 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Mechanisms of Collaborative Learning in VAE Recommenders
Nov 10, 2025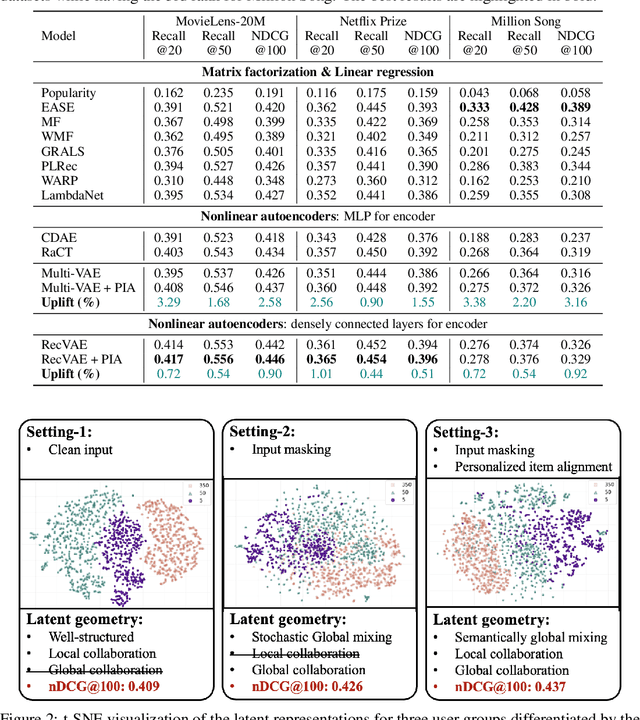
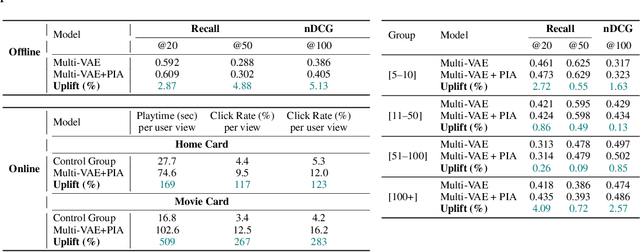

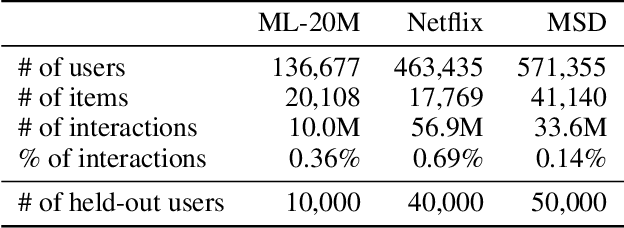
Variational Autoencoders (VAEs) are a powerful alternative to matrix factorization for recommendation. A common technique in VAE-based collaborative filtering (CF) consists in applying binary input masking to user interaction vectors, which improves performance but remains underexplored theoretically. In this work, we analyze how collaboration arises in VAE-based CF and show it is governed by latent proximity: we derive a latent sharing radius that informs when an SGD update on one user strictly reduces the loss on another user, with influence decaying as the latent Wasserstein distance increases. We further study the induced geometry: with clean inputs, VAE-based CF primarily exploits \emph{local} collaboration between input-similar users and under-utilizes global collaboration between far-but-related users. We compare two mechanisms that encourage \emph{global} mixing and characterize their trade-offs: (1) $β$-KL regularization directly tightens the information bottleneck, promoting posterior overlap but risking representational collapse if too large; (2) input masking induces stochastic geometric contractions and expansions, which can bring distant users onto the same latent neighborhood but also introduce neighborhood drift. To preserve user identity while enabling global consistency, we propose an anchor regularizer that aligns user posteriors with item embeddings, stabilizing users under masking and facilitating signal sharing across related items. Our analyses are validated on the Netflix, MovieLens-20M, and Million Song datasets. We also successfully deployed our proposed algorithm on an Amazon streaming platform following a successful online experiment.
DoRAN: Stabilizing Weight-Decomposed Low-Rank Adaptation via Noise Injection and Auxiliary Networks
Oct 05, 2025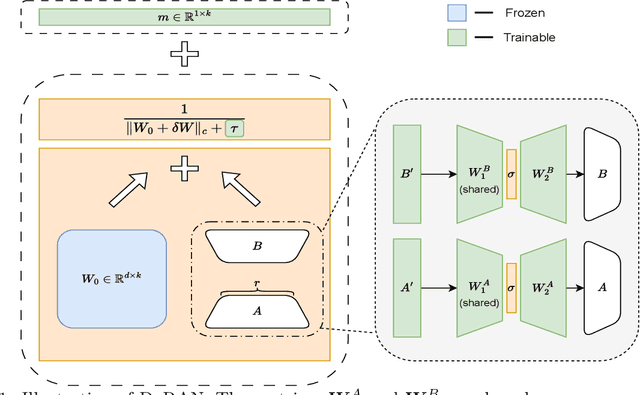

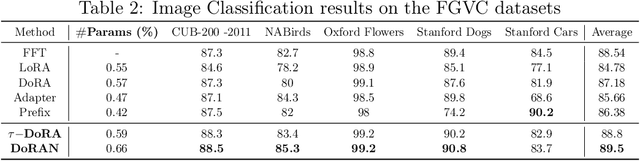
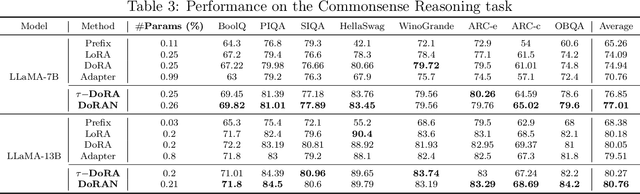
Parameter-efficient fine-tuning (PEFT) methods have become the standard paradigm for adapting large-scale models. Among these techniques, Weight-Decomposed Low-Rank Adaptation (DoRA) has been shown to improve both the learning capacity and training stability of the vanilla Low-Rank Adaptation (LoRA) method by explicitly decomposing pre-trained weights into magnitude and directional components. In this work, we propose DoRAN, a new variant of DoRA designed to further stabilize training and boost the sample efficiency of DoRA. Our approach includes two key stages: (i) injecting noise into the denominator of DoRA's weight decomposition, which serves as an adaptive regularizer to mitigate instabilities; and (ii) replacing static low-rank matrices with auxiliary networks that generate them dynamically, enabling parameter coupling across layers and yielding better sample efficiency in both theory and practice. Comprehensive experiments on vision and language benchmarks show that DoRAN consistently outperforms LoRA, DoRA, and other PEFT baselines. These results underscore the effectiveness of combining stabilization through noise-based regularization with network-based parameter generation, offering a promising direction for robust and efficient fine-tuning of foundation models.
Neural Collapse for Cross-entropy Class-Imbalanced Learning with Unconstrained ReLU Feature Model
Jan 04, 2024


The current paradigm of training deep neural networks for classification tasks includes minimizing the empirical risk that pushes the training loss value towards zero, even after the training error has been vanished. In this terminal phase of training, it has been observed that the last-layer features collapse to their class-means and these class-means converge to the vertices of a simplex Equiangular Tight Frame (ETF). This phenomenon is termed as Neural Collapse (NC). To theoretically understand this phenomenon, recent works employ a simplified unconstrained feature model to prove that NC emerges at the global solutions of the training problem. However, when the training dataset is class-imbalanced, some NC properties will no longer be true. For example, the class-means geometry will skew away from the simplex ETF when the loss converges. In this paper, we generalize NC to imbalanced regime for cross-entropy loss under the unconstrained ReLU feature model. We prove that, while the within-class features collapse property still holds in this setting, the class-means will converge to a structure consisting of orthogonal vectors with different lengths. Furthermore, we find that the classifier weights are aligned to the scaled and centered class-means with scaling factors depend on the number of training samples of each class, which generalizes NC in the class-balanced setting. We empirically prove our results through experiments on practical architectures and dataset.
Posterior Collapse in Linear Conditional and Hierarchical Variational Autoencoders
Jun 08, 2023



The posterior collapse phenomenon in variational autoencoders (VAEs), where the variational posterior distribution closely matches the prior distribution, can hinder the quality of the learned latent variables. As a consequence of posterior collapse, the latent variables extracted by the encoder in VAEs preserve less information from the input data and thus fail to produce meaningful representations as input to the reconstruction process in the decoder. While this phenomenon has been an actively addressed topic related to VAEs performance, the theory for posterior collapse remains underdeveloped, especially beyond the standard VAEs. In this work, we advance the theoretical understanding of posterior collapse to two important and prevalent yet less studied classes of VAEs: conditional VAEs and hierarchical VAEs. Specifically, via a non-trivial theoretical analysis of linear conditional VAEs and hierarchical VAEs with two levels of latent, we prove that the cause of posterior collapses in these models includes the correlation between the input and output of the conditional VAEs and the effect of learnable encoder variance in the hierarchical VAEs. We empirically validate our theoretical findings for linear conditional and hierarchical VAEs and demonstrate that these results are also predictive for non-linear cases.
Neural Collapse in Deep Linear Network: From Balanced to Imbalanced Data
Jan 01, 2023

Modern deep neural networks have achieved superhuman performance in tasks from image classification to game play. Surprisingly, these various complex systems with massive amounts of parameters exhibit the same remarkable structural properties in their last-layer features and classifiers across canonical datasets. This phenomenon is known as "Neural Collapse," and it was discovered empirically by Papyan et al. \cite{Papyan20}. Recent papers have theoretically shown the global solutions to the training network problem under a simplified "unconstrained feature model" exhibiting this phenomenon. We take a step further and prove the Neural Collapse occurrence for deep linear network for the popular mean squared error (MSE) and cross entropy (CE) loss. Furthermore, we extend our research to imbalanced data for MSE loss and present the first geometric analysis for Neural Collapse under this setting.