 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProgressive Multi-granular Alignments for Grounded Reasoning in Large Vision-Language Models
Dec 11, 2024Existing Large Vision-Language Models (LVLMs) excel at matching concepts across multi-modal inputs but struggle with compositional concepts and high-level relationships between entities. This paper introduces Progressive multi-granular Vision-Language alignments (PromViL), a novel framework to enhance LVLMs' ability in performing grounded compositional visual reasoning tasks. Our approach constructs a hierarchical structure of multi-modal alignments, ranging from simple to complex concepts. By progressively aligning textual descriptions with corresponding visual regions, our model learns to leverage contextual information from lower levels to inform higher-level reasoning. To facilitate this learning process, we introduce a data generation process that creates a novel dataset derived from Visual Genome, providing a wide range of nested compositional vision-language pairs. Experimental results demonstrate that our PromViL framework significantly outperforms baselines on various visual grounding and compositional question answering tasks.
AHMsys: An Automated HVAC Modeling System for BIM Project
Jul 02, 2024This paper presents a novel system, named AHMsys, designed to automate the process of generating 3D Heating, Ventilation, and Air Conditioning (HVAC) models from 2D Computer-Aided Design (CAD) drawings, a key component of Building Information Modeling (BIM). By automatically preprocessing and extracting essential HVAC object information then creating detailed 3D models, our proposed AHMsys significantly reduced the 20 percent work schedule of the BIM process in Akila. This advancement highlights the essential impact of integrating AI technologies in managing the lifecycle of a digital representation of the building.
SADL: An Effective In-Context Learning Method for Compositional Visual QA
Jul 02, 2024


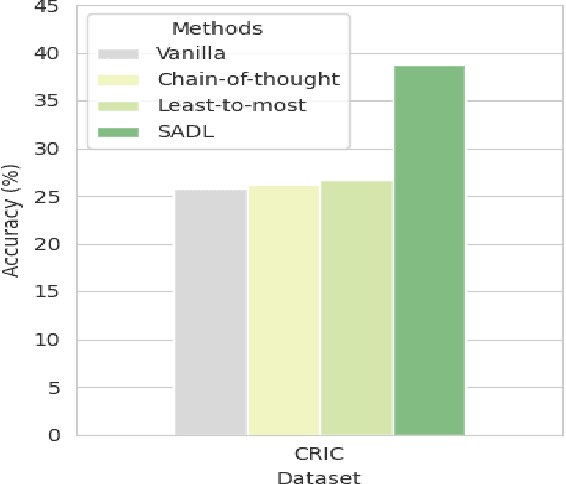
Large vision-language models (LVLMs) offer a novel capability for performing in-context learning (ICL) in Visual QA. When prompted with a few demonstrations of image-question-answer triplets, LVLMs have demonstrated the ability to discern underlying patterns and transfer this latent knowledge to answer new questions about unseen images without the need for expensive supervised fine-tuning. However, designing effective vision-language prompts, especially for compositional questions, remains poorly understood. Adapting language-only ICL techniques may not necessarily work because we need to bridge the visual-linguistic semantic gap: Symbolic concepts must be grounded in visual content, which does not share the syntactic linguistic structures. This paper introduces SADL, a new visual-linguistic prompting framework for the task. SADL revolves around three key components: SAmpling, Deliberation, and Pseudo-Labeling of image-question pairs. Given an image-question query, we sample image-question pairs from the training data that are in semantic proximity to the query. To address the compositional nature of questions, the deliberation step decomposes complex questions into a sequence of subquestions. Finally, the sequence is progressively annotated one subquestion at a time to generate a sequence of pseudo-labels. We investigate the behaviors of SADL under OpenFlamingo on large-scale Visual QA datasets, namely GQA, GQA-OOD, CLEVR, and CRIC. The evaluation demonstrates the critical roles of sampling in the neighborhood of the image, the decomposition of complex questions, and the accurate pairing of the subquestions and labels. These findings do not always align with those found in language-only ICL, suggesting fresh insights in vision-language settings.
Hierarchical Object-oriented Spatio-Temporal Reasoning for Video Question Answering
Jun 25, 2021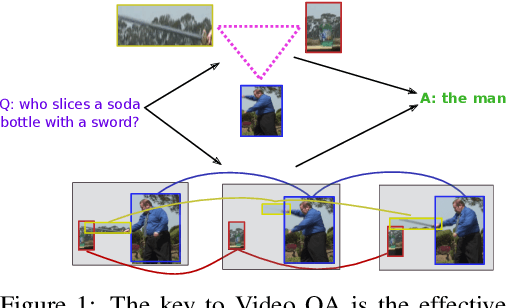
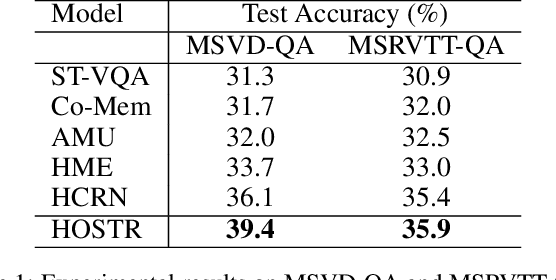

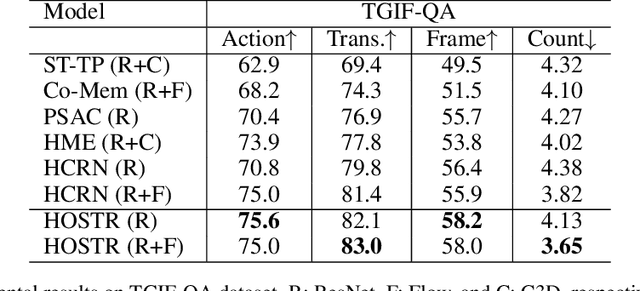
Video Question Answering (Video QA) is a powerful testbed to develop new AI capabilities. This task necessitates learning to reason about objects, relations, and events across visual and linguistic domains in space-time. High-level reasoning demands lifting from associative visual pattern recognition to symbol-like manipulation over objects, their behavior and interactions. Toward reaching this goal we propose an object-oriented reasoning approach in that video is abstracted as a dynamic stream of interacting objects. At each stage of the video event flow, these objects interact with each other, and their interactions are reasoned about with respect to the query and under the overall context of a video. This mechanism is materialized into a family of general-purpose neural units and their multi-level architecture called Hierarchical Object-oriented Spatio-Temporal Reasoning (HOSTR) networks. This neural model maintains the objects' consistent lifelines in the form of a hierarchically nested spatio-temporal graph. Within this graph, the dynamic interactive object-oriented representations are built up along the video sequence, hierarchically abstracted in a bottom-up manner, and converge toward the key information for the correct answer. The method is evaluated on multiple major Video QA datasets and establishes new state-of-the-arts in these tasks. Analysis into the model's behavior indicates that object-oriented reasoning is a reliable, interpretable and efficient approach to Video QA.
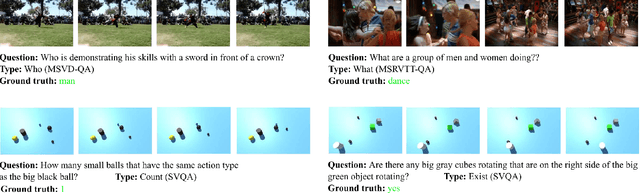
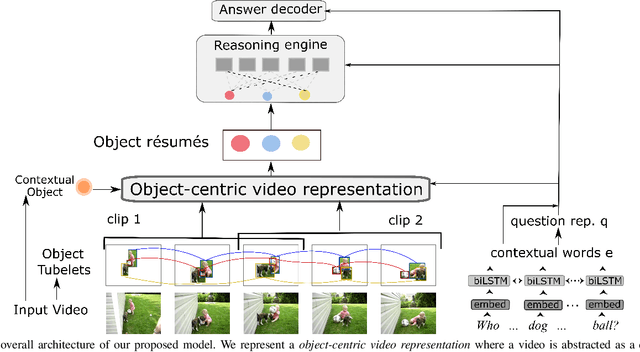
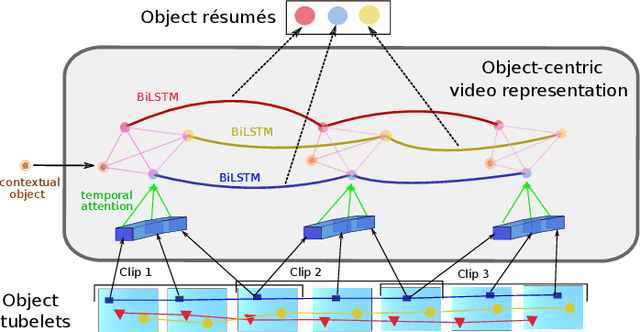
Object-Centric Representation Learning for Video Question Answering
Apr 13, 2021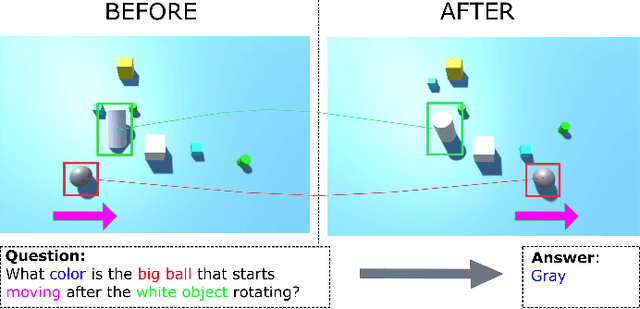
Video question answering (Video QA) presents a powerful testbed for human-like intelligent behaviors. The task demands new capabilities to integrate video processing, language understanding, binding abstract linguistic concepts to concrete visual artifacts, and deliberative reasoning over spacetime. Neural networks offer a promising approach to reach this potential through learning from examples rather than handcrafting features and rules. However, neural networks are predominantly feature-based - they map data to unstructured vectorial representation and thus can fall into the trap of exploiting shortcuts through surface statistics instead of true systematic reasoning seen in symbolic systems. To tackle this issue, we advocate for object-centric representation as a basis for constructing spatio-temporal structures from videos, essentially bridging the semantic gap between low-level pattern recognition and high-level symbolic algebra. To this end, we propose a new query-guided representation framework to turn a video into an evolving relational graph of objects, whose features and interactions are dynamically and conditionally inferred. The object lives are then summarized into resumes, lending naturally for deliberative relational reasoning that produces an answer to the query. The framework is evaluated on major Video QA datasets, demonstrating clear benefits of the object-centric approach to video reasoning.