiclass classifications. Based on this comparison, we provide a useful guideline for selecting a suitable intrusion detection type for each specific scenario, as detailed in Tab. 14 at the end of Section IV.
Neural Collapse in Deep Linear Network: From Balanced to Imbalanced Data
Jan 01, 2023

Modern deep neural networks have achieved superhuman performance in tasks from image classification to game play. Surprisingly, these various complex systems with massive amounts of parameters exhibit the same remarkable structural properties in their last-layer features and classifiers across canonical datasets. This phenomenon is known as "Neural Collapse," and it was discovered empirically by Papyan et al. \cite{Papyan20}. Recent papers have theoretically shown the global solutions to the training network problem under a simplified "unconstrained feature model" exhibiting this phenomenon. We take a step further and prove the Neural Collapse occurrence for deep linear network for the popular mean squared error (MSE) and cross entropy (CE) loss. Furthermore, we extend our research to imbalanced data for MSE loss and present the first geometric analysis for Neural Collapse under this setting.
Persistent-Transient Duality in Human Behavior Modeling
Apr 21, 2022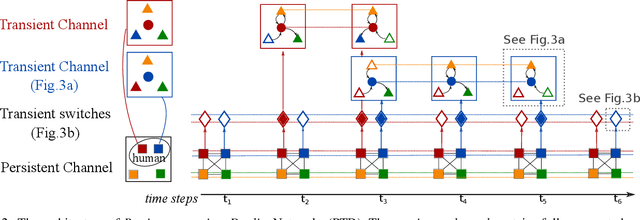
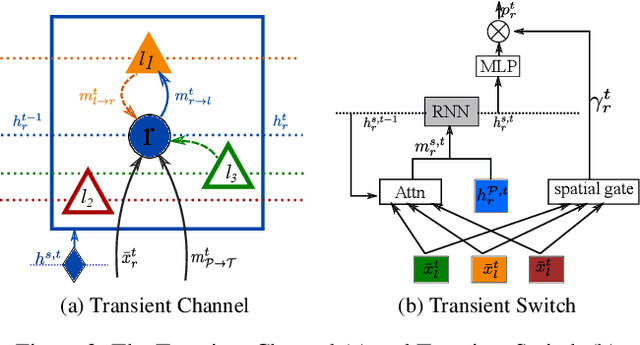
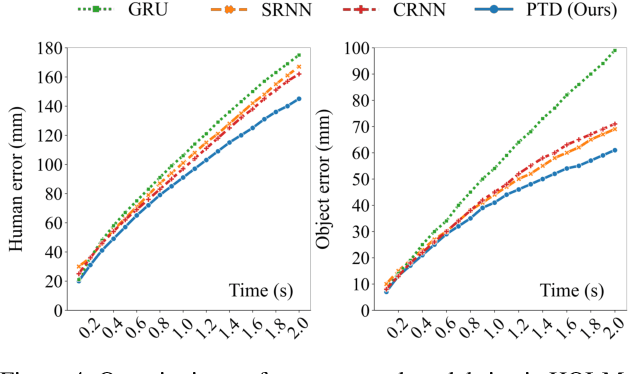
We propose to model the persistent-transient duality in human behavior using a parent-child multi-channel neural network, which features a parent persistent channel that manages the global dynamics and children transient channels that are initiated and terminated on-demand to handle detailed interactive actions. The short-lived transient sessions are managed by a proposed Transient Switch. The neural framework is trained to discover the structure of the duality automatically. Our model shows superior performances in human-object interaction motion prediction.
Goal-driven Long-Term Trajectory Prediction
Nov 06, 2020


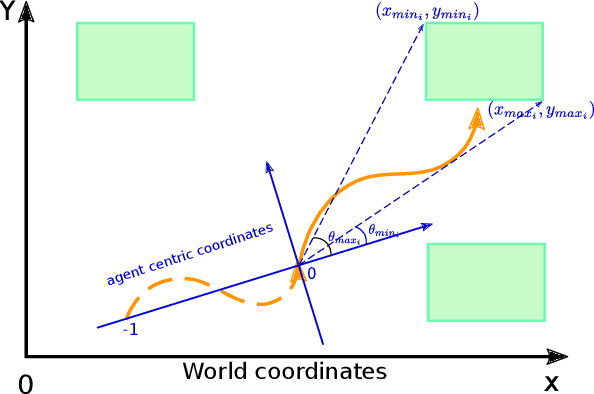
The prediction of humans' short-term trajectories has advanced significantly with the use of powerful sequential modeling and rich environment feature extraction. However, long-term prediction is still a major challenge for the current methods as the errors could accumulate along the way. Indeed, consistent and stable prediction far to the end of a trajectory inherently requires deeper analysis into the overall structure of that trajectory, which is related to the pedestrian's intention on the destination of the journey. In this work, we propose to model a hypothetical process that determines pedestrians' goals and the impact of such process on long-term future trajectories. We design Goal-driven Trajectory Prediction model - a dual-channel neural network that realizes such intuition. The two channels of the network take their dedicated roles and collaborate to generate future trajectories. Different than conventional goal-conditioned, planning-based methods, the model architecture is designed to generalize the patterns and work across different scenes with arbitrary geometrical and semantic structures. The model is shown to outperform the state-of-the-art in various settings, especially in large prediction horizons. This result is another evidence for the effectiveness of adaptive structured representation of visual and geometrical features in human behavior analysis.