 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAHMsys: An Automated HVAC Modeling System for BIM Project
Jul 02, 2024This paper presents a novel system, named AHMsys, designed to automate the process of generating 3D Heating, Ventilation, and Air Conditioning (HVAC) models from 2D Computer-Aided Design (CAD) drawings, a key component of Building Information Modeling (BIM). By automatically preprocessing and extracting essential HVAC object information then creating detailed 3D models, our proposed AHMsys significantly reduced the 20 percent work schedule of the BIM process in Akila. This advancement highlights the essential impact of integrating AI technologies in managing the lifecycle of a digital representation of the building.
Automatic Prompt Selection for Large Language Models
Apr 03, 2024



Large Language Models (LLMs) can perform various natural language processing tasks with suitable instruction prompts. However, designing effective prompts manually is challenging and time-consuming. Existing methods for automatic prompt optimization either lack flexibility or efficiency. In this paper, we propose an effective approach to automatically select the optimal prompt for a given input from a finite set of synthetic candidate prompts. Our approach consists of three steps: (1) clustering the training data and generating candidate prompts for each cluster using an LLM-based prompt generator; (2) synthesizing a dataset of input-prompt-output tuples for training a prompt evaluator to rank the prompts based on their relevance to the input; (3) using the prompt evaluator to select the best prompt for a new input at test time. Our approach balances prompt generality-specificity and eliminates the need for resource-intensive training and inference. It demonstrates competitive performance on zero-shot question-answering datasets: GSM8K, MultiArith, and AQuA.
Universal Graph Continual Learning
Aug 27, 2023
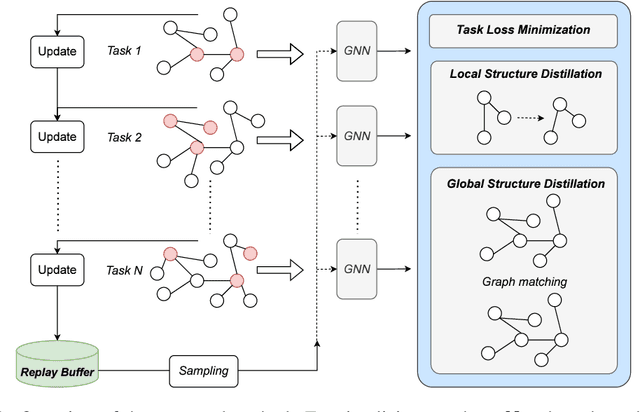
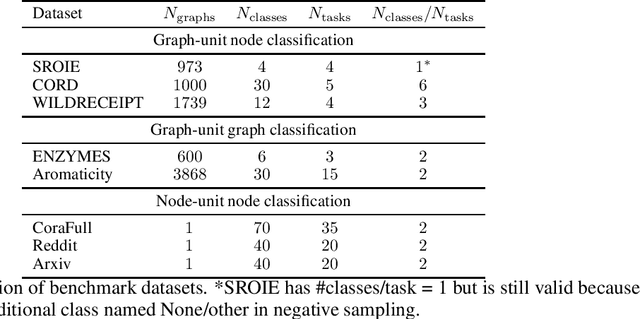
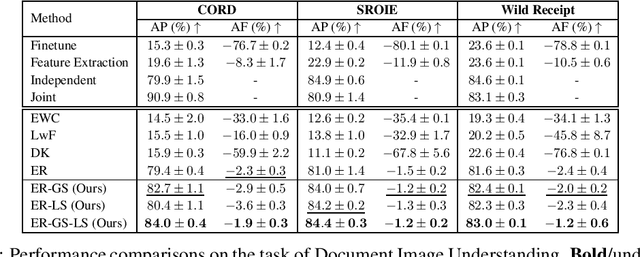
We address catastrophic forgetting issues in graph learning as incoming data transits from one to another graph distribution. Whereas prior studies primarily tackle one setting of graph continual learning such as incremental node classification, we focus on a universal approach wherein each data point in a task can be a node or a graph, and the task varies from node to graph classification. We propose a novel method that enables graph neural networks to excel in this universal setting. Our approach perseveres knowledge about past tasks through a rehearsal mechanism that maintains local and global structure consistency across the graphs. We benchmark our method against various continual learning baselines in real-world graph datasets and achieve significant improvement in average performance and forgetting across tasks.
When Giant Language Brains Just Aren't Enough! Domain Pizzazz with Knowledge Sparkle Dust
May 12, 2023Large language models (LLMs) have significantly advanced the field of natural language processing, with GPT models at the forefront. While their remarkable performance spans a range of tasks, adapting LLMs for real-world business scenarios still poses challenges warranting further investigation. This paper presents an empirical analysis aimed at bridging the gap in adapting LLMs to practical use cases. To do that, we select the question answering (QA) task of insurance as a case study due to its challenge of reasoning. Based on the task we design a new model relied on LLMs which are empowered by domain-specific knowledge extracted from insurance policy rulebooks. The domain-specific knowledge helps LLMs to understand new concepts of insurance for domain adaptation. Preliminary results on real QA pairs show that knowledge enhancement from policy rulebooks significantly improves the reasoning ability of GPT-3.5 of 50.4% in terms of accuracy. The analysis also indicates that existing public knowledge bases, e.g., DBPedia is beneficial for knowledge enhancement. Our findings reveal that the inherent complexity of business scenarios often necessitates the incorporation of domain-specific knowledge and external resources for effective problem-solving.
Make The Most of Prior Data: A Solution for Interactive Text Summarization with Preference Feedback
Apr 12, 2022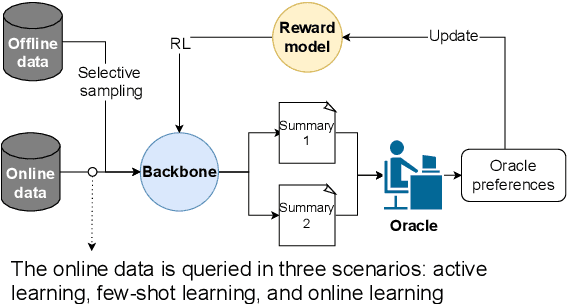

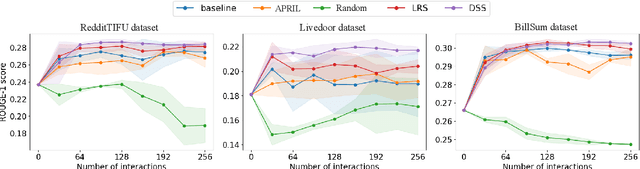

For summarization, human preference is critical to tame outputs of the summarizer in favor of human interests, as ground-truth summaries are scarce and ambiguous. Practical settings require dynamic exchanges between human and AI agent wherein feedback is provided in an online manner, a few at a time. In this paper, we introduce a new framework to train summarization models with preference feedback interactively. By properly leveraging offline data and a novel reward model, we improve the performance regarding ROUGE scores and sample-efficiency. Our experiments on three various datasets confirm the benefit of the proposed framework in active, few-shot and online settings of preference learning.
Robust Deep Reinforcement Learning for Extractive Legal Summarization
Nov 23, 2021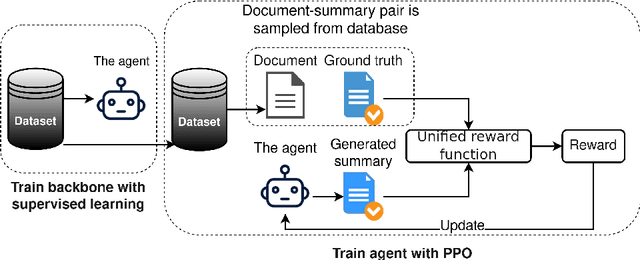
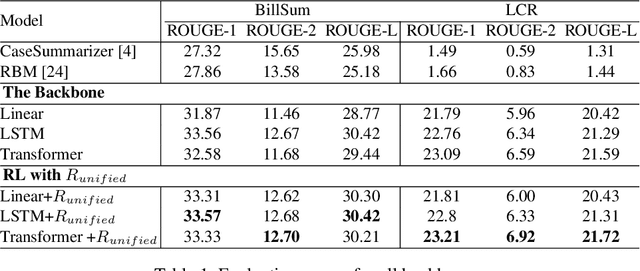
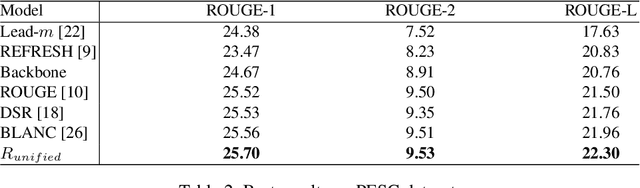

Automatic summarization of legal texts is an important and still a challenging task since legal documents are often long and complicated with unusual structures and styles. Recent advances of deep models trained end-to-end with differentiable losses can well-summarize natural text, yet when applied to legal domain, they show limited results. In this paper, we propose to use reinforcement learning to train current deep summarization models to improve their performance on the legal domain. To this end, we adopt proximal policy optimization methods and introduce novel reward functions that encourage the generation of candidate summaries satisfying both lexical and semantic criteria. We apply our method to training different summarization backbones and observe a consistent and significant performance gain across 3 public legal datasets.